
Si Jensen Huang, CEO ng Nvidia, ay naging panauhin sa podcast ni Lex Fridman noong nakaraang linggo at tahasang sinabi, "Sa tingin ko, naabot na natin ang AGI." Makalipas ang dalawang araw, inilabas ng pinakamahigpit na pagsubok sa pananaliksik ng AI ang pinakabago nitong benchmark para sa artificial general intelligence—at lahat ng frontier model ay nakakuha ng mas mababa sa 1%.
Inilabas ng ARC Prize Foundation ang ARC-AGI-3 ngayong linggo, at ang mga resulta ay malupit. Nanguna ang Gemini 3.1 Pro ng Google sa 0.37%. Sumunod ang GPT-5.4 ng OpenAI sa 0.26%. Naabot ng Claude Opus 4.6 ng Anthropic ang 0.25%, habang ang Grok-4.20 ng xAI ay nakakuha ng eksaktong sero. Samantala, nalutas ng mga tao ang 100% ng mga kapaligiran.
Hindi ito isang trivia test o coding exam, o kahit na napakahirap na mga tanong sa PhD-level. Ang ARC-AGI-3 ay ganap na naiiba sa anumang kinaharap ng industriya ng AI noon.
Ang benchmark ay binuo ng foundation nina François Chollet at Mike Knoop, na nagtayo ng in-house game studio at lumikha ng 135 orihinal na interactive na kapaligiran mula sa simula. Ang ideya ay ilagay ang isang AI agent sa isang hindi pamilyar na mundong parang laro na walang tagubilin, walang nakasaad na layunin, at walang paglalarawan ng mga panuntunan. Kailangang tuklasin ng agent, alamin kung ano ang dapat nitong gawin, bumuo ng isang plano, at isagawa ito.
Kung ito ay parang isang bagay na kayang gawin ng isang limang taong gulang, nagsisimula ka nang maunawaan ang problema. Kung gusto mong makita kung mas mahusay ka kaysa sa AI, maaari mong laruin ang parehong mga laro na itinampok sa pagsubok sa pamamagitan ng pag-click sa link na ito. Sinubukan namin ang isa; kakaiba ito sa simula, ngunit pagkatapos ng ilang segundo, madali mo itong matututunan.
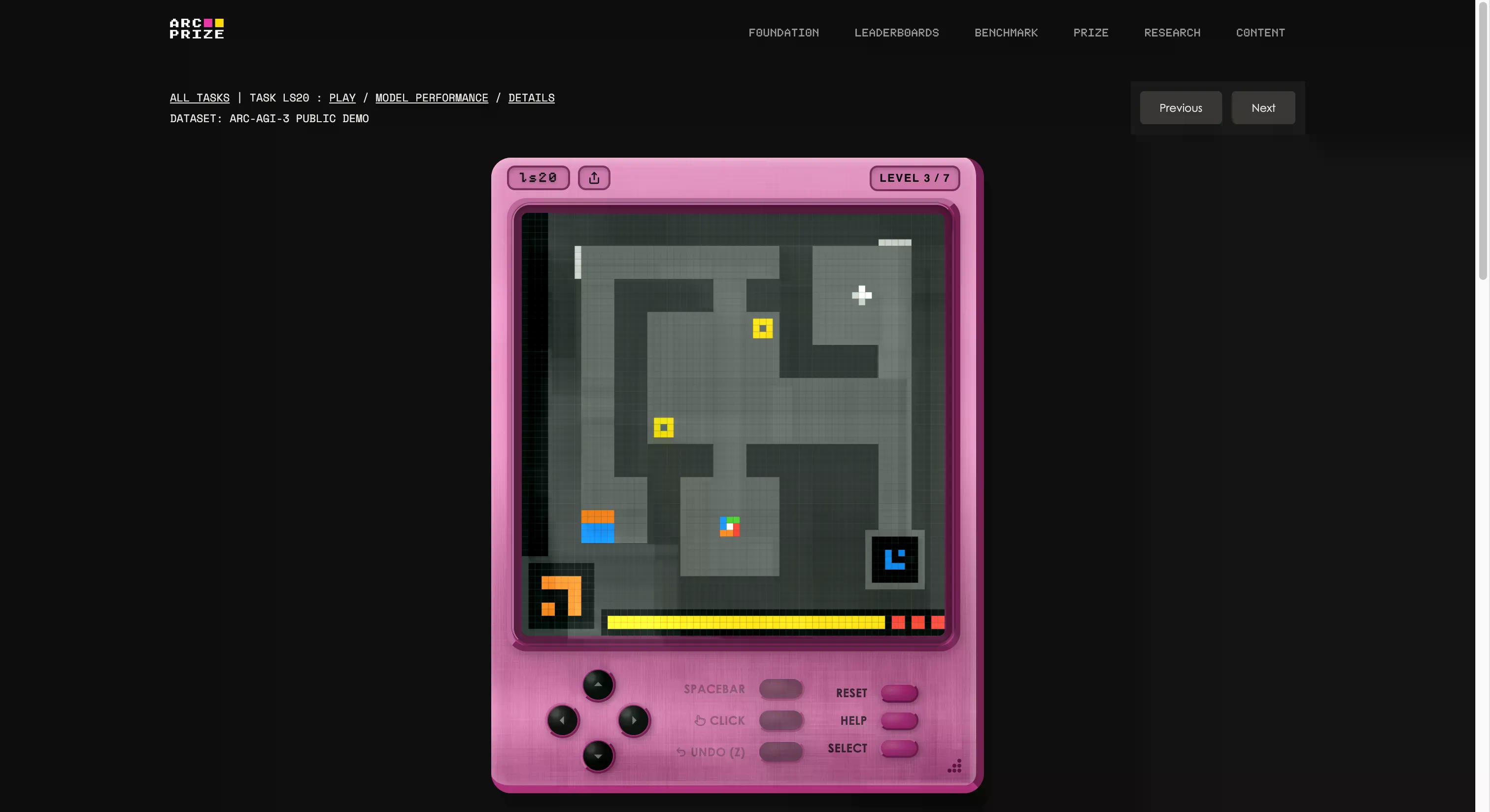
Ito rin ang pinakamalinaw na halimbawa kung ano ang ibig sabihin ng "G" sa AGI. Kapag naglalahat ka, nakakagawa ka ng bagong kaalaman (kung paano gumagana ang isang kakaibang laro) nang hindi ka sinanay dito nang maaga.
Ang mga nakaraang bersyon ng ARC ay sumubok ng mga static na visual na puzzle—ipakita ang isang pattern, hulaan ang susunod. Mahirap ang mga ito sa simula. Pagkatapos ay inilagay ng mga lab ang compute power at pagsasanay sa mga ito hanggang sa mamatay ang mga benchmark. Ang ARC-AGI-1, na ipinakilala noong 2019, ay bumagsak sa test-time training at reasoning models. Ang ARC-AGI-2 ay tumagal ng halos isang taon bago naabot ng Gemini 3.1 Pro ang 77.1%. Mahusay ang mga lab sa pagpuwersa sa mga benchmark na maaari nilang sanayin.
Ang Bersyon 3 ay partikular na idinisenyo upang maiwasan iyon. Sa 110 sa 135 na kapaligiran na pinananatiling pribado—55 semi-pribado para sa pagsubok ng API, 55 na ganap na naka-lock para sa kompetisyon—walang dataset na isaulo. Hindi mo puwedeng puwersahin ang iyong sarili sa pamamagitan ng bagong lohika ng laro na hindi mo pa nakikita.
Hindi rin pass/fail ang pagmamarka. Gumagamit ang ARC-AGI-3 ng tinatawag ng foundation na RHAE—Relative Human Action Efficiency. Ang baseline ay ang pangalawang pinakamahusay, unang takbo ng pagganap ng tao. Isang AI na gumagawa ng sampung beses na mas maraming aksyon kaysa sa isang tao ay nakakakuha ng 1% para sa antas na iyon, hindi 10%. Sinusuklay ng formula ang parusa para sa kawalang-kahusayan. Ang paggala-gala, pagbabalik-tanaw, at paghula sa sagot ay mahigpit na pinarusahan.
Ang pinakamahusay na AI agent sa buong-buwan na developer preview ay nakakuha ng 12.58%. Ang mga frontier LLM na sinubukan sa pamamagitan ng opisyal na API, nang walang custom tooling, ay hindi umabot sa 1%. Nalutas ng mga ordinaryong tao ang lahat ng 135 na kapaligiran nang walang paunang pagsasanay at walang tagubilin. Kung iyon ang pamantayan, kung gayon ang kasalukuyang hanay ng mga modelo ay hindi ito nakakaya.
Mayroong isang tunay na metodolohikal na debate dito. Sinasabi ng ulat ng ARC na ang isang custom harness na binuo ng Duke ay nagtulak sa Claude Opus 4.6 mula 0.25% hanggang 97.1% sa isang solong variant ng kapaligiran na tinatawag na TR87. Hindi ibig sabihin nito na nakakuha si Claude ng 97.1% sa ARC-AGI-3 sa kabuuan; nanatili ang opisyal na score nito sa 0.25%, ngunit ang pagbabago ay kapansin-pansin pa rin.
Ang opisyal na benchmark ay nagbibigay sa mga ahente ng JSON code, hindi visuals. Maaaring ito ay isang kapintasan sa metodolohiya o isang demonstrasyon na mas mahusay ang mga modelo ngayon sa pagproseso ng impormasyong madaling intindihin ng tao kaysa sa raw structured data. Kinilala ng foundation ni Chollet ang debate, ngunit hindi nila binabago ang format.
“Ang pagdama sa nilalaman ng frame at ang format ng API ay hindi naglilimita sa pagganap ng mga frontier model sa ARC-AGI-3,” ayon sa papel. Sa madaling salita, tila tinatanggihan nila ang ideya na ang mga modelo ay nabigo dahil hindi nila 'nakikita' nang maayos ang mga gawain, sa halip ay ipinaglalaban na sapat na ang pagdama—at ang tunay na agwat ay nasa pangangatwiran at paglalahat.
Dumating ang AGI reality check sa isang linggo kung kailan ang 'hype machine' ay tumatakbo nang buong bilis. Bukod sa komento ni Huang, pinangalanan ng Arm ang bago nitong data center chip na "AGI CPU." Sinabi ni Sam Altman ng OpenAI na "karaniwang nakabuo na sila ng AGI," at ang Microsoft ay nagbebenta na ng isang lab na nakatuon sa pagbuo ng ASI: Isang ebolusyon ng kung ano ang susunod pagkatapos maabot ang AGI. Ang termino ay pinalalawak hanggang sa ito ay mangahulugan ng anumang komersyal na maginhawa, tila.
Ang posisyon ni Chollet ay mas simple. Kung kayang gawin ng isang ordinaryong tao nang walang tagubilin, at hindi kayang gawin ng iyong sistema, kung gayon wala kang AGI—mayroon kang napakamahal na autocomplete na nangangailangan ng maraming tulong.
Nag-aalok ang ARC Prize 2026 ng $2 milyon sa tatlong track ng kompetisyon, lahat ay naka-host sa Kaggle. Ang bawat nanalong solusyon ay dapat na open-sourced. Tumatakbo ang orasan, at sa ngayon, malayo pa ang mga makina.