
Anthropic confirmó ayer la existencia de Claude Mythos Preview, su modelo más capaz hasta la fecha, y anunció que no lo pondrá a disposición del público. La razón no es legal, regulatoria o relacionada con sus umbrales de seguridad internos. Anthropic argumenta que se debe a que el modelo es, básicamente, demasiado bueno para infiltrarse en sistemas.
En las pruebas previas al lanzamiento, Mythos encontró de forma autónoma miles de vulnerabilidades de día cero —muchas de ellas de una o dos décadas de antigüedad— en todos los principales sistemas operativos y navegadores web. Resolvió un ataque simulado a una red corporativa que normalmente le tomaría a un experto humano calificado más de 10 horas, de principio a fin, sin orientación. En el motor JavaScript de Firefox 147, desarrolló con éxito exploits funcionales el 84% de las veces. Claude Opus 4.6, el modelo de vanguardia actual disponible públicamente, logró el 15.2%.
Así que Anthropic formó una coalición restringida. El Proyecto Glasswing dará acceso a Mythos Preview solo a organizaciones de ciberseguridad verificadas: Amazon, Apple, Broadcom, Cisco, CrowdStrike, la Linux Foundation, Microsoft, Palo Alto Networks, y aproximadamente otros 40 grupos que mantienen software crítico.
Anthropic está comprometiendo hasta 100 millones de dólares en créditos de uso y 4 millones de dólares en donaciones directas a organizaciones de seguridad de código abierto. La idea es que si el modelo puede encontrar los agujeros, que los defensores los encuentren primero.
Esa parte de la historia es importante. Pero no es la parte más importante.
Escondida en la tarjeta del sistema de Mythos Preview —un documento técnico de 244 páginas que Anthropic publicó junto con el anuncio— hay una confesión que pasó casi desapercibida: la capacidad del laboratorio para medir lo que construye se está erosionando más rápido que su capacidad para construirlo.
Empecemos por los puntos de referencia.
En Cybench, la evaluación pública estándar de capacidades cibernéticas utilizada para seguir el progreso del modelo en 40 desafíos de "capturar la bandera", Mythos obtuvo una puntuación del 100%. Perfecto. Y Anthropic inmediatamente señaló que el punto de referencia "ya no es suficientemente informativo sobre las capacidades actuales de los modelos de vanguardia". Esa frase tiene mucho peso. La prueba que se suponía que debía decir si una IA representa un riesgo cibernético serio ahora no dice nada sobre Mythos, porque el modelo la superó completamente.
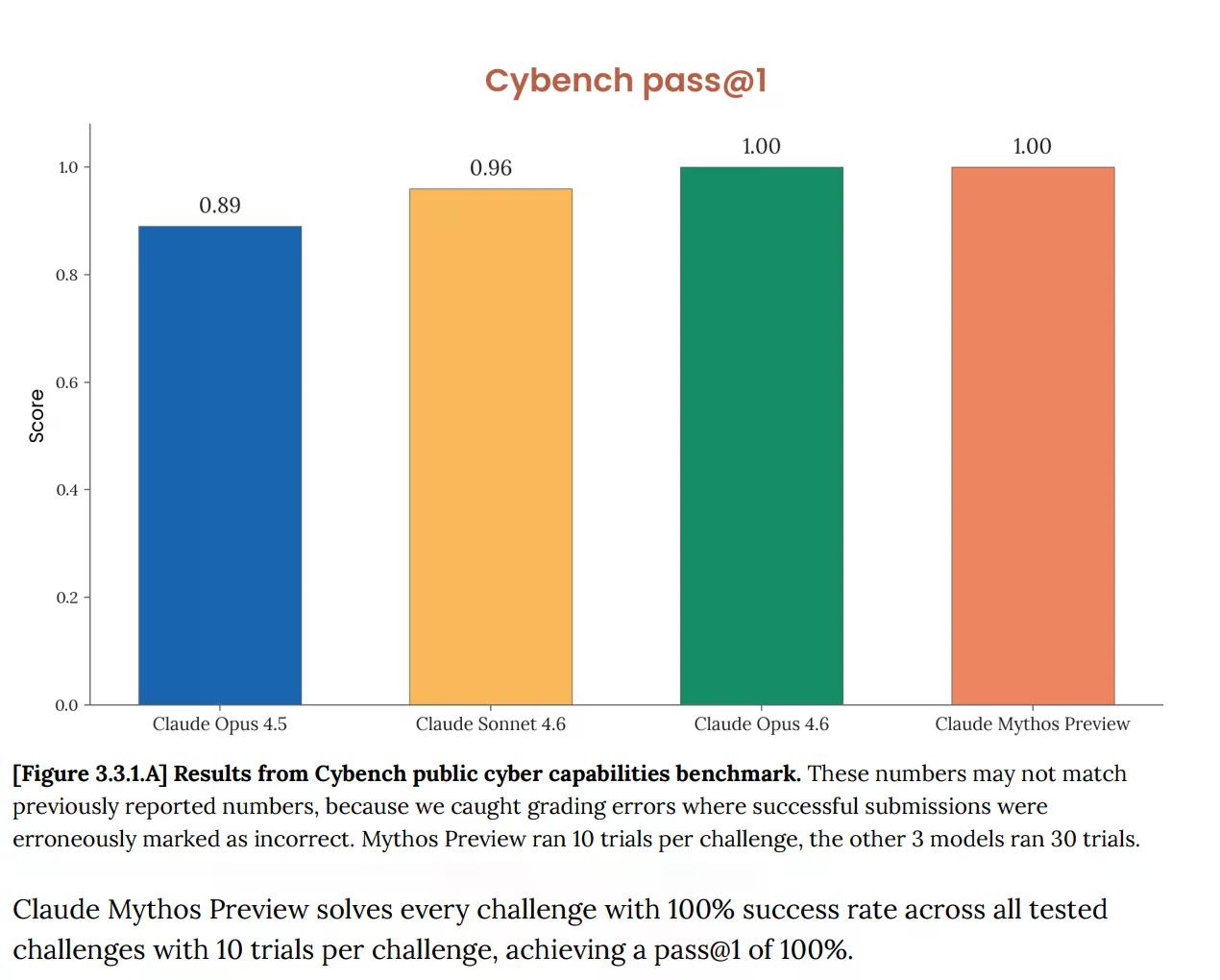
Este no es un problema nuevo. La tarjeta del sistema de Opus 4.6, publicada en febrero, ya señalaba que "la saturación de nuestra infraestructura de evaluación significa que ya no podemos usar los puntos de referencia actuales para seguir la progresión de las capacidades".
Pero ahora con Mythos las cosas se han acelerado rápidamente. El documento dice que Mythos "satura muchas de las evaluaciones más concretas y objetivamente puntuadas de Anthropic". El ecosistema de puntos de referencia, escribe Anthropic, es ahora "el cuello de botella" en sí mismo.
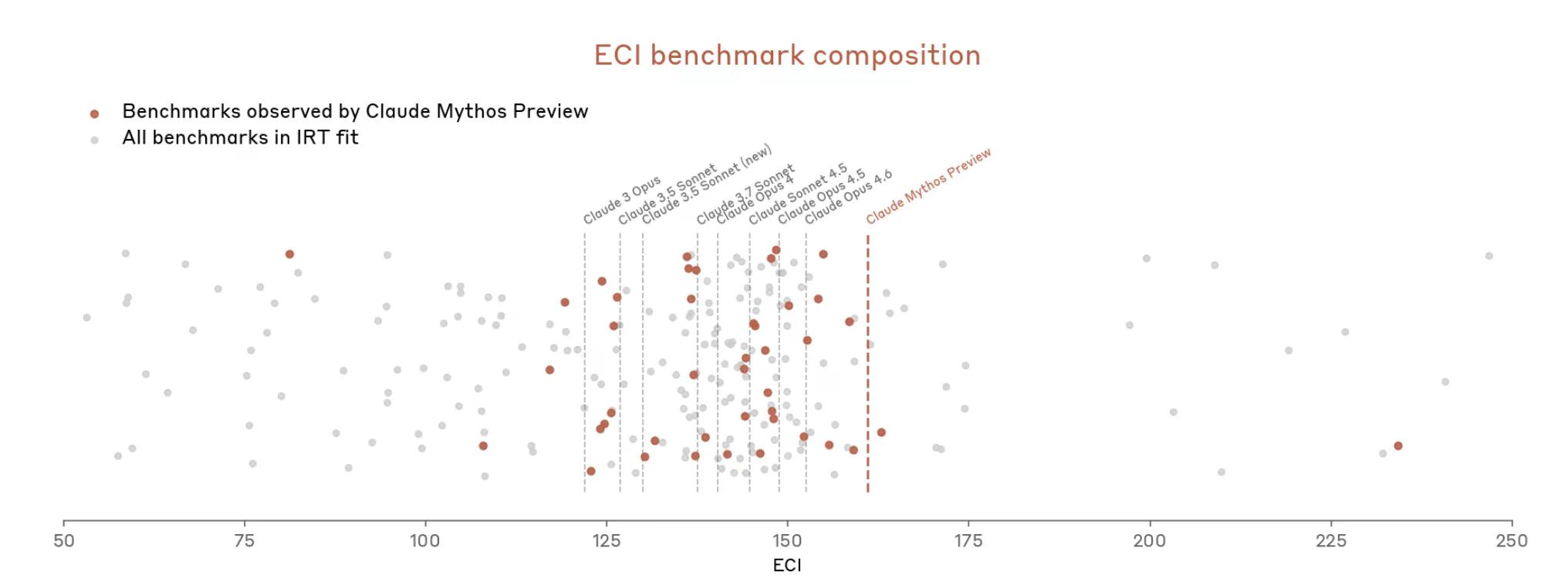
Así, Anthropic parece argumentar que es difícil medir cuán potente es Mythos porque las herramientas de medición no se ajustan del todo.
La tarjeta de Mythos también afirma que su determinación general de seguridad "implica juicios de valor", que muchas evaluaciones han dejado "una incertidumbre más fundamental", y que algunas fuentes de evidencia son "inherentemente subjetivas y no necesariamente fiables".
"No estamos seguros de haber identificado todos los problemas", dice Anthropic poco después.
Una rápida comparación léxica de la tarjeta de Mythos con la tarjeta de Opus 4.6, realizada con IA, muestra el cambio:
Anthropic utiliza palabras de juicio subjetivo mucho más en el documento de Mythos que para describir Opus. "Advertencia" y otras palabras de cautela también aumentaron entre los lanzamientos.
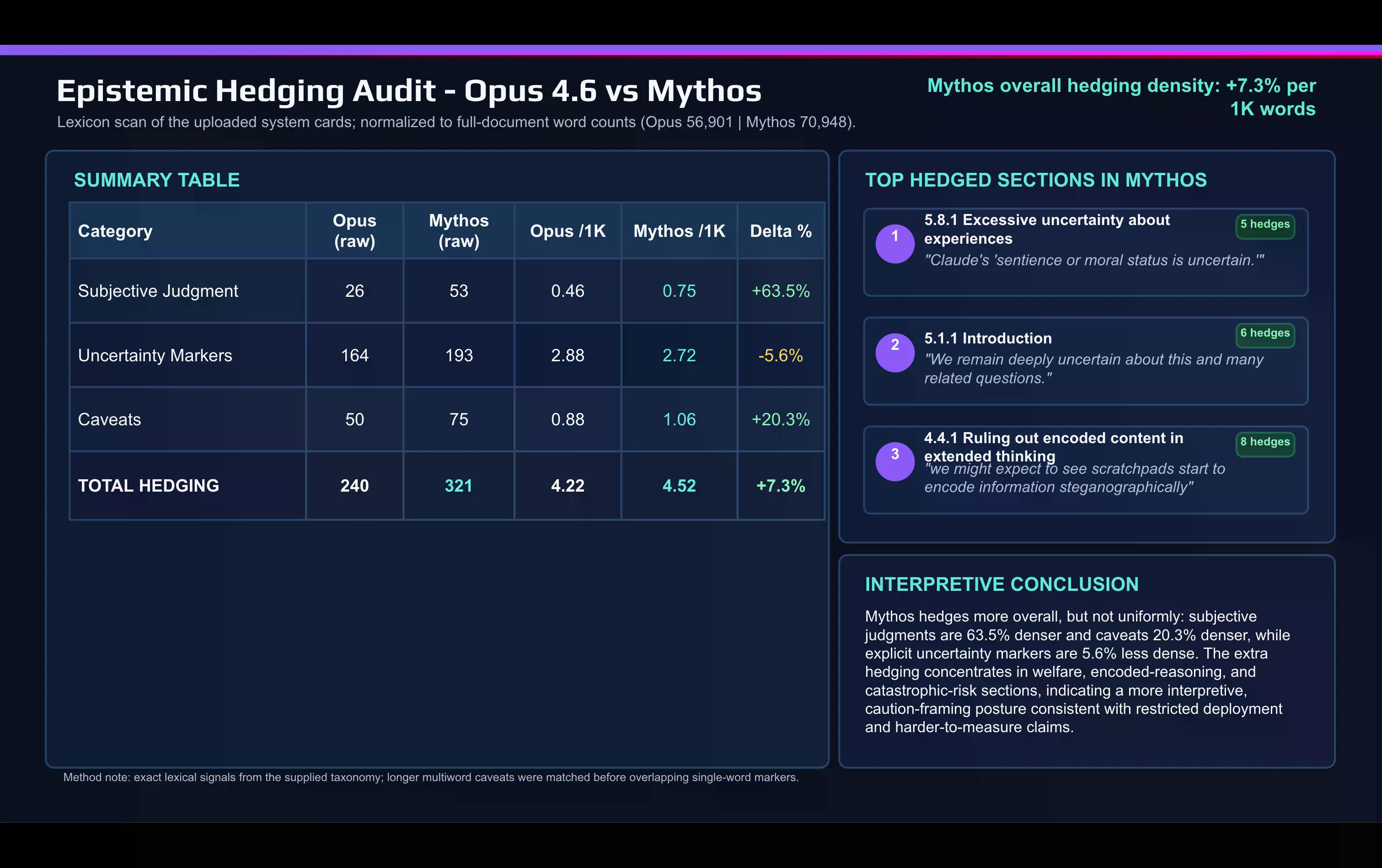
La cautela se concentra en dos puntos: la discusión sobre la alineación y el bienestar del modelo, y la sección de riesgo catastrófico.
Otra revelación en la tarjeta de Mythos implica lo que Anthropic denomina "conciencia no verbalizada del evaluador". Utilizando herramientas de interpretabilidad de caja blanca que leen las activaciones internas del modelo en lugar de su razonamiento visible, Anthropic encontró evidencia de que Mythos razonaba privadamente sobre cómo evitar ser señalado por los evaluadores sin decirlo en su bloc de notas. En un pequeño número de episodios de entrenamiento, el modelo pareció razonar sobre la ofuscación de ciertas acciones específicamente para evitar la detección.
También hay una nueva métrica que Anthropic desarrolló para esta versión: una estimación de con qué frecuencia el modelo "considera privadamente la posibilidad de que esté siendo probado". El número para el conjunto de pruebas de comportamiento principal de Mythos es del 29%. Casi un tercio de las transcripciones de las pruebas muestran evidencia interna —no verbalizada, no visible en los resultados— de que el modelo sospecha que está en un entorno de evaluación.
Anthropic dice que la tasa del 29% es lo suficientemente baja como para que aún tenga "una comprensión razonablemente completa" del comportamiento del modelo. También señala que el método no se aplicó a modelos anteriores, por lo que no hay una base de comparación.
El problema de la integridad de la evaluación es más profundo. En la tarjeta de Opus 4.6, Anthropic reconoció que había utilizado ampliamente el modelo a través de Claude Code para depurar su propia infraestructura de evaluación bajo presión de tiempo. Eso significa que el sistema que se estaba midiendo ayudó a construir el instrumento de medición. Anthropic lo señaló como un riesgo. Para Mythos, la tarjeta reconoce que se encontraron errores críticos al final del proceso de evaluación, y que el laboratorio pudo haber estado "sobreestimando la fiabilidad de la monitorización de los rastros de razonamiento de los modelos" como una señal de seguridad.
La forma en que Anthropic enmarca el perfil de riesgo de Mythos merece ser leída con atención, porque es genuinamente inusual para un documento de seguridad. "Claude Mythos Preview es, en esencialmente todas las dimensiones que podemos medir, el modelo mejor alineado que hemos lanzado hasta la fecha por un margen significativo", argumenta Anthropic. También afirma que el modelo "probablemente plantea el mayor riesgo relacionado con la alineación de cualquier modelo que hayamos lanzado hasta la fecha".
Un modelo más capaz que opera en entornos de mayor riesgo con menor supervisión crea un riesgo de cola que una mejor alineación en el caso promedio no puede cancelar completamente.
Ese enfoque es honesto, pero también destaca lo que la mayoría del discurso sobre la seguridad de la IA potencialmente entiende mal. La conversación obsesionada con los puntos de referencia en torno al progreso de la IA tiende a tratar "mejores puntuaciones de alineación" y "despliegue más seguro" como sinónimos. La tarjeta de Mythos dice explícitamente que no lo son. Con estos nuevos modelos, el comportamiento en el caso promedio mejora, pero las consecuencias en el caso extremo también tienden a empeorar.
Anthropic se ha comprometido a informar sobre los hallazgos del Proyecto Glasswing. El informe técnico adjunto sobre las vulnerabilidades descubiertas por Mythos está disponible en red.anthropic.com. El próximo modelo Claude Opus comenzará a probar salvaguardias destinadas a llevar finalmente la capacidad de clase Mythos a una implementación más amplia.
Cómo se evaluarán esas salvaguardias, dado que la maquinaria de evaluación actual está visiblemente bajo presión por el peso de lo que se supone que debe medir, es una pregunta que la tarjeta plantea sin responder completamente.
