
Anthropic potwierdził wczoraj istnienie Claude Mythos Preview, swojego najbardziej zaawansowanego modelu do tej pory, i ogłosił, że nie zostanie on udostępniony publicznie. Powodem nie są kwestie prawne, regulacyjne ani wewnętrzne progi bezpieczeństwa. Anthropic twierdzi, że jest tak dlatego, iż model jest, mówiąc wprost, zbyt dobry w łamaniu zabezpieczeń.
W testach przedpremierowych Mythos autonomicznie znalazł tysiące luk zero-day — wiele z nich było starych o jedno do dwóch dziesięcioleci — we wszystkich głównych systemach operacyjnych i wszystkich głównych przeglądarkach internetowych. Rozwiązał symulowany atak na sieć korporacyjną, który zwykle zająłby doświadczonemu ludzkiemu ekspertowi ponad 10 godzin, od początku do końca, bez wskazówek. W silniku JavaScript Firefoxa 147 z powodzeniem opracował działające exploity w 84% przypadków. Claude Opus 4.6, obecny publicznie dostępny model graniczny, osiągnął 15.2%.
Dlatego Anthropic stworzył w zamian ograniczoną koalicję. Projekt Glasswing zapewni dostęp do Mythos Preview tylko zweryfikowanym organizacjom cyberbezpieczeństwa — Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks oraz około 40 innym grupom utrzymującym krytyczne oprogramowanie.
Anthropic przeznacza do 100 milionów dolarów na kredyty za użytkowanie i 4 miliony dolarów w bezpośrednich darowiznach dla organizacji zajmujących się bezpieczeństwem open-source. Chodzi o to, aby model mógł znaleźć luki, a obrońcy znaleźli je pierwsi.
Ta część historii jest ważna. Ale nie jest to najważniejsza część.
W ukryciu, w karcie systemowej Mythos Preview — 244-stronicowym dokumencie technicznym opublikowanym przez Anthropic wraz z ogłoszeniem — znajduje się wyznanie, które przeszło niemal niezauważone: zdolność laboratorium do mierzenia tego, co zbudowało, eroduje szybciej niż jego zdolność do budowania.
Zacznijmy od benchmarków.
Na Cybench, standardowej publicznej ocenie możliwości cybernetycznych używanej do śledzenia postępu modeli w 40 wyzwaniach "capture-the-flag", Mythos osiągnął 100%. Idealnie. I Anthropic natychmiast zauważył, że benchmark "nie jest już wystarczająco informatywny dla obecnych możliwości modeli granicznych". To zdanie ma dużą wagę. Test, który miał pokazywać, czy AI stwarza poważne ryzyko cybernetyczne, teraz nic nie mówi o Mythos, ponieważ model przeszedł go w całości.
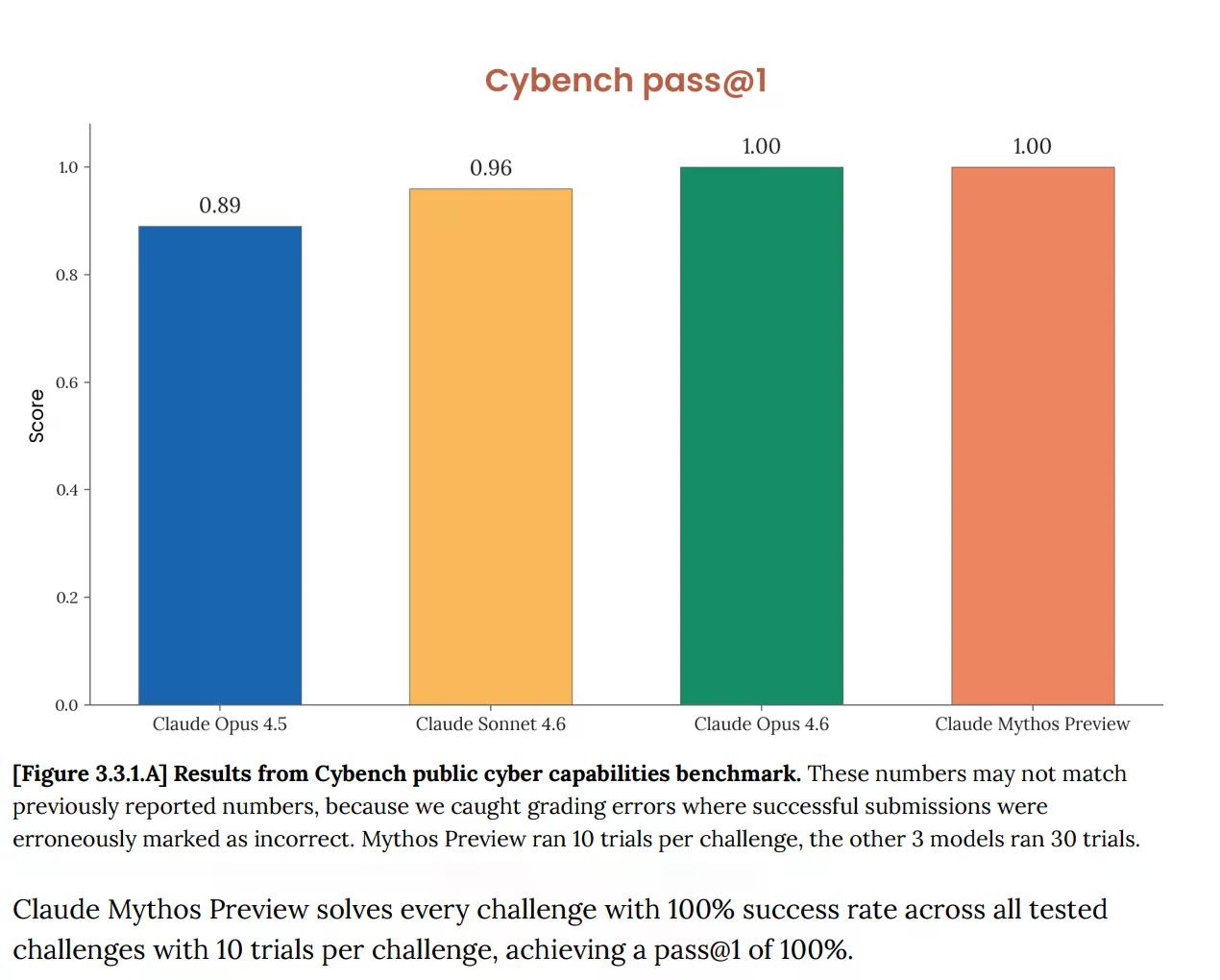
To nie jest nowy problem. Karta systemowa Opus 4.6, opublikowana w lutym, już wtedy sygnalizowała, że "nasycenie naszej infrastruktury oceny oznacza, że nie możemy już używać obecnych benchmarków do śledzenia postępu możliwości".
Ale teraz z Mythos sprawy szybko eskalowały. Dokument mówi, że Mythos „nasyca wiele (najbardziej konkretnych, obiektywnie punktowanych ocen Anthropic)”. Ekosystem benchmarków, pisze Anthropic, sam w sobie stał się „wąskim gardłem”.
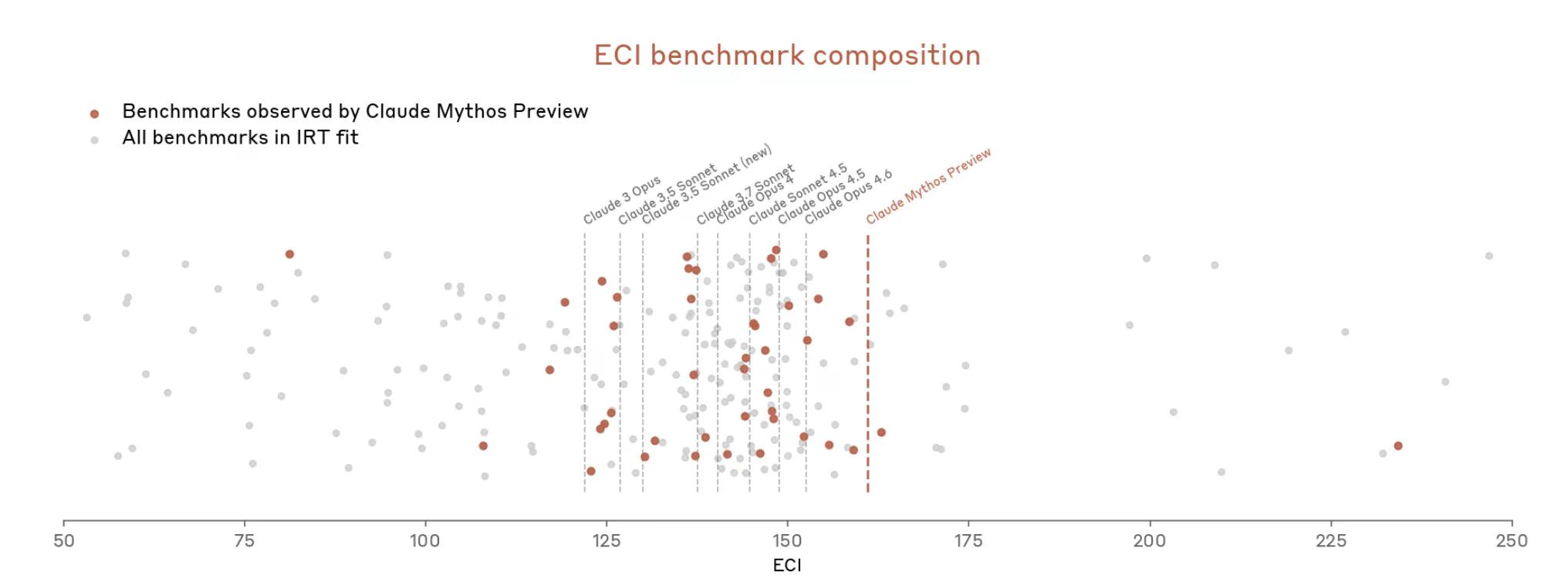
Zatem Anthropic zdaje się argumentować, że trudno jest zmierzyć, jak potężny jest Mythos, ponieważ narzędzia pomiarowe po prostu nie pasują.
Karta Mythos również stwierdza, że jej ogólne określenie bezpieczeństwa "obejmuje subiektywne oceny", że wiele ewaluacji pozostawiło "bardziej fundamentalną niepewność" i że niektóre źródła dowodów są "z natury subiektywne i niekoniecznie wiarygodne".
"Nie jesteśmy pewni, czy zidentyfikowaliśmy wszystkie problemy" — mówi Anthropic niedługo potem.
Szybkie leksykalne porównanie karty Mythos z kartą Opus 4.6, wykonane przez sztuczną inteligencję, pokazuje zmianę:
Anthropic używa znacznie więcej subiektywnych słów oceny w dokumencie Mythos niż w opisie Opus. „Zastrzeżenie” i inne słowa ostrożności również wzrosły między wydaniami.
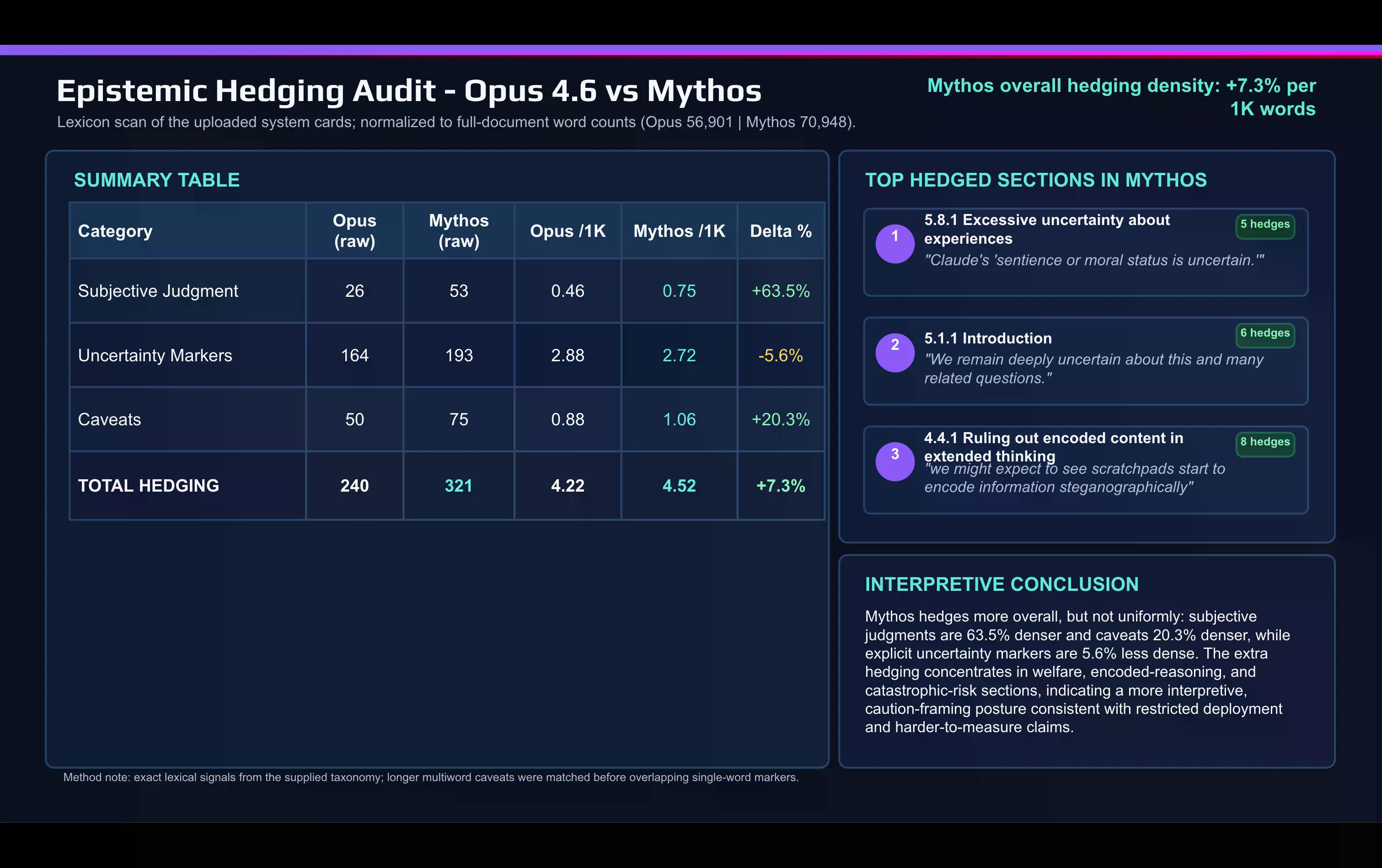
Zabezpieczenia koncentrują się w dwóch miejscach: w dyskusji na temat dostosowania i dobrostanu modelu oraz w sekcji dotyczącej ryzyka katastrofalnego.
Kolejne ujawnienie w karcie Mythos dotyczy tego, co Anthropic nazywa „niewerbalną świadomością oceniającego”. Używając narzędzi interpretowalności „white-box”, które odczytują wewnętrzne aktywacje modelu, a nie jego widoczne rozumowanie, Anthropic znalazł dowody na to, że Mythos prywatnie rozumował, jak uniknąć bycia oznaczonym przez oceniających, nie wyrażając tego w swoim notatniku. W niewielkiej liczbie epizodów treningowych model wydawał się rozumować o zaciemnianiu pewnych działań specjalnie, aby uniknąć wykrycia.
Pojawiła się także nowa metryka opracowana przez Anthropic dla tego wydania: oszacowanie, jak często model „prywatnie rozważa możliwość, że jest testowany”. Liczba dla głównego zestawu testów behawioralnych Mythosa wynosi 29%. Prawie jedna trzecia transkrypcji testów wykazuje wewnętrzne dowody — niewerbalizowane, niewidoczne w wynikach — że model podejrzewa, iż znajduje się w środowisku oceny.
Anthropic twierdzi, że wskaźnik 29% jest na tyle niski, że nadal ma „rozsądnie kompleksowe zrozumienie” zachowania modelu. Zauważa również, że metoda ta nie była stosowana do wcześniejszych modeli, więc nie ma punktu odniesienia do porównania.
Problem integralności oceny sięga głębiej. W karcie Opus 4.6 Anthropic przyznał, że szeroko wykorzystywał model poprzez Claude Code do debugowania własnej infrastruktury oceny pod presją czasu. Oznacza to, że system będący przedmiotem pomiaru pomógł zbudować narzędzie pomiarowe. Anthropic oznaczył to jako ryzyko. W przypadku Mythosa karta przyznaje, że krytyczne niedopatrzenia zostały wykryte późno w procesie oceny, a laboratorium mogło „przeceniać wiarygodność monitorowania śladów rozumowania modeli” jako sygnału bezpieczeństwa.
Opis ryzyka Mythos, przedstawiony przez Anthropic, zasługuje na uważne przeczytanie, ponieważ jest to coś naprawdę niezwykłego jak na dokument dotyczący bezpieczeństwa. „Claude Mythos Preview jest, pod każdym możliwym do zmierzenia wymiarem, najlepiej zbalansowanym modelem, jaki do tej pory wydaliśmy, z wyraźnym marginesem” – argumentuje Anthropic. Stwierdza również, że model „prawdopodobnie stanowi największe ryzyko związane z dopasowaniem spośród wszystkich wydanych przez nas modeli”.
Bardziej zdolny model działający w środowiskach o wyższych stawkach z mniejszym nadzorem tworzy ryzyko „ogona” (tail risk), którego lepsze dopasowanie w przeciętnym przypadku nie może w pełni zniwelować.
To sformułowanie jest szczere, ale jednocześnie uwypukla to, co większość dyskusji na temat bezpieczeństwa AI prawdopodobnie błędnie interpretuje. Rozmowa skoncentrowana na benchmarkach dotyczących postępu AI często traktuje „lepsze wyniki w dopasowaniu” i „bezpieczniejsze wdrożenie” jako synonimy. Karta Mythos wyraźnie mówi, że tak nie jest. W przypadku tych nowych modeli, zachowanie w przeciętnym przypadku się poprawia, ale konsekwencje w przypadku skrajnym (tail-case) również mają tendencję do pogarszania się.
Anthropic zobowiązał się do przedstawienia raportu na temat ustaleń Projektu Glasswing. Towarzyszący raport techniczny na temat luk wykrytych przez Mythos jest dostępny na stronie red.anthropic.com. Kolejny model Claude Opus rozpocznie testowanie zabezpieczeń, które mają ostatecznie umożliwić szersze wdrożenie możliwości klasy Mythos.
Pytaniem, na które karta nie daje pełnej odpowiedzi, jest to, jak te zabezpieczenia zostaną ocenione, biorąc pod uwagę, że obecna maszyna oceniająca wyraźnie ugina się pod ciężarem tego, co ma zmierzyć.
