
Pergunte a cinco dos sistemas de IA mais avançados do mundo se uma afirmação é verdadeira e, em dois terços das vezes, pelo menos um deles lhe dará uma resposta diferente. Essa é a conclusão de um novo estudo publicado este mês pelo pesquisador Kosta Jordanov na Lenz Research.
O estudo apresentou ao GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 Pro com Busca e Sonar Pro as mesmas 1.000 afirmações de verificação de fatos do mundo real submetidas por usuários reais. Os modelos tiveram que escolher uma das quatro classificações: verdadeiro, em grande parte verdadeiro, enganoso ou falso.
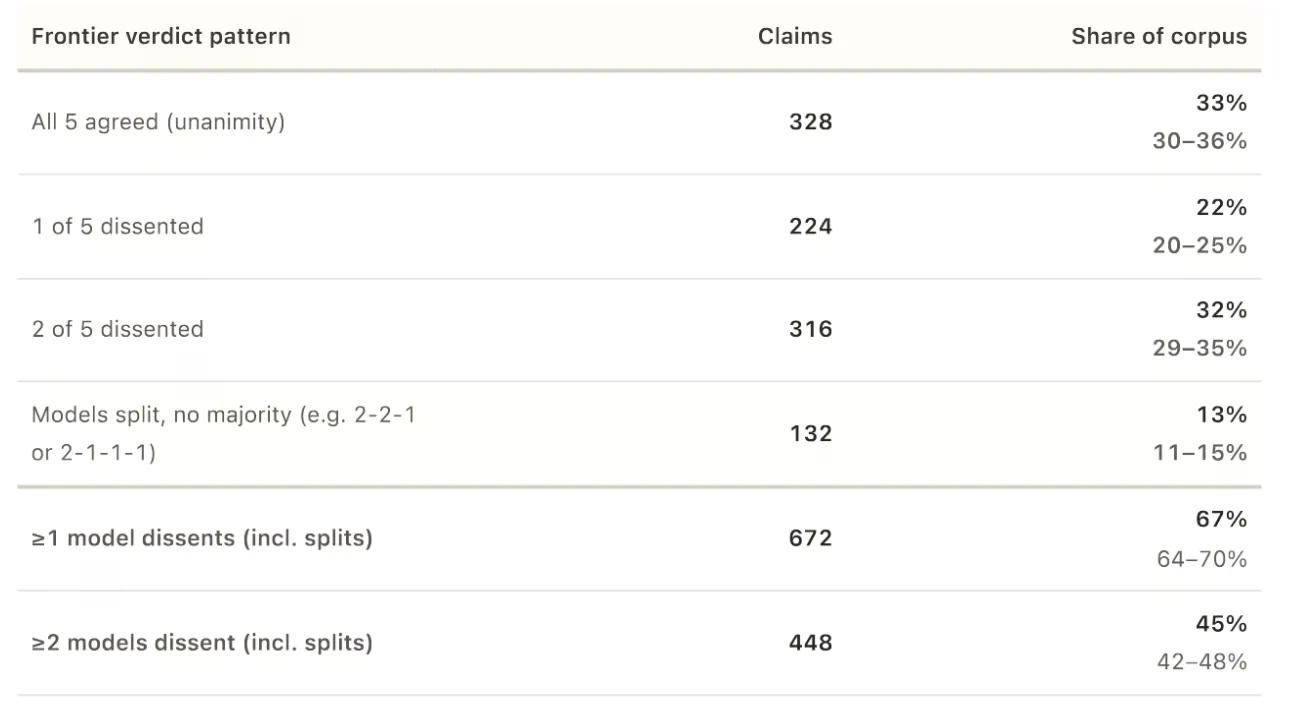
Em 672 das 1.000 afirmações, pelo menos um modelo se afastou da maioria. Em 34% dos casos, a discordância foi grave: um modelo classificou uma afirmação como verdadeira, enquanto outro a classificou como falsa.
“Estes não são itens de benchmark com chaves de resposta públicas — são afirmações que usuários reais submeteram para verificação a uma plataforma de checagem de fatos”, diz o estudo. “Apenas um ‘bucket’ de veredicto pode estar correto por afirmação, então qualquer desacordo entre o painel significa que o veredicto de pelo menos um modelo é inconsistente com a etiqueta sob esta rubrica de 4 categorias.”
Estudos anteriores sobre a alucinação da IA mostraram que os chatbots inventam fatos. Esse é um problema. Este é diferente. Os modelos não estão necessariamente inventando coisas, eles simplesmente não conseguem concordar em julgamentos factuais básicos sobre o mesmo material.
A pesquisa utilizou uma configuração que torna mais difícil para as empresas de IA justificarem os resultados. Em vez de extrair afirmações de conjuntos de testes padrão — o tipo que frequentemente vaza para os dados de treinamento —, os pesquisadores usaram afirmações submetidas por pessoas reais à plataforma de verificação de fatos da Lenz. “A maioria dessas afirmações dificilmente aparecerá em qualquer corpus de treinamento com um rótulo de ouro anexado — não há uma chave de resposta canônica para correspondência de padrões, nem um ranking de benchmark para ancorar”, observa o artigo.
A medida estatística de concordância, chamada alfa de Krippendorff, foi de 0,639 em uma escala onde 1,0 significa concordância perfeita e 0 significa chance aleatória. O estudo afirma que isso indica “concordância não trivial, mas limitada.” “Os veredictos dos modelos são estruturados em vez de aleatórios, mas não consistentes o suficiente para tratar o painel como um único juiz intermutável”, observam os pesquisadores. Pesquisadores geralmente consideram qualquer coisa abaixo de 0,8 como fraca.
Quando todos os cinco modelos concordaram — o que aconteceu em apenas 328 das 1.000 afirmações —, eles quase nunca concordaram que algo era enganoso ou em grande parte verdadeiro. Apenas quatro afirmações receberam um veredicto unânime de “enganoso”. Nenhuma recebeu um veredicto unânime de “em grande parte verdadeiro”.
Os pesquisadores forneceram exemplos de afirmações onde os modelos de IA mostraram a maior divergência, incluindo "A carteira ativa do Banco Mundial na Nigéria ultrapassa US$ 16,4 bilhões em 2025." O ChatGPT 5.4 disse que era “em grande parte verdadeiro”, enquanto o Gemini 3 Pro o classificou como “falso” e seu modelo irmão, Gemini 3 Pro + Search, o classificou como “enganoso”.
Em outro exemplo, os modelos foram apresentados à afirmação: "Donald Trump disse que um ataque ao Irã foi adiado a pedido dos aliados do Golfo." O GPT-5.4 disse que era falso, o Claude Opus 4.7 o chamou de em grande parte verdadeiro, o Gemini 3 Pro disse falso, e o Gemini 3 Pro + Search o classificou como verdadeiro.
“O painel converge em veredictos definitivos; o meio da rubrica é onde ele se fragmenta”, descobriram os pesquisadores. A unanimidade só ocorreu nos extremos: ou a afirmação era definitivamente verdadeira ou definitivamente falsa.
Isso é importante porque as pessoas estão cada vez mais recorrendo aos sistemas de IA para verificação de fatos. Se você colar uma afirmação de um artigo de notícia no ChatGPT, Claude ou Gemini, poderá obter três respostas diferentes. Em qual delas você confia?
As empresas de IA adoram dizer que seus modelos estão ficando mais precisos. Elas publicam pontuações de benchmark que mostram uma melhoria constante. Mas o estudo da Lenz testou esses modelos em tipos de afirmações complexas e ambíguas sobre as quais humanos reais realmente discutem — e descobriu que os modelos também discutem.
O artigo faz questão de ressaltar isso. “Uma maioria de modelos de ponta não é a verdade absoluta. O veredicto da maioria às vezes está errado; um modelo individual divergente às vezes está certo. Usamos a maioria como um ponto de referência estrutural para medir o desacordo, não como um substituto para a correção.”
Há um problema mais profundo enterrado nos números. Quando os modelos discordam, pelo menos um deles deve estar errado — o estudo chama o veredicto de um modelo de “inconsistente com a etiqueta sob esta rubrica de 4 categorias”. Não há mecanismo de desempate, nem tribunal de apelação. Relatórios recentes sobre a confiabilidade da IA levantaram alertas semelhantes.
Nas 328 afirmações onde todos os cinco modelos concordaram, zero recebeu um veredicto unânime de “em grande parte verdadeiro”. A categoria de nuances esvaziou completamente. Se os modelos de IA só conseguem encontrar consenso nos extremos, podem eles ser confiáveis como verificadores de fatos?