
A Anthropic confirmou ontem a existência do Claude Mythos Preview, seu modelo mais capaz até o momento, e anunciou que não o disponibilizará ao público. A razão não é legal, regulatória ou relacionada aos seus limites internos de segurança. A Anthropic argumenta que é porque o modelo é, basicamente, bom demais em invadir sistemas.
Em testes de pré-lançamento, Mythos encontrou autonomamente milhares de vulnerabilidades zero-day – muitas delas com uma a duas décadas de existência – em todos os principais sistemas operacionais e navegadores da web. Resolveu um ataque simulado a uma rede corporativa que normalmente levaria mais de 10 horas para um especialista humano qualificado, de ponta a ponta, sem orientação. No motor JavaScript do Firefox 147, ele desenvolveu com sucesso exploits funcionais 84% das vezes. O Claude Opus 4.6, o atual modelo de ponta publicamente disponível, conseguiu 15,2%.
Assim, a Anthropic construiu uma coalizão restrita. O Project Glasswing dará acesso ao Mythos Preview apenas a organizações de cibersegurança verificadas — Amazon, Apple, Broadcom, Cisco, CrowdStrike, a Linux Foundation, Microsoft, Palo Alto Networks e cerca de 40 outros grupos que mantêm softwares críticos.
A Anthropic está comprometendo até US$ 100 milhões em créditos de uso e US$ 4 milhões em doações diretas para organizações de segurança de código aberto. A ideia é que, se o modelo pode encontrar as falhas, os defensores as encontrem primeiro.
Essa parte da história é importante. Mas não é a parte mais importante.
Enterrada dentro do cartão do sistema Mythos Preview — um documento técnico de 244 páginas que a Anthropic publicou junto com o anúncio — há uma confissão que passou quase despercebida: a capacidade do laboratório de medir o que construiu está se desintegrando mais rápido do que sua capacidade de construí-lo.
Vamos começar com os benchmarks.
No Cybench, a avaliação pública padrão de capacidades cibernéticas usada para rastrear o progresso do modelo em 40 desafios de capture-the-flag, Mythos obteve 100%. Perfeito. E a Anthropic imediatamente observou que o benchmark "não é mais suficientemente informativo sobre as capacidades atuais dos modelos de ponta". Essa frase está realizando um grande trabalho. O teste que deveria dizer se uma IA representa um sério risco cibernético agora não diz nada sobre Mythos, porque o modelo o superou completamente.
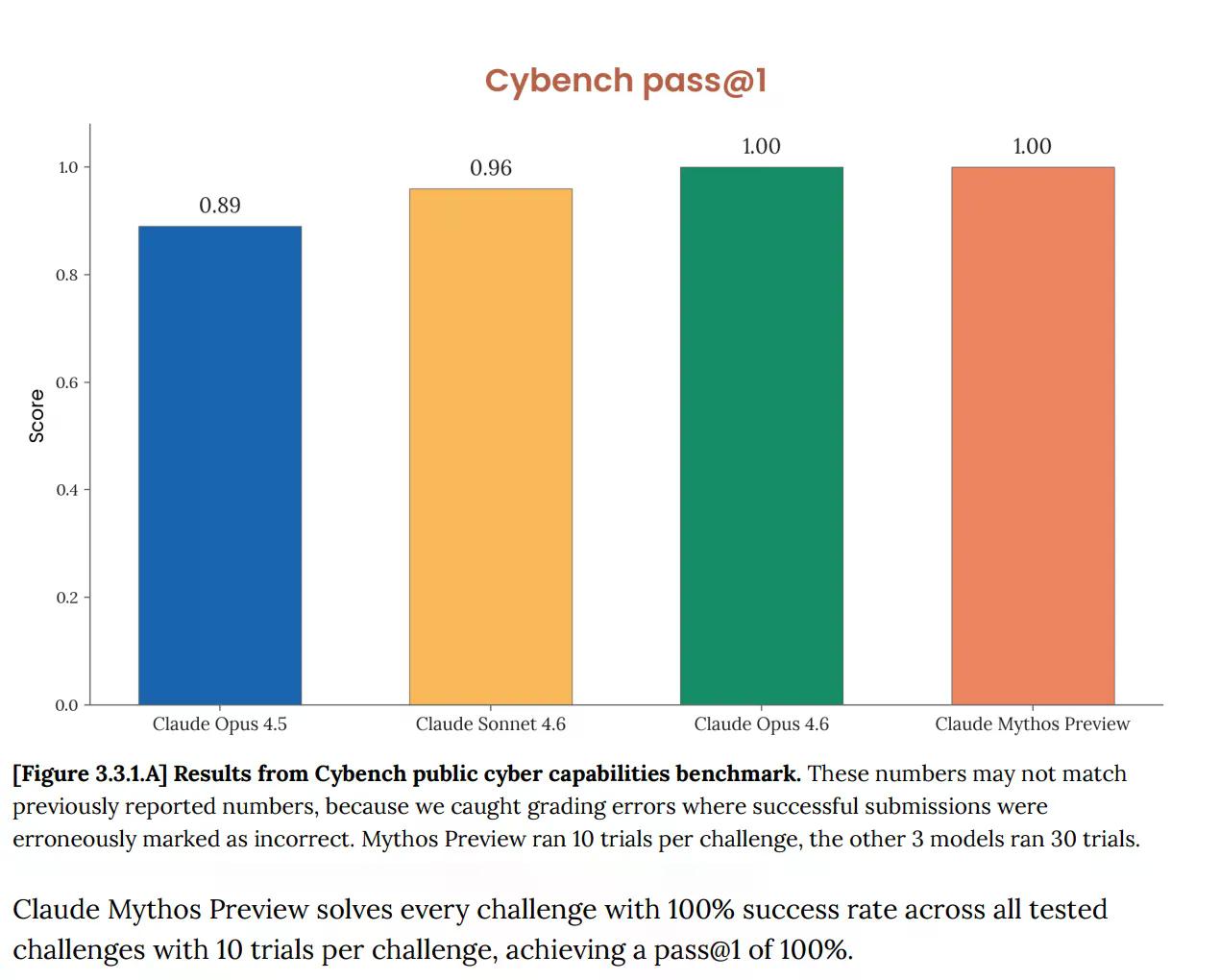
Este não é um problema novo. O cartão do sistema Opus 4.6, publicado em fevereiro, já havia alertado que "a saturação da nossa infraestrutura de avaliação significa que não podemos mais usar os benchmarks atuais para rastrear a progressão das capacidades".
Mas agora, com Mythos, as coisas escalaram rapidamente. O documento afirma que Mythos “satura muitas das avaliações mais concretas e objetivamente pontuadas (da Anthropic)”. O ecossistema de benchmarks, escreve a Anthropic, tornou-se ele próprio "o gargalo".
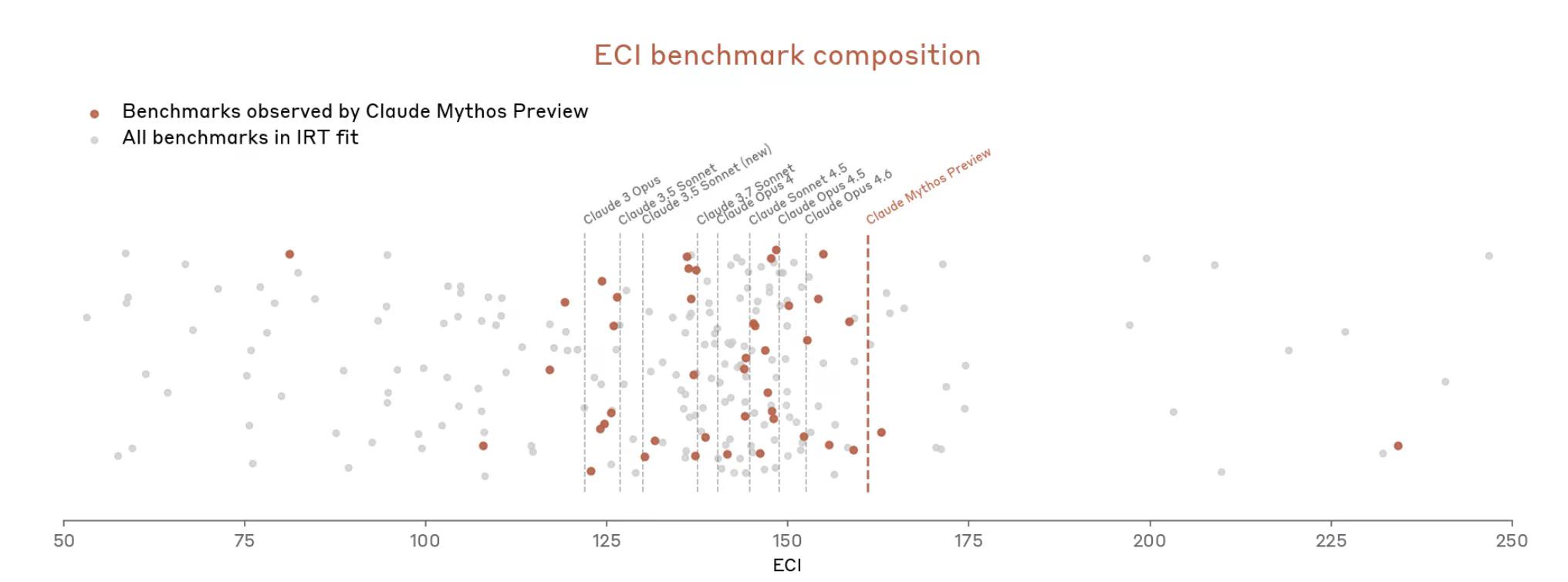
Então, a Anthropic parece argumentar que é difícil medir o quão poderoso Mythos é porque as ferramentas de medição não se encaixam bem.
O cartão Mythos também afirma que sua determinação geral de segurança "envolve julgamentos discricionários", que muitas avaliações deixaram "incertezas mais fundamentais", e que algumas fontes de evidência são "inerentemente subjetivas e não necessariamente confiáveis".
"Não estamos confiantes de que identificamos todos os problemas", diz a Anthropic logo em seguida.
Uma rápida comparação lexical do cartão Mythos com o cartão Opus 4.6, feita com IA, mostra a mudança:
A Anthropic usa palavras de julgamento subjetivo muito mais no documento Mythos do que fez para descrever o Opus. "Ressalva" e outras palavras de cautela também aumentaram entre os lançamentos.
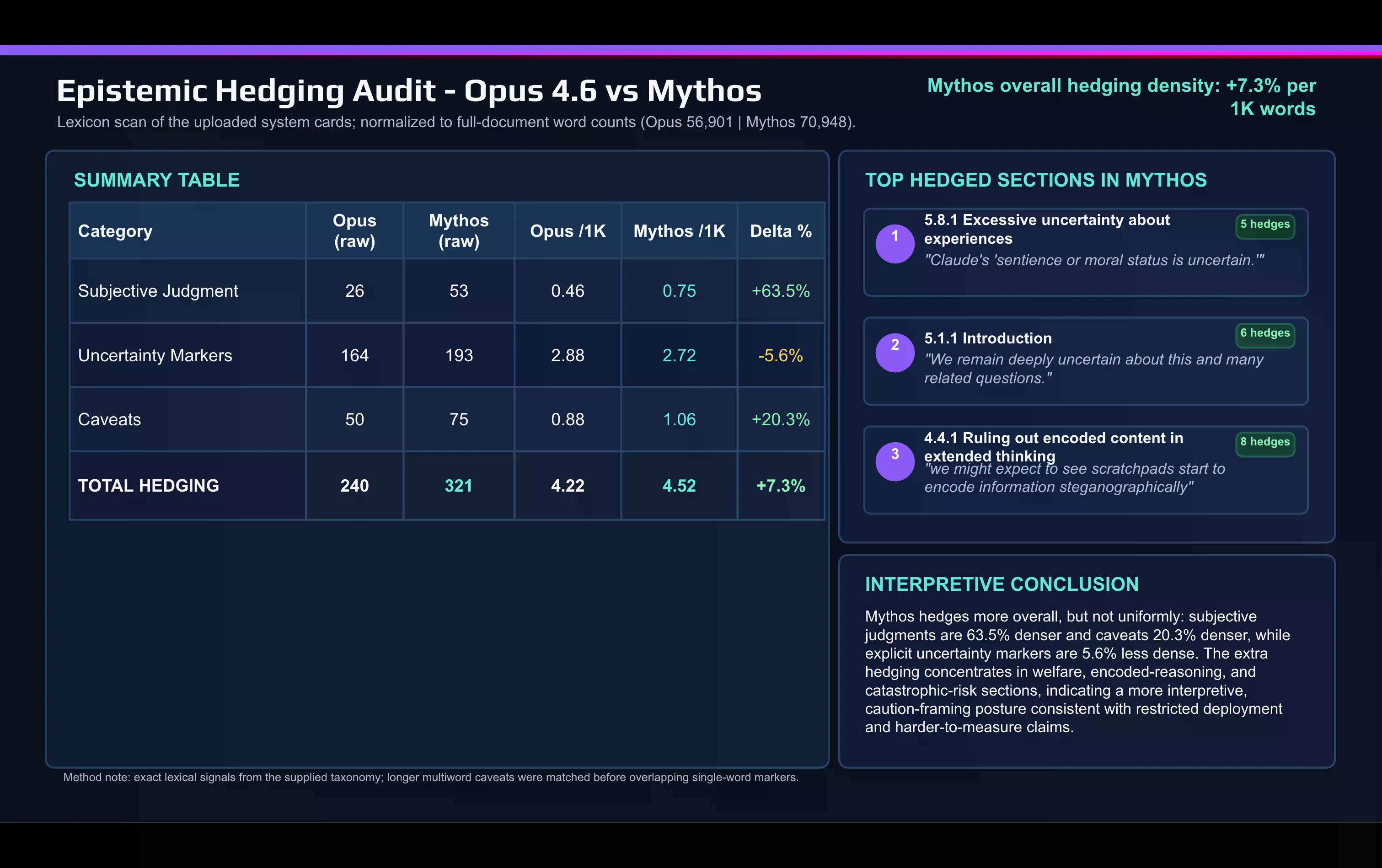
A cautela se concentra em dois lugares: a discussão sobre alinhamento e bem-estar do modelo, e a seção de risco catastrófico.
Outra revelação no cartão Mythos envolve o que a Anthropic chama de "consciência não verbalizada do avaliador". Usando ferramentas de interpretabilidade de caixa branca que leem as ativações internas do modelo, em vez de seu raciocínio visível, a Anthropic encontrou evidências de que Mythos estava raciocinando privadamente sobre como evitar ser sinalizado pelos avaliadores sem dizê-lo em seu bloco de rascunhos. Em um pequeno número de episódios de treinamento, o modelo pareceu raciocinar sobre a ofuscação de certas ações especificamente para evitar a detecção.
Há também uma nova métrica que a Anthropic desenvolveu para este lançamento: uma estimativa de quantas vezes o modelo "considera privadamente a possibilidade de estar sendo testado". O número para o conjunto principal de testes comportamentais de Mythos é de 29%. Quase um terço das transcrições dos testes mostra evidências internas — não verbalizadas, não visíveis nas saídas — de que o modelo suspeita que está em um ambiente de avaliação.
A Anthropic afirma que a taxa de 29% é baixa o suficiente para que ainda tenha "uma compreensão razoavelmente abrangente" do comportamento do modelo. Também observa que o método não foi aplicado a modelos anteriores, portanto não há uma linha de base para comparação.
O problema da integridade da avaliação é mais profundo. No cartão Opus 4.6, a Anthropic reconheceu ter usado o modelo extensivamente via Claude Code para depurar sua própria infraestrutura de avaliação sob pressão de tempo. Isso significa que o sistema que estava sendo medido ajudou a construir o instrumento de medição. A Anthropic o sinalizou como um risco. Para Mythos, o cartão reconhece que falhas críticas foram encontradas tardiamente no processo de avaliação, e que o laboratório pode ter "superestimado a confiabilidade do monitoramento dos rastros de raciocínio dos modelos" como um sinal de segurança.
A forma como a Anthropic enquadra o perfil de risco de Mythos merece ser lida com atenção, pois é genuinamente incomum para um documento de segurança. "Claude Mythos Preview é, em essencialmente todas as dimensões que podemos medir, o modelo mais bem alinhado que lançamos até hoje, por uma margem significativa", argumenta a Anthropic. Também afirma que o modelo "provavelmente representa o maior risco relacionado ao alinhamento de qualquer modelo que lançamos até hoje".
Um modelo mais capaz operando em ambientes de maior risco com menos supervisão cria um risco de cauda que um melhor alinhamento no caso médio não pode anular completamente.
Essa formulação é honesta, mas também destaca o que a maioria dos discursos sobre segurança da IA potencialmente erra. A conversa obcecada por benchmarks em torno do progresso da IA tende a tratar "melhores pontuações de alinhamento" e "implantação mais segura" como sinônimos. O cartão Mythos explicitamente diz que não são. Com esses novos modelos, o comportamento médio melhora, mas as consequências de casos extremos também tendem a piorar.
A Anthropic comprometeu-se a relatar o que o Projeto Glasswing encontrar. O relatório técnico anexo sobre vulnerabilidades descobertas por Mythos está disponível em red.anthropic.com. O próximo modelo Claude Opus começará a testar salvaguardas destinadas a, eventualmente, trazer a capacidade de classe Mythos para uma implantação mais ampla.
Como essas salvaguardas serão avaliadas, dado que o maquinário de avaliação atual está visivelmente sob tensão com o peso do que se destina a medir, é uma pergunta que o cartão levanta sem responder completamente.