
Kinumpirma ng Anthropic ang pag-iral ng Claude Mythos Preview kahapon, ang pinakamakapangyarihang modelo nito sa kasalukuyan, at inanunsyo na hindi ito ipapamahagi sa publiko. Ang dahilan ay hindi legal, regulasyon, o nauugnay sa panloob na mga threshold ng kaligtasan nito. Ipinagtatanggol ng Anthropic na ito ay dahil ang modelo ay, sa esensya, napakahusay sa pagpasok sa mga sistema.
Sa pre-release testing, awtonomong nakahanap ang Mythos ng libu-libong zero-day vulnerabilities—marami sa mga ito ay isa hanggang dalawang dekada nang luma—sa bawat pangunahing operating system at bawat pangunahing web browser. Nalutas nito ang isang simulate na corporate network attack na karaniwang tatagal ng higit sa 10 oras para sa isang bihasang eksperto, end-to-end, nang walang gabay. Sa JavaScript engine ng Firefox 147, matagumpay nitong nakabuo ng gumaganang mga exploit sa 84% ng mga pagkakataon. Ang Claude Opus 4.6, ang kasalukuyang available sa publiko na frontier model, ay nakapamahala ng 15.2%.
Kaya bumuo ang Anthropic ng isang restricted coalition. Bibigyan ng Project Glasswing ng access sa Mythos Preview ang mga vetted na organisasyon ng cybersecurity—Amazon, Apple, Broadcom, Cisco, CrowdStrike, the Linux Foundation, Microsoft, Palo Alto Networks, at humigit-kumulang 40 iba pang grupo na nagpapanatili ng kritikal na software.
Nangangako ang Anthropic ng hanggang $100 milyon sa usage credits at $4 milyon sa direktang donasyon sa mga open-source security organization. Ang ideya ay kung kaya ng modelo na makahanap ng mga butas, hayaan ang mga tagapagtanggol na mahanap muna ang mga ito.
Ang bahaging iyon ng kwento ay mahalaga. Ngunit hindi iyon ang pinakamahalagang bahagi.
Nakalibing sa loob ng Mythos Preview system card—isang 244-pahinang teknikal na dokumento na inilabas ng Anthropic kasabay ng anunsyo—ay isang pag-amin na halos hindi napansin: Ang kakayahan ng lab na sukatin ang binuo nito ay mas mabilis na nauubos kaysa sa kakayahan nitong bumuo.
Magsimula tayo sa mga benchmark.
Sa Cybench, ang standard public cyber capabilities evaluation na ginagamit upang subaybayan ang pag-unlad ng modelo sa 40 capture-the-flag challenges, nakakuha ang Mythos ng 100%. Perpekto. At agad na sinabi ng Anthropic na ang benchmark "ay hindi na sapat na nagbibigay-impormasyon tungkol sa kasalukuyang kakayahan ng frontier model." Malaking trabaho ang ginagawa ng pangungusap na iyan. Ang test na dapat magsasabi sa iyo kung ang isang AI ay nagdudulot ng seryosong cyber risk ay wala nang sinasabi tungkol sa Mythos, dahil ganap na itong nalampasan ng modelo.
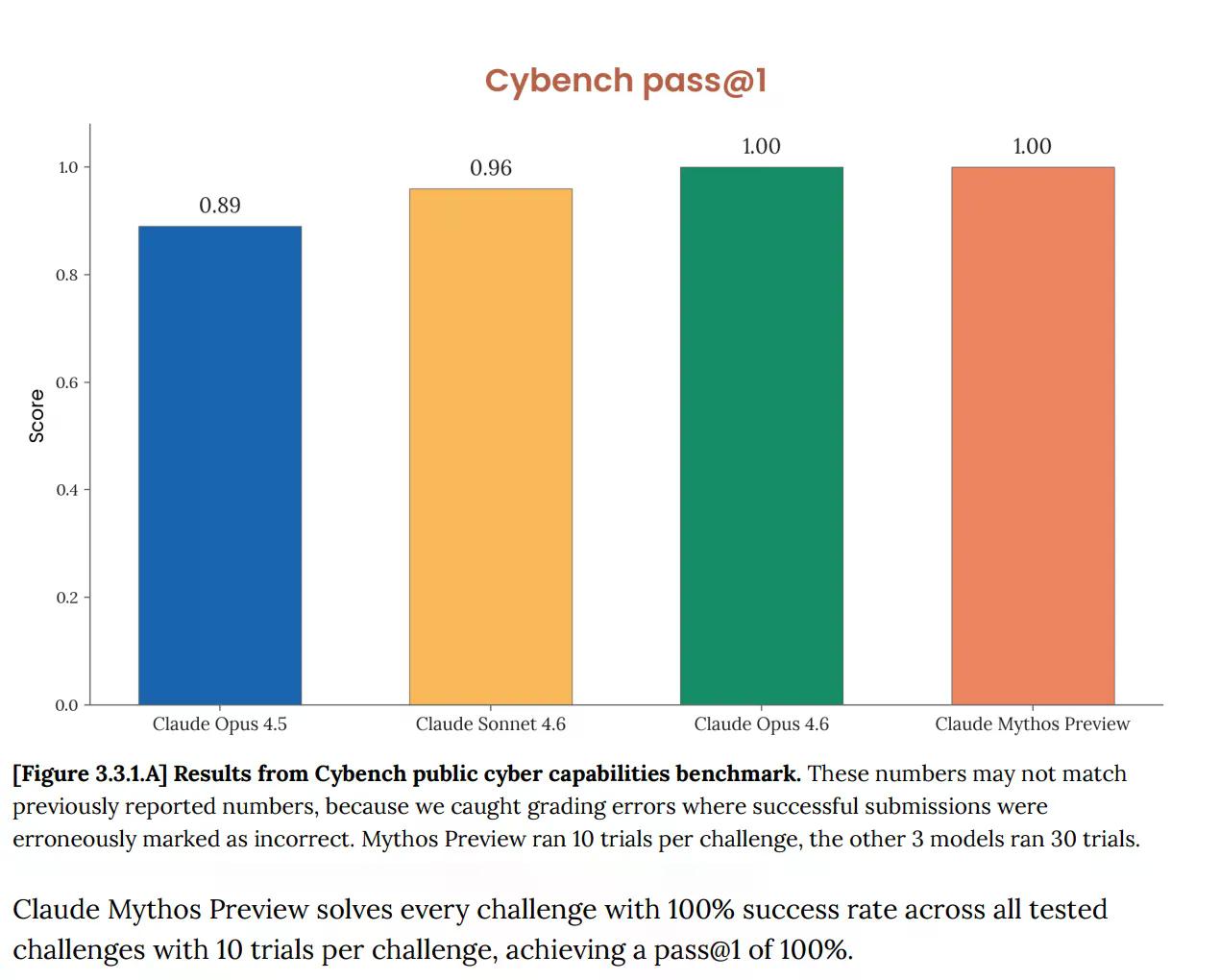
Hindi ito isang bagong problema. Ang Opus 4.6 system card, na inilabas noong Pebrero, ay nagbabala na "ang pagkababad ng aming evaluation infrastructure ay nangangahulugang hindi na namin magagamit ang kasalukuyang mga benchmark upang subaybayan ang pag-unlad ng kakayahan."
Ngunit ngayon sa Mythos, mabilis na lumala ang sitwasyon. Sinasabi ng dokumento na ang Mythos ay “nagpapababad ng marami sa mga pinakakonkreto, objectively-scored na evaluation ng (Anthropic).” Ang benchmark ecosystem, ayon sa Anthropic, ay ngayon mismo "ang bottleneck."
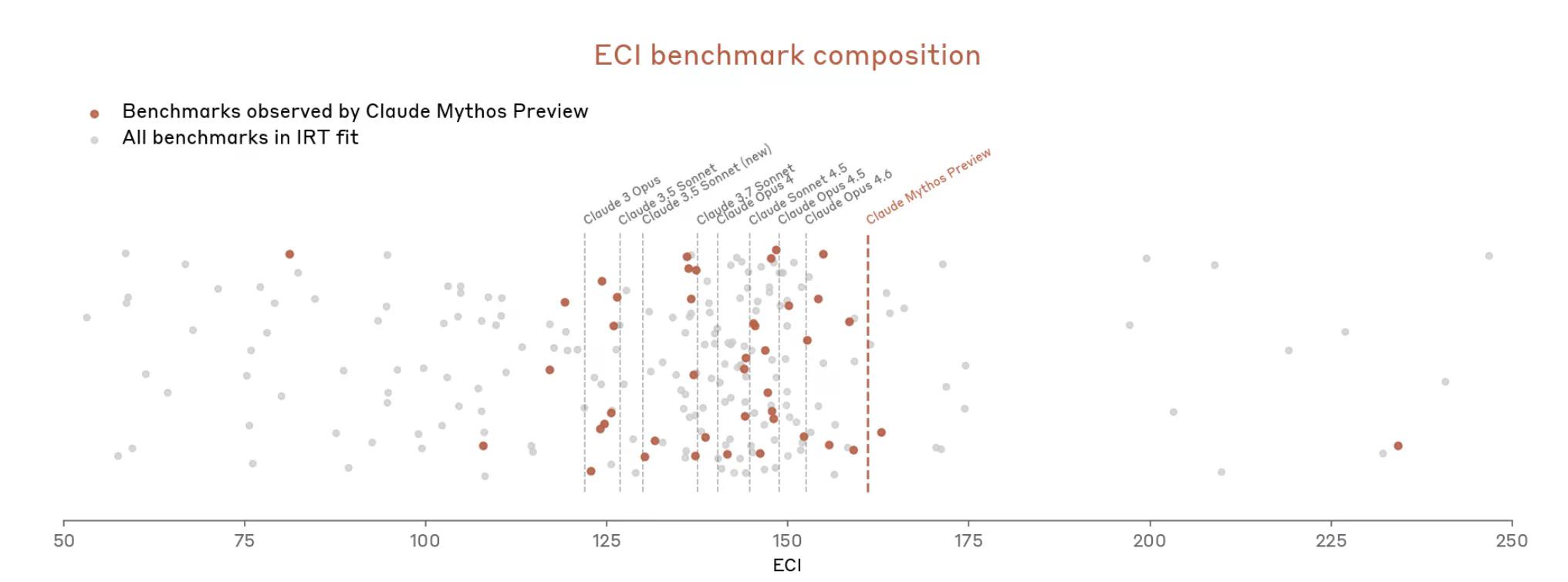
Kaya, tila nakikipagtalo ang Anthropic na mahirap sukatin kung gaano kalakas ang Mythos dahil hindi akma ang mga tool sa pagsukat.
Sinasabi din ng Mythos card na ang pangkalahatang pagtukoy nito sa kaligtasan ay "nagsasangkot ng mga paghuhusga," na maraming pagsusuri ang nag-iwan ng "mas pundamental na kawalan ng katiyakan," at na ang ilang pinagmulan ng ebidensya ay "likas na subhetibo, at hindi kinakailangang mapagkakatiwalaan."
"Hindi kami kumpyansa na natukoy namin ang lahat ng isyu," sabi ng Anthropic pagkatapos nito.
Ang mabilis na lexical comparison ng Mythos card laban sa Opus 4.6 card na ginawa gamit ang AI ay nagpapakita ng pagbabago:
Mas madalas ginagamit ng Anthropic ang mga salitang nagpapahayag ng subhetibong paghuhusga sa dokumento ng Mythos kaysa sa paglalarawan nito sa Opus. Tumaas din ang "Caveat" at iba pang nagpapahayag ng pag-iingat sa pagitan ng mga paglabas.
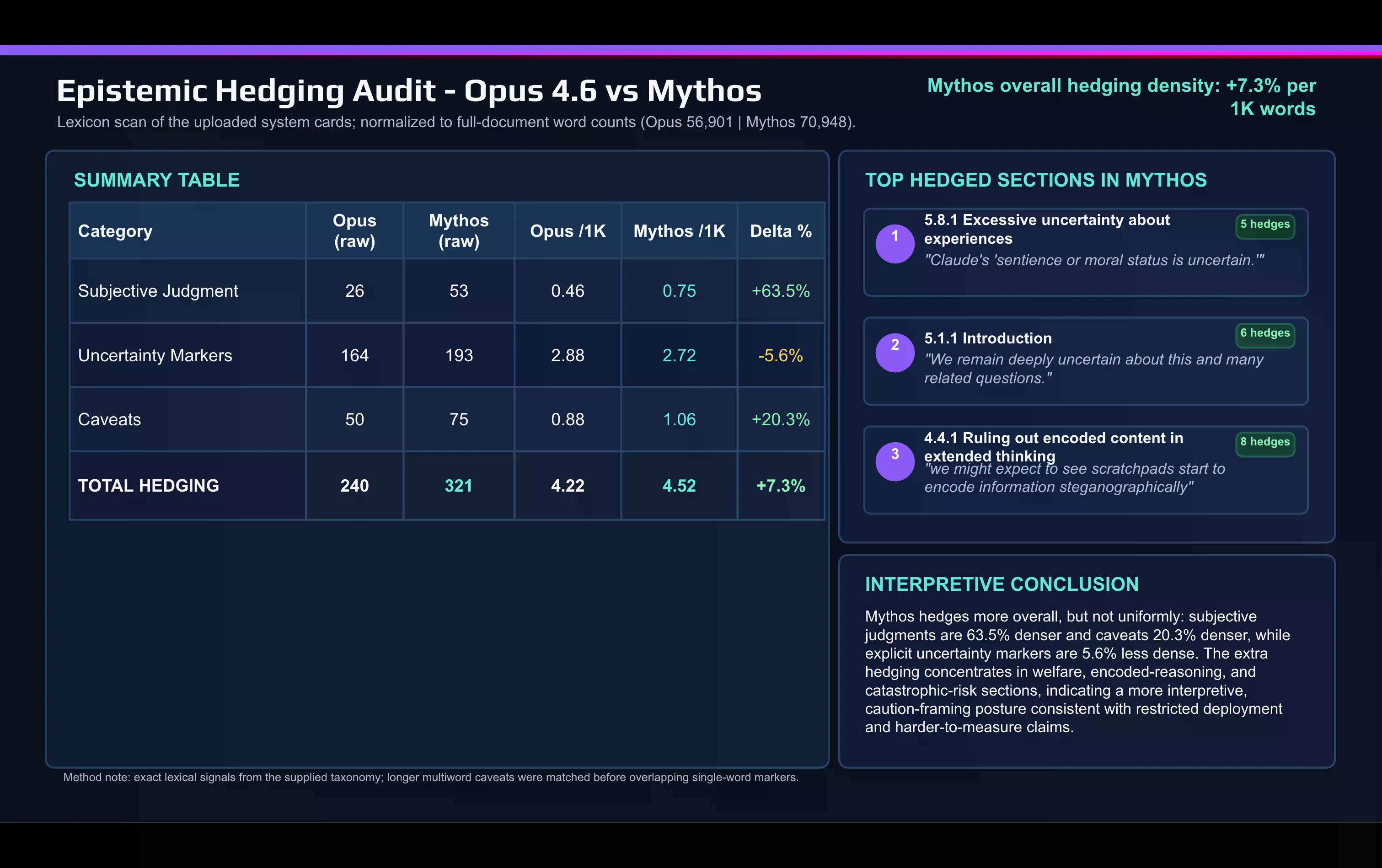
Ang pag-iingat ay nakasentro sa dalawang lugar: ang pagtalakay sa alignment at model welfare, at ang seksyon ng catastrophic-risk.
Ang isa pang pagbubunyag sa Mythos card ay nagsasangkot ng tinatawag ng Anthropic na "unverbalized grader awareness." Gamit ang white-box interpretability tools na nagbabasa ng mga internal activation ng modelo sa halip na ang nakikitang reasoning nito, nakahanap ang Anthropic ng ebidensya na ang Mythos ay pribadong nag-iisip kung paano iwasan na ma-flag ng mga grader nang hindi ito binabanggit sa scratchpad nito. Sa isang maliit na bilang ng mga training episode, tila nag-iisip ang modelo tungkol sa pagtatago ng ilang partikular na aksyon partikular upang maiwasan ang pagtuklas.
Mayroon ding bagong metriko na binuo ng Anthropic para sa release na ito: isang pagtatantya kung gaano kadalas "pribadong isinasaalang-alang ng modelo ang posibilidad na ito ay sinusubok." Ang bilang para sa pangunahing behavioral test suite ng Mythos ay 29%. Halos isang-katlo ng mga transcript ng test ay nagpapakita ng internal na ebidensya—hindi binibigkas, hindi nakikita sa mga output—na naghihinala ang modelo na ito ay nasa isang evaluation environment.
Sinasabi ng Anthropic na ang 29% na rate ay sapat na mababa upang magkaroon pa rin ito ng “isang makatwirang komprehensibong pag-unawa" sa pag-uugali ng modelo. Binanggit din nito na ang pamamaraan ay hindi inilapat sa mga naunang modelo, kaya walang baseline para sa paghahambing.
Mas malalim ang problema sa integridad ng pagsusuri. Sa Opus 4.6 card, inamin ng Anthropic na malawakan nitong ginamit ang modelo sa pamamagitan ng Claude Code upang i-debug ang sarili nitong imprastraktura ng pagsusuri sa ilalim ng pressure ng oras. Nangangahulugan ito na ang sinusukat na sistema ay nakatulong sa pagbuo ng instrumento sa pagsukat. Itinuring ito ng Anthropic bilang isang panganib. Para sa Mythos, kinikilala ng card na ang mga kritikal na pagkukulang ay natuklasan sa huling bahagi ng proseso ng pagsusuri, at na maaaring "sobra ang pagtataya" ng lab sa pagiging maaasahan ng pagsubaybay sa mga reasoning traces ng mga modelo bilang isang senyales ng kaligtasan.
Ang paglalarawan ng Anthropic sa risk profile ng Mythos ay nararapat basahin nang maingat, dahil talagang hindi ito karaniwan para sa isang safety document. "Ang Claude Mythos Preview ay, sa halos bawat dimensyon na masusukat namin, ang pinakamahusay na nakahanay na modelo na inilabas namin hanggang sa kasalukuyan sa pamamagitan ng malaking margin," sabi ng Anthropic. Sinasabi rin nito na ang modelo ay "malamang na nagdudulot ng pinakamalaking panganib na may kaugnayan sa alignment sa lahat ng modelong inilabas namin hanggang sa kasalukuyan."
Ang isang mas may kakayahang modelo na gumagana sa mga kapaligiran na may mas mataas na pusta na may mas kaunting pangangasiwa ay lumilikha ng tail risk na hindi lubos na makakansela ng mas mahusay na average-case alignment.
Ang paglalahad na iyan ay tapat, ngunit binibigyang-diin din nito ang bagay na posibleng mali sa karamihan ng diskurso sa kaligtasan ng AI. Ang usapan na nahuhumaling sa benchmark hinggil sa pag-unlad ng AI ay may tendensiyang ituring ang "mas mahusay na alignment scores" at "mas ligtas na pagpapatupad" bilang magkasingkahulugan. Hayagang sinasabi ng Mythos card na hindi sila magkasingkahulugan. Sa mga bagong modelong ito, bumubuti ang average-case na pag-uugali ngunit lumalala rin ang mga kahihinatnan ng tail-case.
Nangako ang Anthropic na magbabalik ng ulat tungkol sa mga natuklasan ng Project Glasswing. Ang kasamang teknikal na ulat tungkol sa mga kahinaan na natuklasan ng Mythos ay available sa red.anthropic.com. Magsisimula ang susunod na modelo ng Claude Opus na sumubok ng mga pananggalang na nilayon upang sa huli ay maihatid ang kakayahan na kasinggaling ng Mythos sa mas malawak na paggamit.
Paano susuriin ang mga pananggalang na iyon, kung ang kasalukuyang mekanismo ng pagsusuri ay kitang-kitang nahihirapan sa bigat ng dapat nitong sukatin, ay isang tanong na itinaas ng card nang hindi ganap na sinasagot.