
Ang pagdidisenyo ng isang molekula mula sa simula ay isa sa pinakamahirap na problema ng kimika. Hindi lamang ito tungkol sa pag-alam kung anong mga atom ang kokonektahin—ito ay tungkol sa pag-alam ng tamang pagkakasunud-sunod ng mga reaksyon, kung kailan poprotektahan ang mga sensitibong bahagi ng molekula, at kung paano iwasan ang mga dead end na maaaring sumira ng buwan ng trabaho sa laboratoryo.
Ayon sa tradisyon, ang kaalamang iyon ay nasa isip ng mga may karanasang kemista. Ngayon, isang pangkat sa EPFL ang nagnanais na ilagay ito sa isang modelo ng wika.
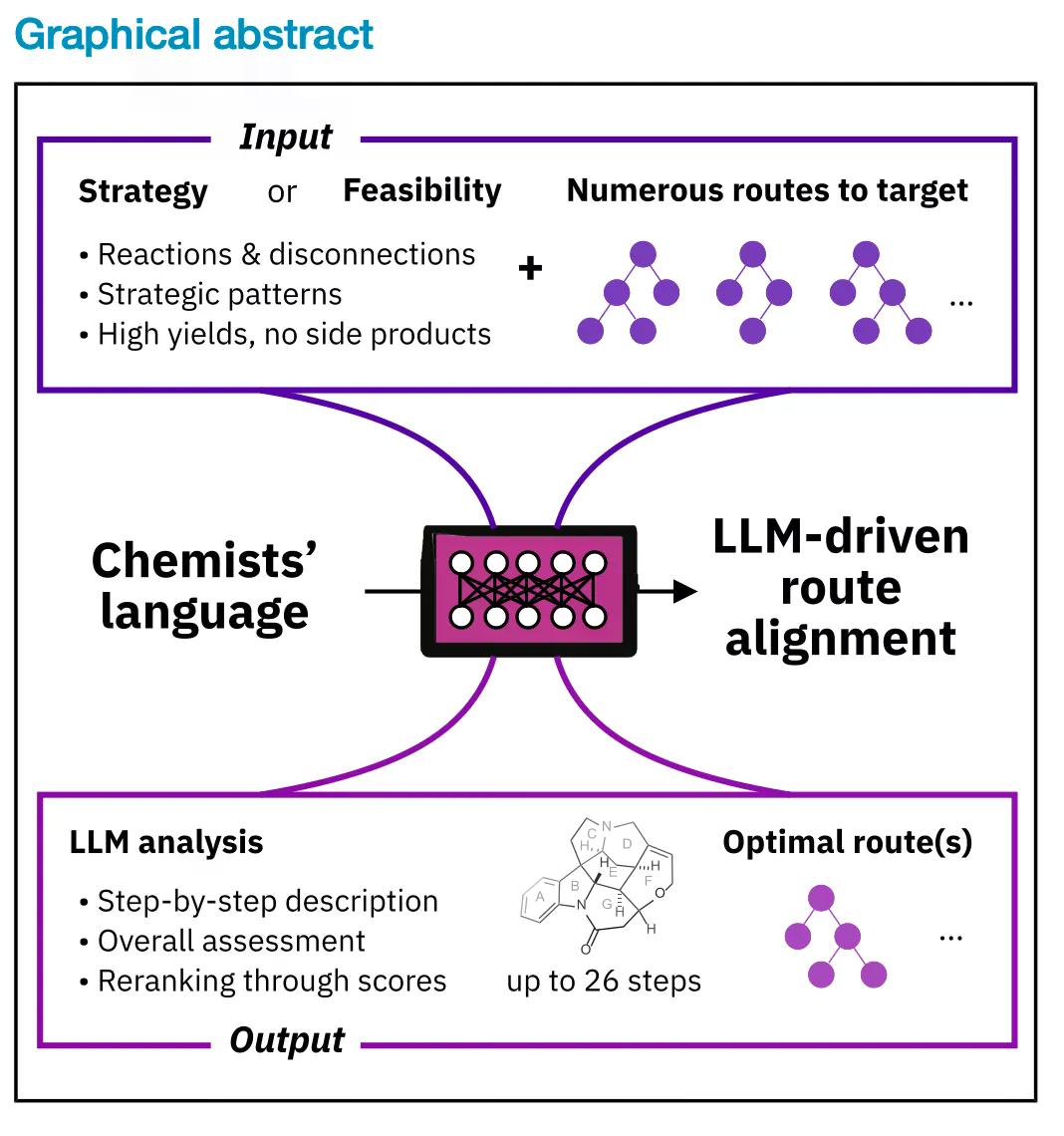
Ang mga mananaliksik na pinangunahan ni Philippe Schwaller ay naglathala ng isang papel ngayong linggo sa Matter na naglalarawan sa Synthegy, isang balangkas na gumagamit ng malalaking modelo ng wika (LLM) bilang mga reasoning engine para sa pagpaplano ng chemical synthesis. Ang pangunahing kaalaman ay banayad ngunit mahalaga: sa halip na hilingin sa AI na lumikha ng mga molekula, ginagamit ng koponan ang AI upang suriin ang mga ruta ng synthesis na nagawa na ng tradisyonal na software.
Ganito ito gumagana: Nagta-type ang isang kemista ng isang layunin sa payak na Ingles, tulad ng "buuin ang pyrimidine ring sa mga unang yugto." Ang kasalukuyang retrosynthesis software—na gumagana sa pamamagitan ng paghahati ng mga target na molekula sa mas simpleng bahagi—ay lumilikha ng dose-dosenang o daan-daang posibleng ruta ng synthesis.
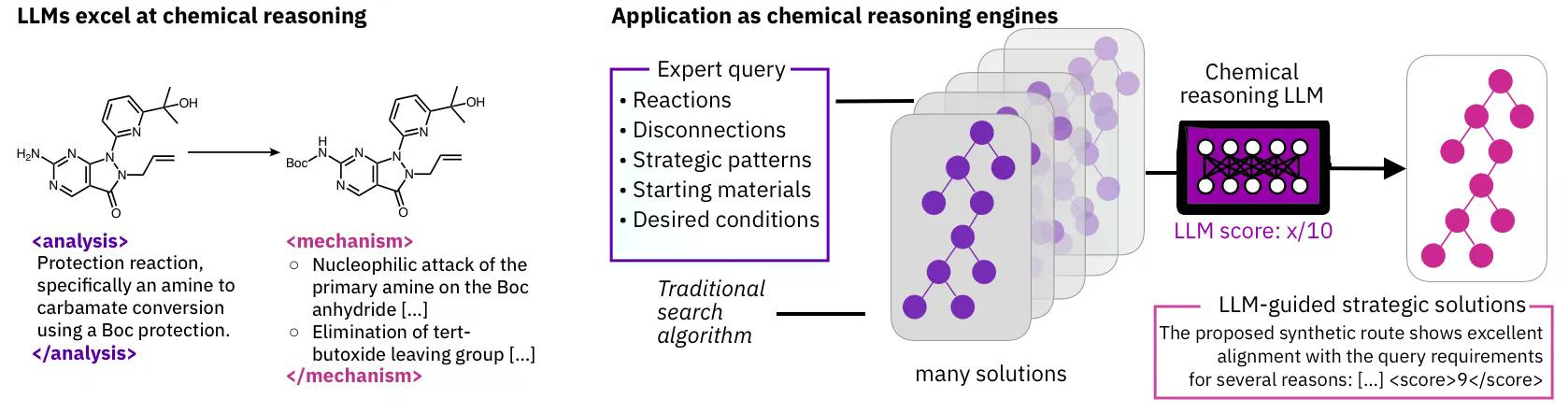
Ginagawa ng Synthegy ang bawat ruta sa text at ibinibigay ito sa isang LLM, na nagbibigay ng score sa bawat ruta kung gaano ito kahusay na tumutugma sa tagubilin ng kemista. Ang pinakamahusay ay lumulutang sa itaas, na may nakasulat na mga paliwanag kung bakit.
"Kapag gumagawa ng mga tool para sa mga kemista, napakahalaga ng user interface, at ang mga nakaraang tool ay umaasa sa mabibigat na filter at patakaran," sabi ni Andres M. Bran, nangungunang may-akda ng pag-aaral, sa isang pahayag mula sa EPFL.
Ang sistema ay napatunayan sa isang double-blind na pag-aaral na kinasasangkutan ng 36 na independiyenteng kemista na nagsuri ng 368 pares ng ruta. Ang kanilang mga pinili ay tumugma sa Synthegy's 71.2% ng oras, isang bilang na halos katumbas ng kung gaano kadalas nagkakasundo ang mga ekspertong kemista sa isa't isa. Mas madalas na sumang-ayon ang mga senior researcher (mga propesor at research scientist) sa Synthegy kaysa sa mga estudyanteng PhD, na nagpapahiwatig na nakukuha ng sistema ang parehong estratehikong intuwisyon na kaakibat ng karanasan.
Sinubukan ng mga mananaliksik ang ilang modelo ng AI, kabilang ang GPT-4o, Claude, at DeepSeek-r1. Matagal nang gumagawa ng progreso ang AI sa pagtuklas ng gamot, ngunit karamihan sa mga pamamaraan ay nakatuon sa mga modelong partikular na sinanay para sa mga tiyak na gawain. Ang Synthegy ay idinisenyo upang maging modular—maaari itong ikonekta sa anumang retrosynthesis engine sa backend, at sa anumang may kakayahang LLM sa panig ng pangangatwiran. Ang Gemini-2.5-pro ang nakakuha ng pinakamataas na score sa benchmark, habang ang DeepSeek-r1 ay tila isang malakas na open-source na alternatibo na maaaring gumana nang lokal.
Pinangangasiwaan din ng balangkas ang pangalawang problema: pagpapaliwanag ng mekanismo ng reaksyon. Ito ang tanong kung bakit nangyayari ang isang kemikal na reaksyon—kung anong mga paggalaw ng elektron ang nagaganap sa bawat hakbang. Pinaghihiwalay ng Synthegy ang mga reaksyon sa mga elementary moves at pinapagtasa ang LLM sa bawat kandidatong hakbang para sa chemical plausibility. Sa mga simpleng reaksyon tulad ng nucleophilic substitutions, naabot ng pinakamahusay na mga modelo ang halos perpektong kawastuhan.
Ang mga potensyal na kaso ng paggamit ay malawak. Ang pagtuklas ng gamot ang pinaka-obvious. Ipinakita na ng AI ang potensyal sa paghula ng mga resulta ng paggamot sa kanser, ngunit ang parehong pamamaraan ay nalalapat saanman kailangan ng mga kemista na magdisenyo ng mga bagong materyales o i-optimize ang mga reaksyong pang-industriya. Isang praktikal na detalye: ang pagsusuri ng 60 kandidatong ruta gamit ang Synthegy ay tumatagal ng humigit-kumulang 12 minuto at nagkakahalaga ng humigit-kumulang $2–3 sa mga API fee.
Kinikilala ng papel ang kasalukuyang mga limitasyon. Minsan ay maling nababasa ng mga LLM ang direksyon ng isang reaksyon sa representasyon nito sa text, na nagreresulta sa maling mga pagtaya sa feasibility. Ang mas maliliit na modelo ay hindi gumaganap nang mas mahusay kaysa sa random guessing. Ang mga ruta na mas mahaba sa 20 hakbang ay mas mahirap sundan nang magkakaugnay.
Ang code at mga benchmark ay pampublikong magagamit sa github.com/schwallergroup/steer.