

DeepSeek est de retour, et il est apparu quelques heures après qu'OpenAI ait lancé GPT-5.5. Coïncidence ? Peut-être. Mais si vous êtes un laboratoire d'IA chinois que le gouvernement américain tente de freiner avec des interdictions d'exportation de puces depuis trois ans, votre sens du timing devient très aiguisé.
Le laboratoire basé à Hangzhou a publié aujourd'hui des versions préliminaires de DeepSeek-V4-Pro et DeepSeek-V4-Flash, toutes deux open-weight, et toutes deux avec des fenêtres de contexte d'un million de jetons. Cela signifie que vous pouvez travailler avec un contexte d'environ la taille de la trilogie du Seigneur des Anneaux avant que le modèle ne s'effondre. Les deux sont également proposées à des prix bien inférieurs à ceux de tout ce qui est comparable en Occident, et les deux sont gratuites pour ceux qui sont capables de les exécuter localement.
La dernière perturbation majeure de DeepSeek – R1 en janvier 2025 – a fait chuter la capitalisation boursière de Nvidia de 600 milliards de dollars en une seule journée, les investisseurs se demandant si les entreprises américaines avaient vraiment besoin de si gros investissements pour produire des résultats qu'un petit laboratoire chinois obtenait avec une fraction du coût. V4 est une approche différente : plus discrète, plus technique et plus axée sur l'efficacité pour quiconque construit réellement avec l'IA.
Parmi les deux nouveaux modèles, le V4-Pro de DeepSeek est le plus grand, avec 1,6 trillion de paramètres au total. Pour mettre cela en perspective, les paramètres sont les « réglages » internes ou les « cellules cérébrales » qu'un modèle utilise pour stocker des connaissances et reconnaître des schémas – plus un modèle a de paramètres, plus il peut théoriquement contenir des informations complexes. Cela en fait le plus grand modèle open-source sur le marché des LLM à ce jour. La taille peut sembler ridicule jusqu'à ce que vous appreniez qu'il n'en active que 49 milliards par passage d'inférence.
C'est le stratagème du « Mixture-of-Experts » que DeepSeek a perfectionné depuis V3 : Le modèle complet est là, mais seule la tranche pertinente s'active pour chaque requête donnée. Plus de connaissances, la même facture de calcul.
« DeepSeek-V4-Pro-Max, le mode d'effort de raisonnement maximal de DeepSeek-V4-Pro, fait progresser significativement les capacités de connaissance des modèles open-source, s'établissant fermement comme le meilleur modèle open-source disponible aujourd'hui », a écrit DeepSeek dans la fiche officielle du modèle sur Huggingface. « Il atteint des performances de premier ordre dans les benchmarks de codage et réduit considérablement l'écart avec les principaux modèles closed-source sur les tâches de raisonnement et d'agentique. »
V4-Flash est le modèle pratique : 284 milliards de paramètres au total, 13 milliards actifs. Il est conçu pour être plus rapide, moins cher, et selon les propres benchmarks de DeepSeek, « atteint des performances de raisonnement comparables à la version Pro lorsqu'un budget de réflexion plus important est alloué. »
Les deux prennent en charge un million de jetons de contexte. C'est environ 750 000 mots – à peu près l'intégralité de la trilogie du « Seigneur des Anneaux » avec du rab. Et c'est une fonctionnalité standard, pas un niveau premium.
Voici la partie technique pour les passionnés ou ceux qui s'intéressent à la magie qui anime le modèle. DeepSeek ne cache pas ses secrets, et tout est disponible gratuitement – l'intégralité du document est disponible sur Github.
L'attention standard de l'IA – le mécanisme qui permet à un modèle de comprendre les relations entre les mots – a un problème d'échelle brutal. Chaque fois que vous doublez la longueur du contexte, le coût de calcul quadruple environ. Ainsi, exécuter un modèle sur un million de jetons n'est pas seulement deux fois plus cher que 500 000 jetons. C'est quatre fois plus cher. C'est pourquoi un long contexte a toujours été une case à cocher que les laboratoires ajoutaient puis limitaient silencieusement derrière des plafonds de débit.
DeepSeek a inventé deux nouveaux types d'attention pour contourner ce problème. Le premier, Compressed Sparse Attention, fonctionne en deux étapes. Il compresse d'abord des groupes de jetons – par exemple, tous les 4 jetons – en une seule entrée. Ensuite, au lieu de prêter attention à toutes ces entrées compressées, il utilise un "Lightning Indexer" pour ne sélectionner que les résultats les plus pertinents pour une requête donnée. Votre modèle passe d'une attention à un million de jetons à une attention à un ensemble beaucoup plus petit des fragments les plus importants, un peu comme un bibliothécaire qui ne lit pas tous les livres mais sait exactement quelle étagère consulter.
Le second, Heavily Compressed Attention, est plus agressif. Il regroupe tous les 128 jetons en une seule entrée – pas de sélection clairsemée, juste une compression brutale. Vous perdez des détails précis, mais vous obtenez une vue d'ensemble extrêmement bon marché. Les deux types d'attention s'exécutent en couches alternées, de sorte que le modèle obtient à la fois le détail et la vue d'ensemble.
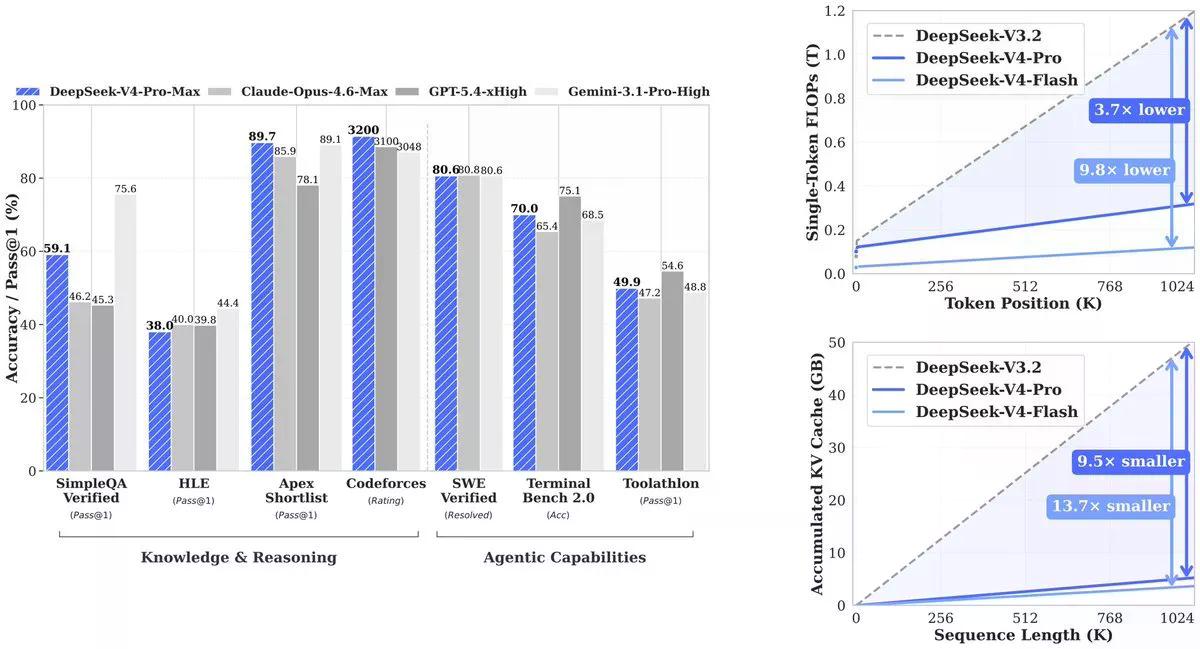
Le résultat, tiré du document technique : À un million de jetons, V4-Pro utilise 27 % de la puissance de calcul nécessaire à son prédécesseur (V3.2). Le cache KV — la mémoire dont le modèle a besoin pour suivre le contexte — tombe à seulement 10 % de V3.2. V4-Flash pousse cela plus loin : 10 % de calcul, 7 % de mémoire.
Et cela a permis à DeepSeek d'offrir un prix par jeton beaucoup moins cher que ses concurrents, tout en fournissant des résultats comparables. Pour exprimer cela en dollars : GPT-5.5 a été lancé hier à 5 $ en entrée et 30 $ en sortie par million de jetons, avec GPT-5.5 Pro tarifé à 30 $ par million de jetons en entrée et 180 $ par million de jetons en sortie.
DeepSeek V4-Pro coûte 1,74 $ en entrée et 3,48 $ en sortie. V4-Flash coûte 0,14 $ en entrée et 0,28 $ en sortie. Le PDG de Cline, Saoud Rizwan, a souligné que si Uber avait utilisé DeepSeek au lieu de Claude, son budget IA 2026 — qui aurait suffi pour quatre mois d'utilisation — aurait duré sept ans.
deepseek v4 is now the cheapest sota model available at 1/20th the cost of opus 4.7.
for perspective, if uber used deepseek instead of claude their 2026 ai budget would have lasted 7 years instead of only 4 months. pic.twitter.com/i9rJZzvRBV
— Saoud Rizwan (@sdrzn) April 24, 2026
DeepSeek fait quelque chose d'inhabituel dans son rapport technique : il publie les écarts. La plupart des versions de modèles ne retiennent que les benchmarks où elles gagnent. DeepSeek a effectué la comparaison complète avec GPT-5.4 et Gemini-3.1-Pro, a constaté que le raisonnement de V4-Pro était en retard sur ces modèles d'environ trois à six mois, et l'a quand même publié.
Là où V4-Pro-Max gagne réellement : Codeforces, un benchmark de programmation compétitive, classé comme les échecs humains. V4-Pro a obtenu un score de 3 206, le plaçant autour de la 23e place parmi les participants humains réels au concours. Sur Apex Shortlist, un ensemble sélectionné de problèmes difficiles de mathématiques et de STEM, il a obtenu un taux de réussite de 90,2 % contre 85,9 % pour Opus 4.6 et 78,1 % pour GPT-5.4. Sur SWE-Verified, qui mesure la capacité d'un modèle à résoudre de vrais problèmes GitHub tirés de référentiels open-source réels, il a obtenu un score de 80,6 % – égalant Claude Opus 4.6.
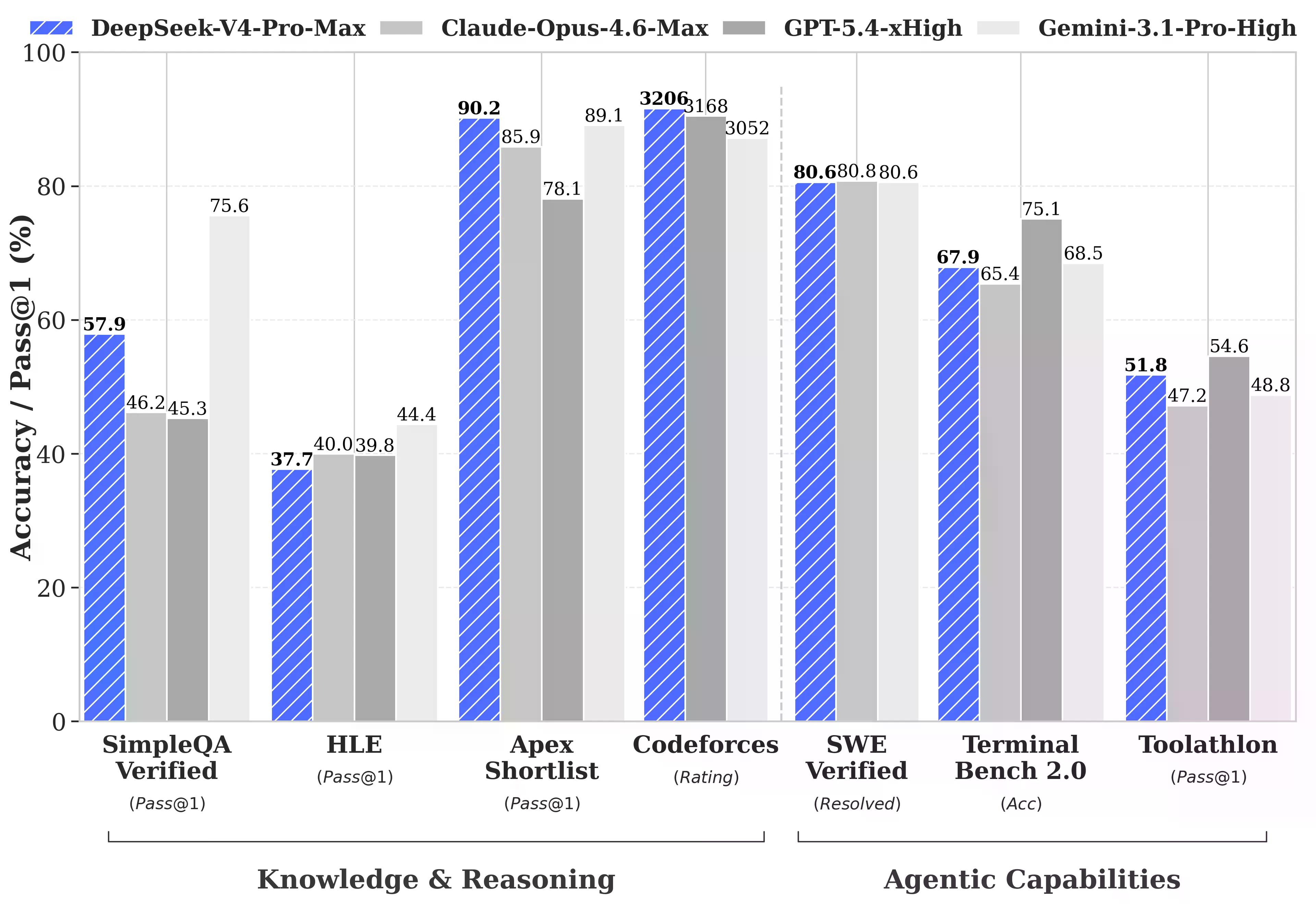
Là où il est en retrait : le benchmark multitâche MMLU-Pro (Gemini-3.1-Pro à 91,0 % contre V4-Pro à 87,5 %), le benchmark de connaissances d'experts GPQA Diamond (Gemini 94,3 contre V4-Pro 90,1), et Humanity's Last Exam, un benchmark de niveau supérieur où Gemini-3.1-Pro avec 44,4 % bat toujours le V4-Pro avec 37,7 %.
Sur le contexte long spécifiquement, V4-Pro devance les modèles open-source et bat Gemini-3.1-Pro sur le benchmark CorpusQA (un test simulant l'analyse de documents réels sur un million de jetons), mais perd face à Claude Opus 4.6 sur MRCR — un test mesurant la capacité d'un modèle à récupérer des informations spécifiques enfouies profondément dans une très longue pile.
La partie agentique est ce qui rend cette version intéressante pour les développeurs qui commercialisent réellement des produits.
V4-Pro peut fonctionner avec Claude Code, OpenCode et d'autres outils de codage basés sur l'IA. Selon une enquête interne de DeepSeek menée auprès de 85 développeurs ayant utilisé V4-Pro comme agent de codage principal, 52 % ont déclaré qu'il était prêt à être leur modèle par défaut, 39 % penchaient vers le oui, et moins de 9 % ont dit non. Les employés internes ont affirmé qu'il surpassait Claude Sonnet et approchait Claude Opus 4.5 sur les tâches de codage agentiques.
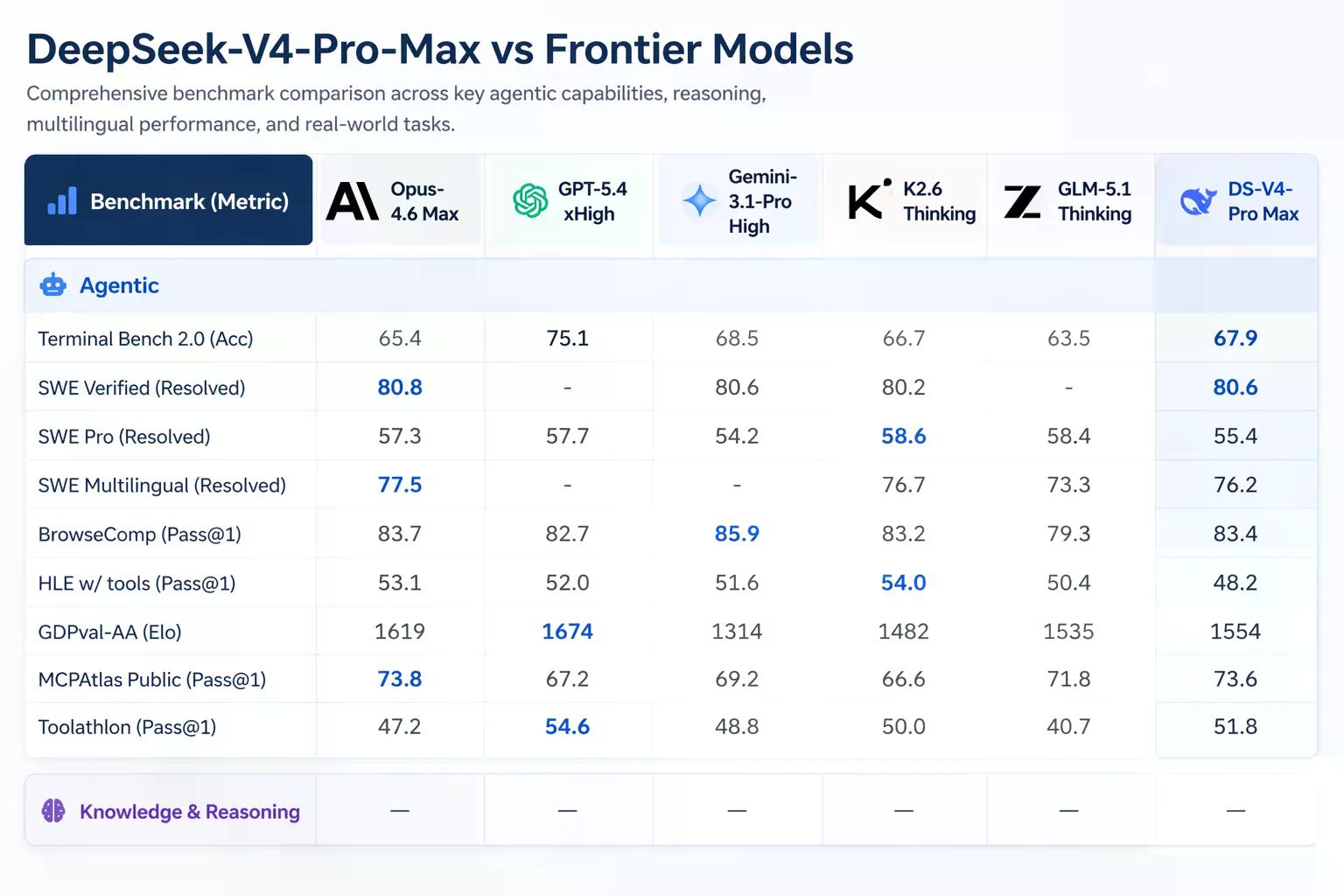
Artificial Analysis, qui réalise des évaluations indépendantes de modèles d'IA sur des tâches du monde réel, a classé V4-Pro premier parmi tous les modèles open-weight sur GDPval-AA — un benchmark testant le travail de connaissance économiquement précieux dans les domaines de la finance, du droit et de la recherche, évalué via Elo. V4-Pro-Max a obtenu 1 554 Elo, devant GLM-5.1 (1 535) et M2.7 de MiniMax (1 514). Pour référence, Claude Opus 4.6 obtient 1 619 sur le même benchmark — toujours en avance, mais l'écart se réduit.
DeepSeek V4 Pro is the #1 open weights model on GDPval-AA, our agentic real-world work tasks evaluation@deepseek_ai has released V4 Pro (1.6T total / 49B active) and V4 Flash (284B total / 13B active). V4 is DeepSeek's first new size since V3, with all intermediate models… pic.twitter.com/2kJWVrKQjF
— Artificial Analysis (@ArtificialAnlys) April 24, 2026
Le V4 de DeepSeek introduit également ce qu'on appelle la « pensée entrelacée ». Dans les modèles précédents, si vous exécutiez un agent qui effectuait plusieurs appels d'outil — par exemple, il recherchait sur le web, puis exécutait du code, puis recherchait à nouveau — le contexte de raisonnement du modèle était vidé entre les tours. À chaque nouvelle étape, le modèle devait reconstruire son modèle mental à partir de zéro. Le V4 conserve la chaîne de pensée complète à travers les appels d'outil, de sorte qu'un flux de travail d'agent en 20 étapes ne souffre pas d'amnésie à mi-parcours. Cela est plus important qu'il n'y paraît pour quiconque exécute des pipelines automatisés complexes.
Les États-Unis ont restreint les exportations de puces Nvidia haut de gamme vers la Chine depuis 2022. L'objectif déclaré était de ralentir le développement de l'IA chinoise, mais l'interdiction de puces n'a pas arrêté DeepSeek et les a plutôt poussés à inventer une architecture plus efficace et à développer une offre matérielle nationale.
DeepSeek n'a pas sorti V4 dans un vide – le domaine de l'IA a été très actif ces derniers temps : Anthropic a lancé Claude Opus 4.7 le 16 avril – un modèle que Decrypt a testé et trouvé puissant en matière de codage et de raisonnement, avec une utilisation de jetons remarquablement élevée. La veille, Anthropic disposait également de Claude Mythos, un modèle de cybersécurité qu'il déclare ne pas pouvoir publier publiquement car il est trop doué pour les attaques réseau autonomes.
Xiaomi a lancé MiMo V2.5 Pro le 22 avril, devenant entièrement multimodal – image, audio, vidéo. Il coûte 1 $ en entrée et 3 $ en sortie par million de jetons. Il égale Opus 4.6 sur la plupart des benchmarks de codage. Il y a trois mois, personne ne parlait de Xiaomi comme d'une entreprise d'IA de pointe. Maintenant, elle livre des modèles compétitifs plus rapidement que la plupart des laboratoires occidentaux.
GPT-5.5 d'OpenAI a été lancé hier avec des coûts atteignant jusqu'à 180 dollars par million de jetons de sortie dans la version Pro. Il bat V4-Pro sur Terminal Bench 2.0 (82,7 % contre 70,0 %), qui teste des flux de travail complexes d'agents en ligne de commande. Mais il coûte considérablement plus cher que V4-Pro pour des tâches équivalentes. Le même jour, Tencent a publié Hy3, un autre modèle de pointe axé sur l'efficacité.
Alors, avec tant de nouveaux modèles disponibles, la question que les développeurs se posent réellement est la suivante : quand le prix premium en vaut-il la peine ?
Pour les entreprises, le calcul a peut-être changé. Un modèle qui domine les benchmarks open-source à 1,74 $ par million de jetons d'entrée signifie que les pipelines de traitement de documents à grande échelle, de révision juridique ou de génération de code qui étaient coûteux il y a six mois sont maintenant beaucoup moins chers. Le contexte d'un million de jetons signifie que vous pouvez alimenter des bases de code entières ou des dépôts réglementaires en une seule requête au lieu de les découper en plusieurs appels.
De plus, sa nature open-source signifie qu'il peut non seulement être exécuté gratuitement sur du matériel local, mais qu'il peut également être personnalisé et amélioré en fonction des besoins et des cas d'utilisation de l'entreprise.
Pour les développeurs et les constructeurs solitaires, V4-Flash est celui à surveiller. À 0,14 $ en entrée et 0,28 $ en sortie, il est moins cher que les modèles considérés comme des options économiques il y a un an – et il gère la plupart des tâches de la version Pro. Les points de terminaison existants de DeepSeek deepseek-chat et deepseek-reasoner acheminent déjà vers V4-Flash en mode non-réflexion et réflexion respectivement, donc si vous utilisez l'API, vous l'utilisez déjà.
Les modèles sont uniquement textuels pour l'instant. DeepSeek a déclaré travailler sur des capacités multimodales, ce qui signifie que d'autres grands laboratoires, de Xiaomi à OpenAI, conservent encore cet avantage. Les deux modèles sont sous licence MIT et disponibles sur Hugging Face dès aujourd'hui. Les anciens points de terminaison deepseek-chat et deepseek-reasoner seront retirés le 24 juillet 2026.
