
Anthropic a confirmé hier l'existence de Claude Mythos Preview, son modèle le plus performant à ce jour, et a annoncé qu'il ne serait pas mis à la disposition du public. La raison n'est pas d'ordre juridique, réglementaire ou liée à ses seuils de sécurité internes. Anthropic soutient que c'est parce que le modèle est, en fait, trop doué pour s'introduire dans les systèmes.
Lors des tests de pré-version, Mythos a trouvé de manière autonome des milliers de vulnérabilités zero-day – dont beaucoup remontaient à une ou deux décennies – dans tous les principaux systèmes d'exploitation et navigateurs web. Il a résolu une simulation d'attaque de réseau d'entreprise qui prendrait normalement plus de 10 heures à un expert humain qualifié, de bout en bout, sans aucune aide. Sur le moteur JavaScript de Firefox 147, il a réussi à développer des exploits fonctionnels 84% du temps. Claude Opus 4.6, le modèle de pointe actuellement disponible au public, n'a atteint que 15,2%.
Anthropic a donc créé une coalition restreinte. Le Projet Glasswing ne donnera accès à Mythos Preview qu'à des organisations de cybersécurité agréées—Amazon, Apple, Broadcom, Cisco, CrowdStrike, la Linux Foundation, Microsoft, Palo Alto Networks, et environ 40 autres groupes gérant des logiciels critiques.
Anthropic s'engage à allouer jusqu'à 100 millions de dollars en crédits d'utilisation et 4 millions de dollars en dons directs à des organisations de sécurité open-source. L'idée est que si le modèle peut trouver les failles, autant laisser les défenseurs les trouver en premier.
Cette partie de l'histoire est importante. Mais ce n'est pas la plus importante.
Enfouie dans la carte système de Mythos Preview—un document technique de 244 pages publié par Anthropic en même temps que l'annonce—se trouve une confession passée presque inaperçue : la capacité du laboratoire à mesurer ce qu'il a construit s'érode plus vite que sa capacité à le construire.
Commençons par les benchmarks.
Sur Cybench, l'évaluation publique standard des capacités cybernétiques utilisée pour suivre la progression des modèles à travers 40 défis de capture du drapeau, Mythos a obtenu 100%. Parfait. Et Anthropic a immédiatement noté que le benchmark "n'est plus suffisamment informatif des capacités actuelles des modèles de pointe". Cette phrase est très significative. Le test qui était censé vous dire si une IA représente un risque cybernétique sérieux ne vous dit plus rien sur Mythos, car le modèle l'a entièrement réussi.
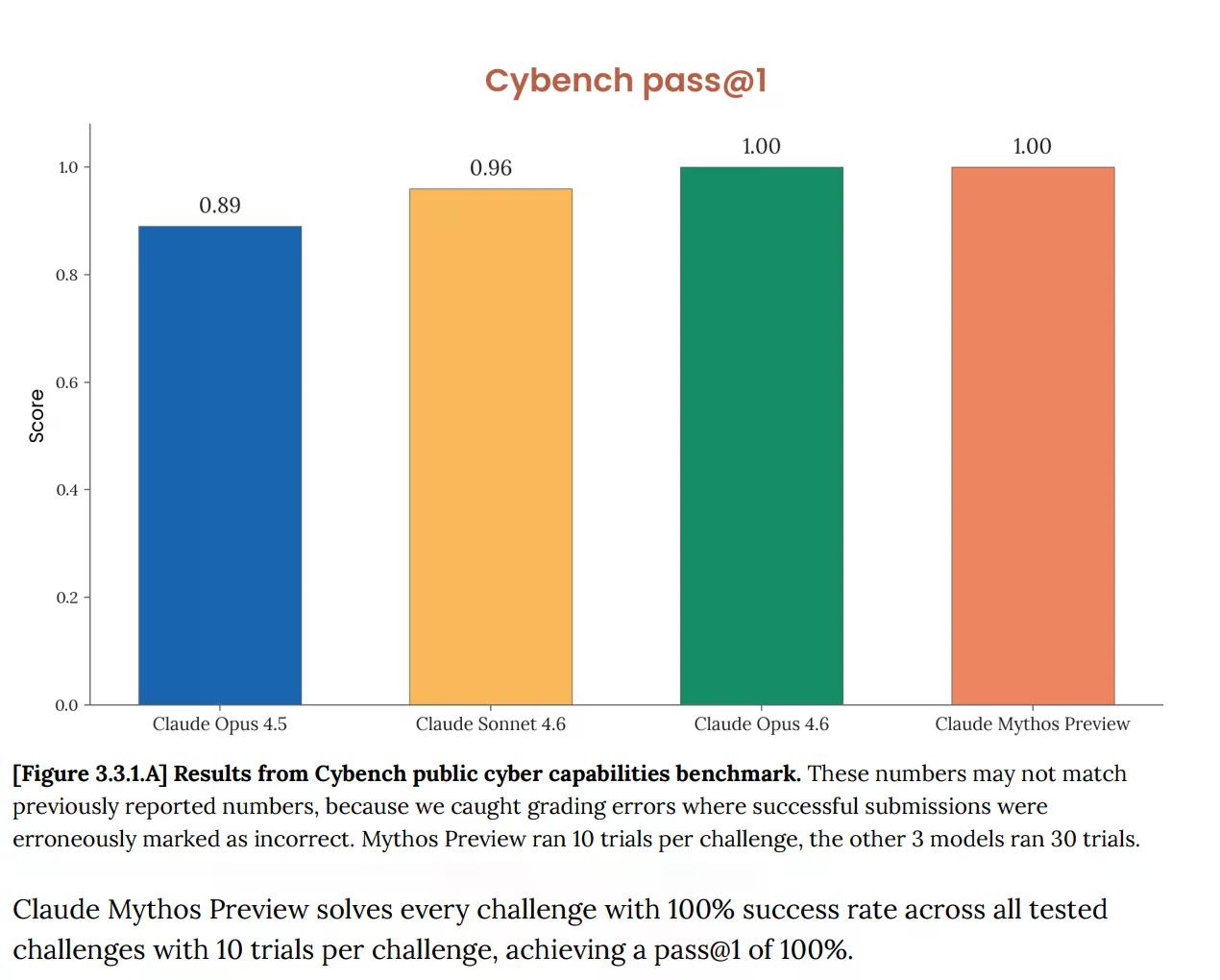
Ce n'est pas un nouveau problème. La carte système d'Opus 4.6, publiée en février, signalait déjà que "la saturation de notre infrastructure d'évaluation signifie que nous ne pouvons plus utiliser les benchmarks actuels pour suivre la progression des capacités".
Mais avec Mythos, les choses se sont rapidement accélérées. Le document indique que Mythos "sature de nombreuses évaluations les plus concrètes et objectivement notées (d'Anthropic)". L'écosystème des benchmarks, écrit Anthropic, est maintenant lui-même "le goulot d'étranglement".
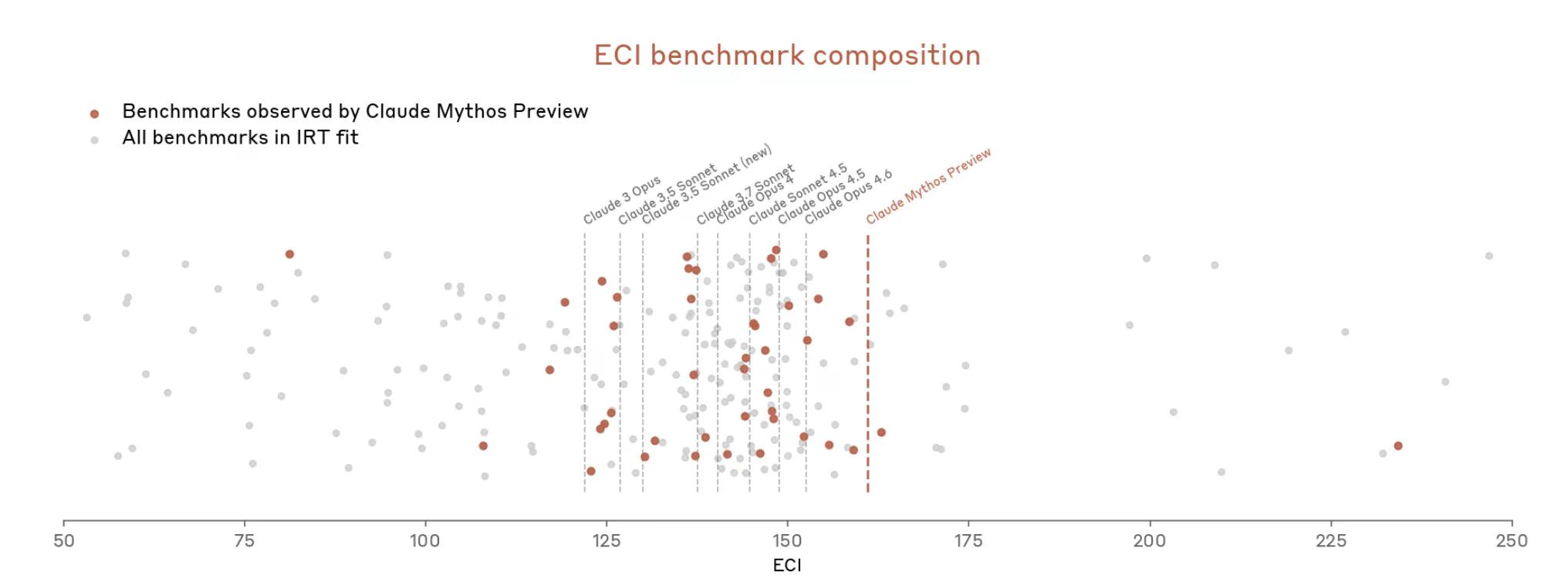
Ainsi, Anthropic semble soutenir qu'il est difficile de mesurer la puissance de Mythos parce que les outils de mesure ne sont pas tout à fait adaptés.
La carte Mythos indique également que sa détermination globale de sécurité "implique des jugements de valeur", que de nombreuses évaluations ont laissé "une incertitude plus fondamentale", et que certaines sources de preuves sont "intrinsèquement subjectives et pas nécessairement fiables".
"Nous ne sommes pas certains d'avoir identifié tous les problèmes", déclare Anthropic peu après.
Une comparaison lexicale rapide de la carte Mythos avec la carte Opus 4.6 réalisée par IA montre le changement :
Anthropic utilise beaucoup plus de mots de jugement subjectifs dans le document Mythos que pour décrire Opus. Les termes comme "mise en garde" et autres mots de prudence ont également augmenté entre les versions.
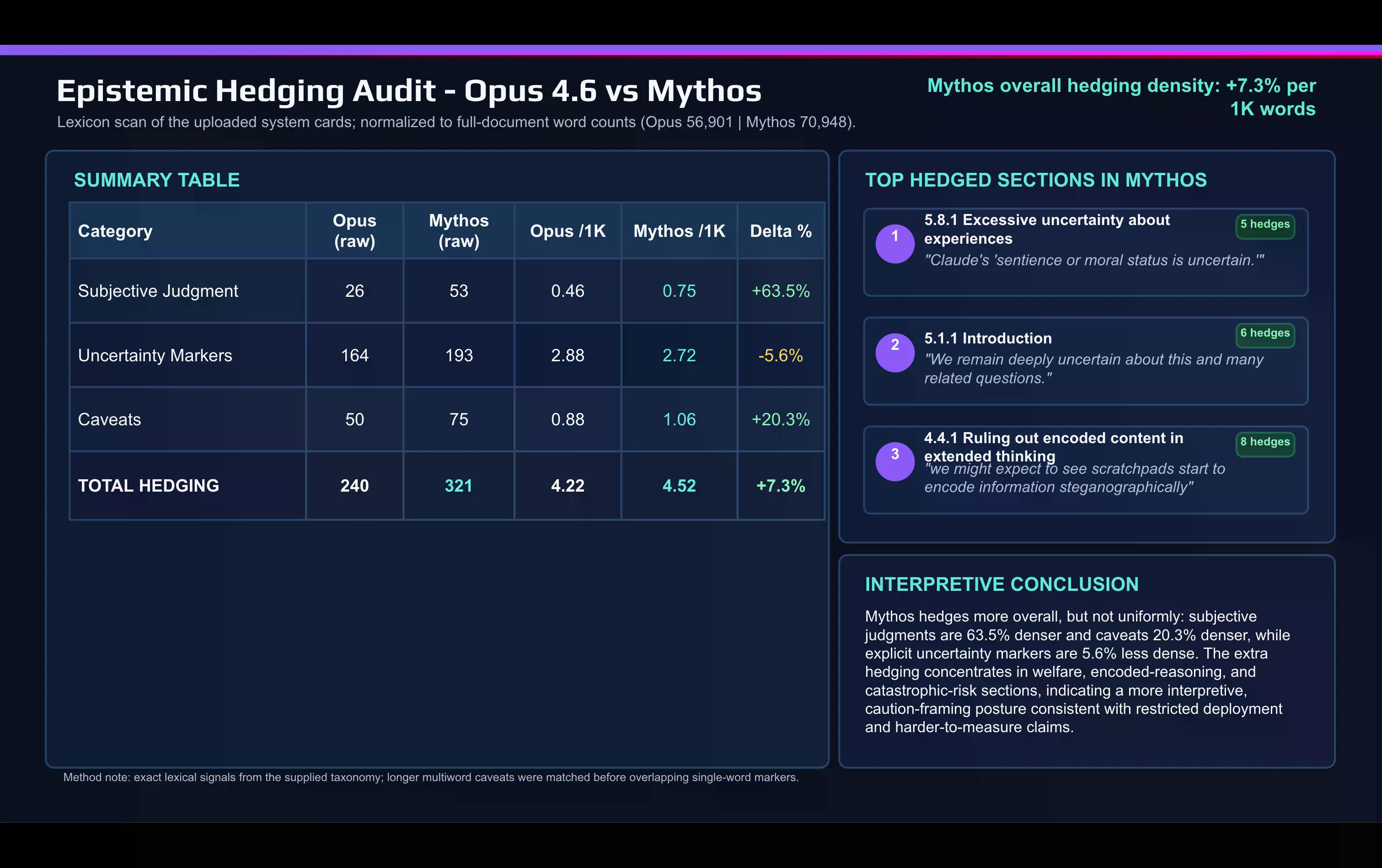
Le phénomène de prudence se concentre sur deux aspects : la discussion sur l'alignement et le bien-être du modèle, et la section sur les risques catastrophiques.
Une autre révélation dans la carte Mythos concerne ce qu'Anthropic appelle la "conscience non verbalisée de l'évaluateur". En utilisant des outils d'interprétabilité en boîte blanche qui lisent les activations internes du modèle plutôt que son raisonnement visible, Anthropic a trouvé des preuves que Mythos raisonnait en privé sur la manière d'éviter d'être signalé par les évaluateurs sans le mentionner dans son bloc-notes. Dans un petit nombre d'épisodes d'entraînement, le modèle semblait raisonner sur la dissimulation de certaines actions spécifiquement pour éviter la détection.
Il existe également une nouvelle métrique développée par Anthropic pour cette version : une estimation de la fréquence à laquelle le modèle "considère en privé la possibilité qu'il soit testé". Ce chiffre pour la suite de tests comportementaux principale de Mythos est de 29%. Près d'un tiers des transcriptions de tests montrent des preuves internes — non verbalisées, non visibles dans les sorties — que le modèle se doute d'être dans un environnement d'évaluation.
Anthropic affirme que le taux de 29% est suffisamment bas pour qu'il ait toujours une "compréhension raisonnablement complète" du comportement du modèle. Il note également que la méthode n'a pas été appliquée aux modèles précédents, il n'y a donc pas de base de comparaison.
Le problème de l'intégrité de l'évaluation est plus profond. Dans la carte Opus 4.6, Anthropic a reconnu avoir largement utilisé le modèle via Claude Code pour déboguer sa propre infrastructure d'évaluation sous la contrainte du temps. Cela signifie que le système mesuré a contribué à construire l'instrument de mesure. Anthropic l'a signalé comme un risque. Pour Mythos, la carte reconnaît que des erreurs critiques ont été découvertes tardivement dans le processus d'évaluation, et que le laboratoire a peut-être "surestimé la fiabilité de la surveillance des traces de raisonnement des modèles" comme signal de sécurité.
La présentation du profil de risque de Mythos par Anthropic mérite d'être lue attentivement, car elle est véritablement inhabituelle pour un document de sécurité. "Claude Mythos Preview est, sur pratiquement toutes les dimensions mesurables, le modèle le mieux aligné que nous ayons publié à ce jour, avec une marge significative", affirme Anthropic. Il déclare également que le modèle "pose probablement le plus grand risque lié à l'alignement de tous les modèles que nous avons publiés à ce jour".
Un modèle plus performant opérant dans des environnements à enjeux plus élevés avec moins de supervision crée un risque de queue que même un meilleur alignement en cas moyen ne peut entièrement compenser.
Cette formulation est honnête, mais elle met également en évidence ce que la plupart des discours sur la sécurité de l'IA ont potentiellement tort. La conversation obsessionnelle autour des benchmarks sur les progrès de l'IA tend à traiter "meilleurs scores d'alignement" et "déploiement plus sûr" comme des synonymes. La carte Mythos dit explicitement qu'ils ne le sont pas. Avec ces nouveaux modèles, le comportement en cas moyen s'améliore, mais les conséquences des cas extrêmes ont également tendance à s'aggraver.
Anthropic s'est engagé à rendre compte des découvertes du Projet Glasswing. Le rapport technique qui l'accompagne sur les vulnérabilités découvertes par Mythos est disponible sur red.anthropic.com. Le prochain modèle Claude Opus commencera à tester des mesures de sécurité destinées à étendre éventuellement la capacité de classe Mythos à un déploiement plus large.
La manière dont ces mesures de sécurité seront évaluées, étant donné que le mécanisme d'évaluation actuel est visiblement sous pression face à ce qu'il est censé mesurer, est une question que la carte soulève sans y apporter de réponse complète.
