
L'argument des assistants personnels IA a toujours été le même : donnez à l'agent l'accès à votre vie numérique et il s'occupe du reste. Vos e-mails, votre calendrier, vos notes, vos appareils — tout cela. Votre IA sait. Votre IA agit. Vous dormez.
Des chercheurs de Huawei Technologies, de l'Institut de Technologie de Pékin, de l'Université de Pékin et de l'Académie Chinoise des Sciences viennent de créer un benchmark pour vérifier si c'était réellement vrai. Spoiler : ce n'est pas le cas.
Claw-Anything évalue les agents IA simultanément sur trois dimensions : des flux d'événements à long terme couvrant plus de trois mois d'activité utilisateur simulée, des services backend interdépendants (en moyenne 10,1 par tâche), et l'interaction multi-appareils à travers des environnements CLI Linux et des environnements GUI Android.
La fenêtre contextuelle moyenne par tâche est de 191 700 mots. La plupart des benchmarks existants se situent entre 1 700 et 12 000. Ce n'est pas un petit écart, mais un problème entièrement différent. C'est aussi ce à quoi ressemble la vie réelle, par opposition aux benchmarks standardisés ultra spécifiques.
Votre IA n'a aucune idée de ce qui se passe
Le benchmark est évalué sur le pass@1 — la probabilité que l'agent accomplisse une tâche correctement du premier coup, sans rattrapage. Une tâche pourrait demander à l'agent de recouper une alerte de prix sur un produit qu'il a trouvé il y a des semaines, de vérifier le calendrier de l'utilisateur pour un rendez-vous pertinent, et d'agir sur les deux depuis un téléphone. Une autre pourrait lui demander de récupérer des travaux récents à partir de notes, de fils d'e-mails et de Slack, puis de produire une présentation à partir de zéro.
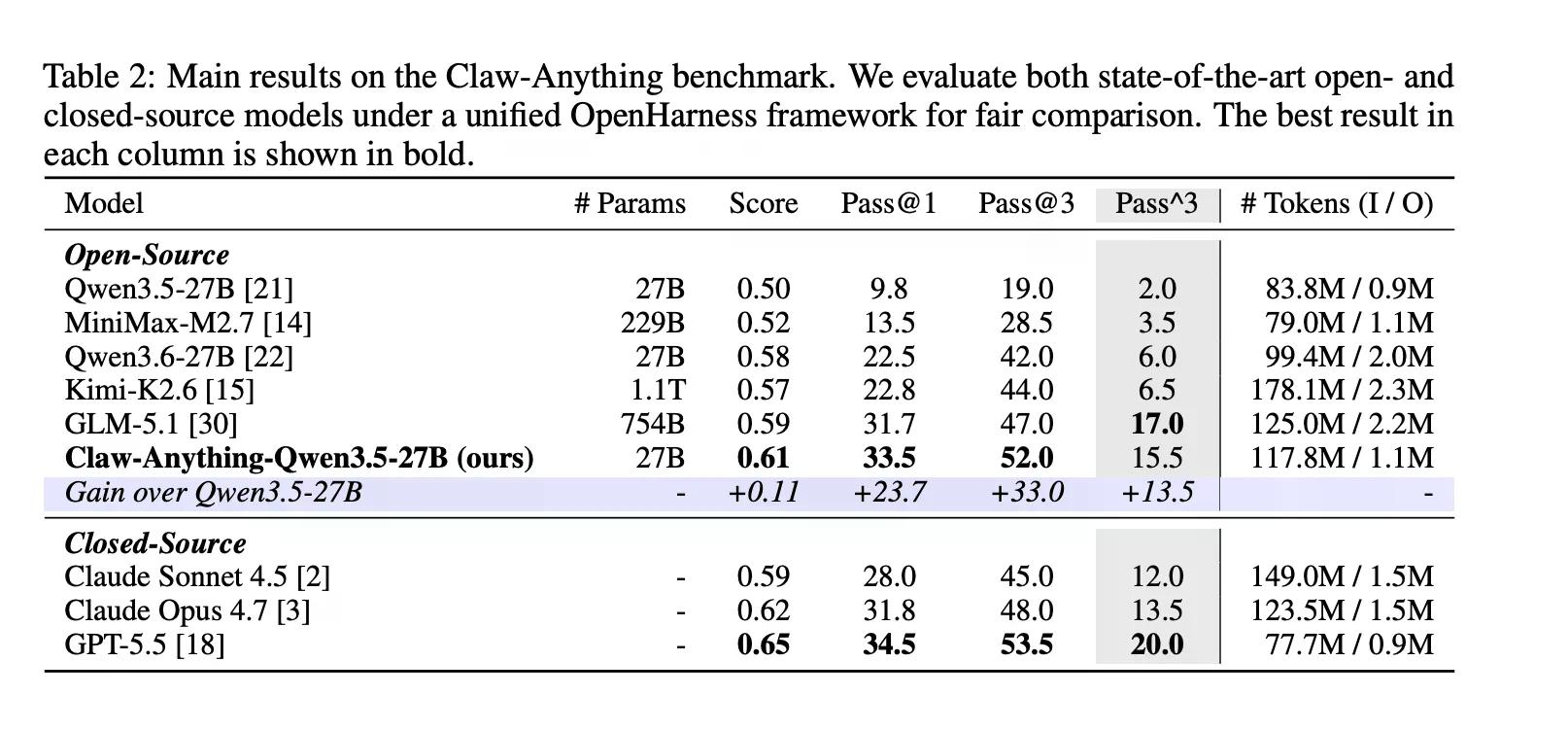
Ce sont des choses que les gens demandent réellement aux assistants de faire. Il s'avère que l'IA n'est pas très douée pour cela. GPT-5.5, selon la couverture précédente de Decrypt, est le meilleur modèle d'OpenAI, conçu pour des tâches agéntiques à long terme. Il a obtenu un score de 34,5 %.
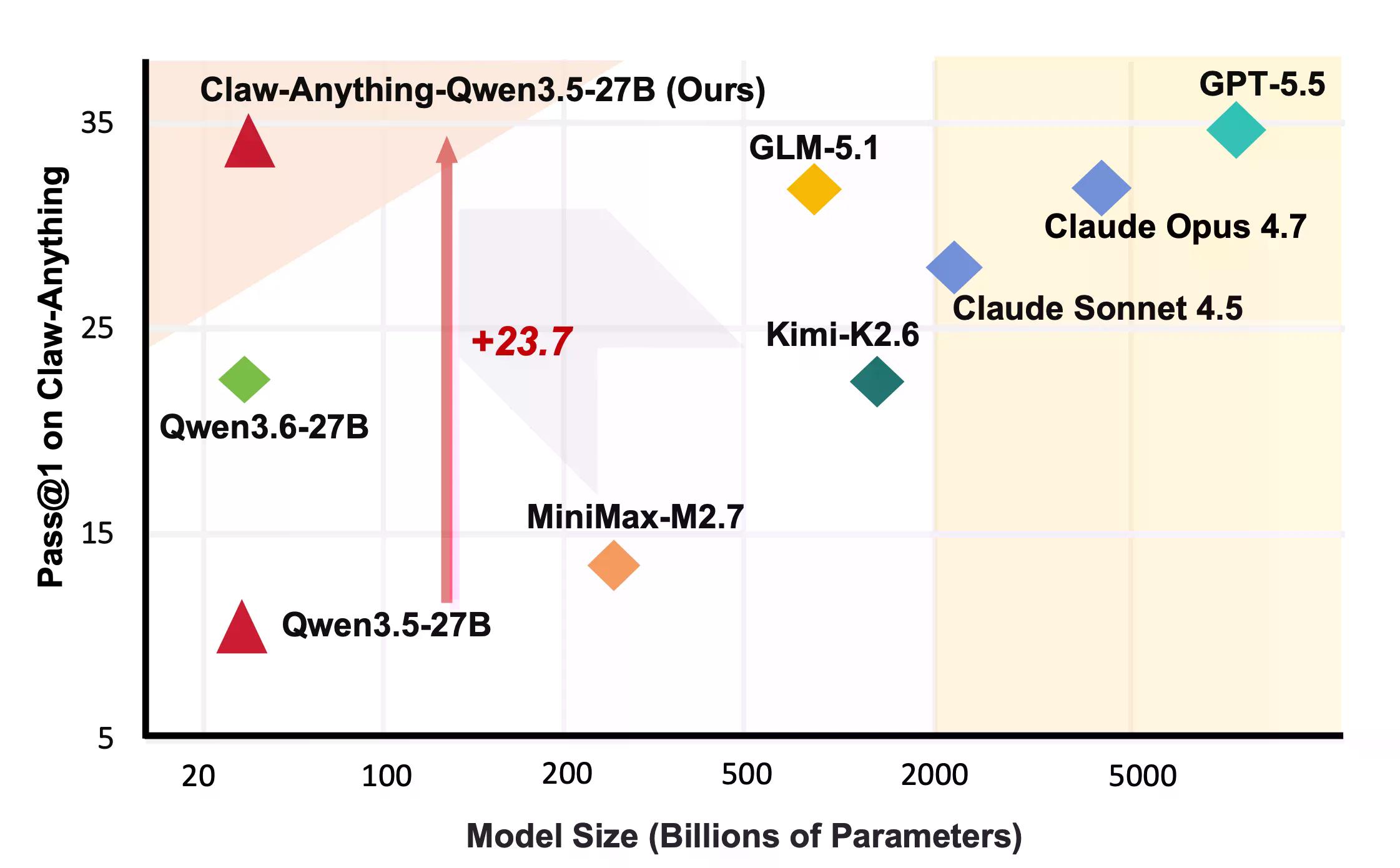
"Les modèles actuels restent peu fiables même lorsqu'on leur donne un accès plus large au monde numérique de l'utilisateur", indique le document Claw-Anything. Plusieurs modèles qui semblaient impressionnants sur d'autres benchmarks ont chuté encore davantage.
Le benchmark évalue également l'assistance proactive séparément, c'est-à-dire les cas où l'agent détecte un besoin et agit sans y être invité. La plupart des benchmarks ne testent pas cela. Claw-Anything le fait, et l'écart est frappant : les agents ont obtenu un score de 25,9 % sur les tâches réactives et de seulement 6,7 % sur les tâches proactives.
Pourquoi la plupart des benchmarks ne vous disent pas cela
Les chercheurs avancent un argument pertinent : les benchmarks existants traitent les agents IA comme des solveurs de tâches posés sur un bureau propre. Claw-Anything les traite comme des assistants personnels plongés dans une vie réelle désordonnée – événements non pertinents, signaux contradictoires, mois de bruit accumulé. L'agent doit déterminer ce qui est pertinent avant de pouvoir faire quoi que ce soit d'utile.
Les résultats d'ablation clarifient particulièrement la dépendance multiservices. Lorsque les outils nécessaires aux tâches inter-services ont été supprimés, les taux de réussite sont tombés à presque zéro, car la plupart des tâches exigent des agents qu'ils récupèrent des informations et agissent sur plusieurs backends plutôt que sur un seul.
Ce n'est pas un nouveau genre de problème dans l'évaluation de l'IA. OpenAI a déclaré SWE-bench contaminé plus tôt cette année après que les scores soient passés d'environ 70 % à 23 % sur une version moins sujette aux fuites. Il s'agissait d'hygiène des données. Il s'agit ici de quelque chose de plus fondamental — si les benchmarks posent même la bonne question.
Du côté constructif, l'équipe a publié le pipeline qui a généré le benchmark ainsi que 2 000 environnements d'entraînement. Le réglage fin de Qwen3.5-27B sur 1 500 trajectoires d'agents réussies a amélioré le pass@1 de 23,7 % — suffisamment pour battre plusieurs modèles propriétaires sur le classement, y compris Claude Sonnet.
Les chercheurs identifient la coordination inter-services comme le principal défi restant du benchmark pour le domaine. L'ensemble de données est disponible sur Hugging Face et le code sur GitHub.
