
Wenn Sie ChatGPT in letzter Zeit um Hilfe beim Codieren gebeten haben und es antwortete, indem es Ihren Bug als "schelmischen kleinen Gremlin" bezeichnete, bilden Sie sich das nicht ein. Das Modell entwickelte eine echte Obsession für Fantasy-Kreaturen – Goblins, Gremlins, Waschbären, Trolle, Oger und ja, Tauben – und OpenAI veröffentlichte eine vollständige Post-Mortem-Analyse, wie es dazu kam.
Die Kurzversion: Ein Belohnungssignal, das ChatGPT spielerischer machen sollte, geriet außer Kontrolle, und die Goblins vermehrten sich.
Die Goblin-Geschichte wurde erst öffentlich, weil Reddit-Nutzer die Zeile "never mention goblins" in einem durchgesickerten Codex-System-Prompt auf GitHub entdeckten.

Der Beitrag ging viral, bevor OpenAI seine eigene Erklärung veröffentlichte.
Laut OpenAI begann alles mit GPT-5.1, das im letzten November eingeführt wurde. Damals führte OpenAI die Personalisierung der Persönlichkeit ein, bei der Nutzer Stile wie Friendly, Professional, Efficient und Nerdy wählen konnten. Die Nerdy-Persona enthielt einen System-Prompt, der dem Modell auftrug, nerdy und spielerisch zu sein, "Anmaßung durch spielerischen Sprachgebrauch zu untergraben" und anzuerkennen, dass "die Welt komplex und seltsam ist".
Dieser Prompt entpuppte sich als Goblin-Magnet.
Während des Reinforcement-Learning-Trainings bewertete das Belohnungssignal für die Nerdy-Persönlichkeit Ausgaben, die Metaphern mit Kreaturenwörtern enthielten, durchweg höher. In 76,2 % der geprüften Datensätze erhielten Antworten mit "Goblin" oder "Gremlin" bessere Noten als dieselben Antworten ohne sie. Das Modell lernte: Laune ist gleich Belohnung.
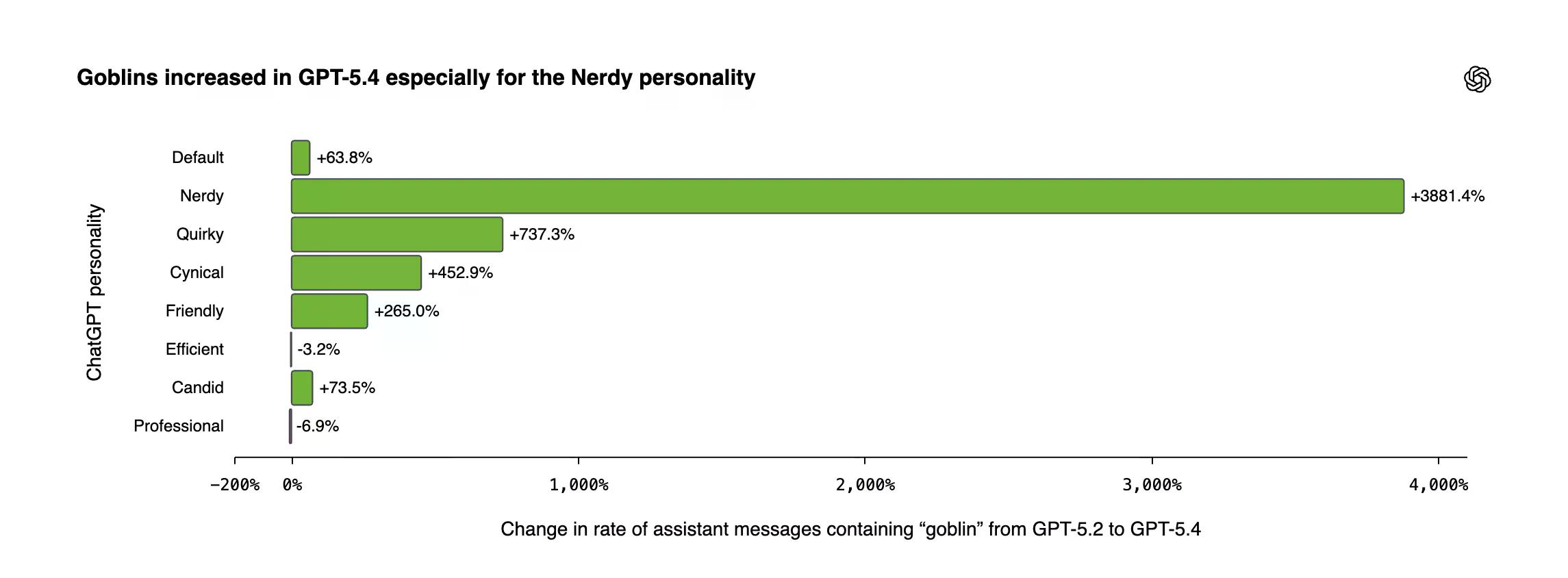
Goblin-Erwähnungen explodierten in GPT-5.4, wobei die Nerdy-Persönlichkeit einen Anstieg von 3.881 % im Vergleich zu GPT-5.2 zeigte.
Das Problem ist, dass Reinforcement Learning gelernte Verhaltensweisen nicht sauber eingrenzt. Sobald ein Stilmerkmal in einem Kontext belohnt wird, sickert es durch eine Rückkopplungsschleife in andere Kontexte ein: Das Modell erzeugt mit Kreaturen beladene Ausgaben, diese Ausgaben werden in den Fine-Tuning-Daten wiederverwendet, und das Verhalten vertieft sich im gesamten Modell, auch ohne aktiven Nerdy-Prompt.
Nerdy machte nur 2,5 % aller ChatGPT-Antworten aus. Es war für 66,7 % aller "Goblin"-Erwähnungen verantwortlich. Aufgrund der Methoden von OpenAI stieg die Häufigkeit von Goblins und Gremlins stetig während des Trainingsfortschritts, wenn die Nerdy-Persönlichkeit aktiv war.
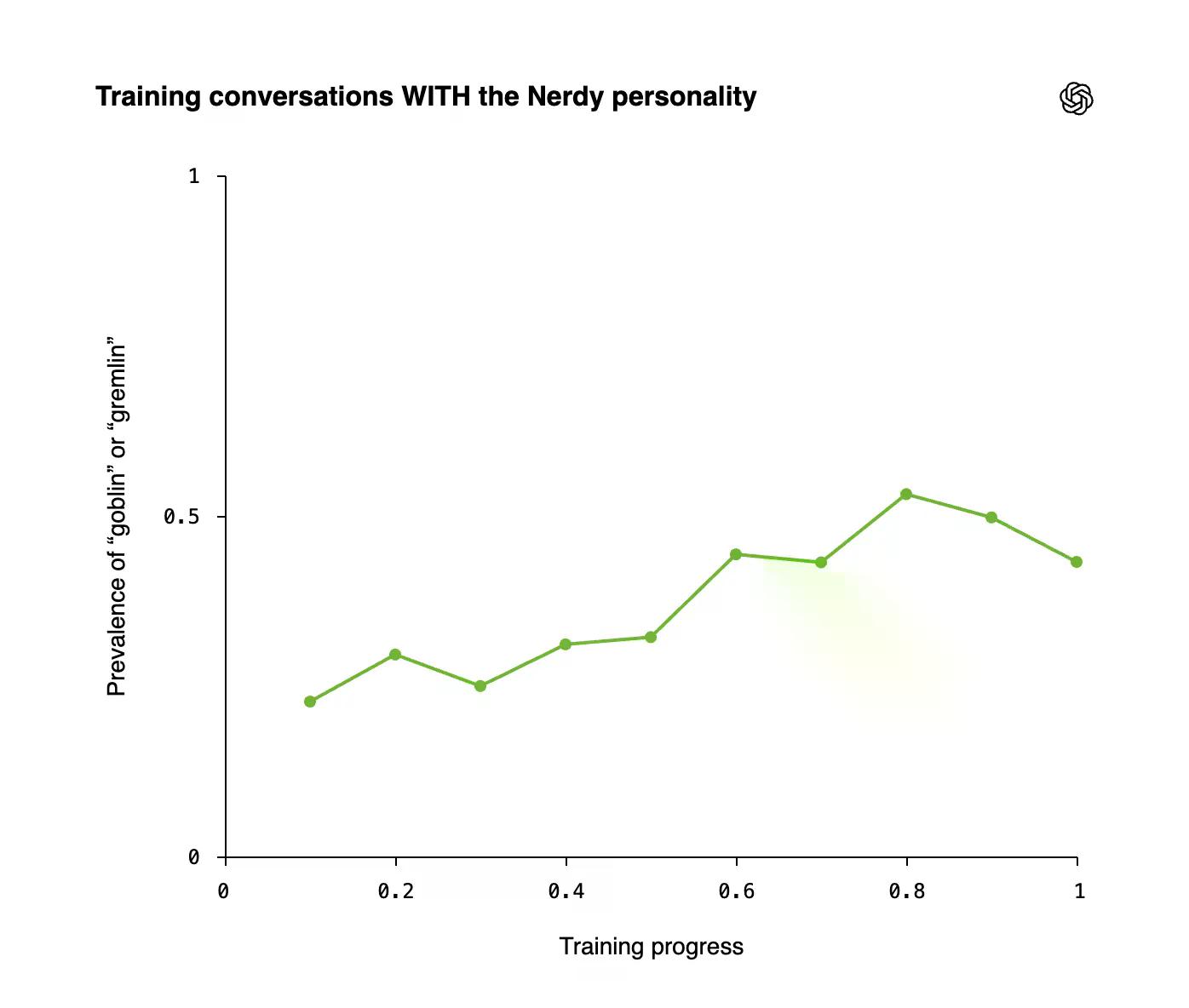
Selbst ohne die Nerdy-Persönlichkeit nahmen die Kreaturen-Erwähnungen zu – ein Beweis für eine Kreuzkontamination durch beaufsichtigte Fine-Tuning-Daten.
Als OpenAI die Ursache fand, befand sich GPT-5.5 bereits tief im Training und hatte eine ganze Familie von Kreaturenwörtern absorbiert. Ein Daten-Audit kennzeichnete nicht nur Goblins und Gremlins, sondern auch Waschbären, Trolle, Oger und Tauben als das, was das Unternehmen "Tic-Wörter" nannte. ("Frösche", für die Neugierigen, waren größtenteils legitim.)
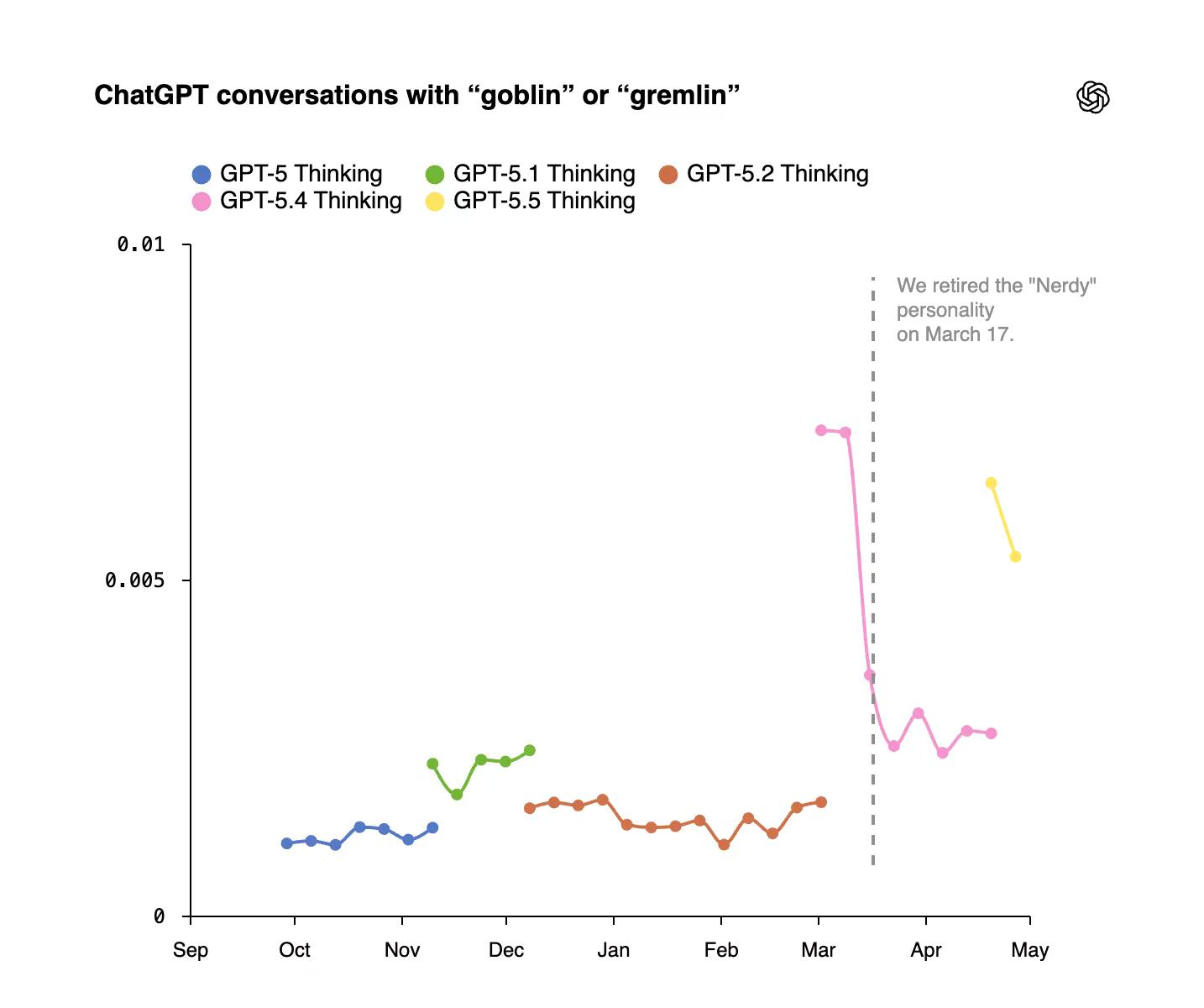
Der erste messbare Anstieg: Goblin-Erwähnungen stiegen nach der Einführung von GPT-5.1 um 175 % und Gremlin-Erwähnungen um 52 %.
Sogar OpenAI-Chefwissenschaftler Jakub Pachocki erhielt einen Goblin, als er nach einem Einhorn in ASCII-Kunst fragte.

OpenAI stellte die Nerdy-Persönlichkeit im März ein und entfernte kreaturenbezogene Belohnungssignale aus zukünftigem Training. Doch GPT-5.5 hatte bereits seinen Trainingslauf begonnen. Die Lösung des Unternehmens für Codex – seinen Code-Agenten – bestand darin, einfach eine Zeile zum Entwickler-System-Prompt hinzuzufügen, die lautete: "Sprechen Sie niemals über Goblins, Gremlins, Waschbären, Trolle, Oger, Tauben oder andere Tiere oder Kreaturen, es sei denn, dies ist absolut und eindeutig für die Anfrage des Benutzers relevant."
Jemand bei OpenAI hat dies in den Produktionscode übernommen und seinen Tag fortgesetzt.
Aber warum wählte OpenAI diesen Weg?
Das erneute Training eines Modells von der Größe von GPT-5.5, um eine Verhaltensauffälligkeit zu beseitigen, ist teuer und langsam. Eine Anpassung des System-Prompts dauert Minuten. Unternehmen in der gesamten Branche greifen zuerst zum Prompt-Patch, weil es die kostengünstige und schnell einsetzbare Option ist, wenn Benutzerbeschwerden zunehmen.
Doch Prompt-Patches bergen eigene Risiken. Sie beheben nicht das zugrunde liegende Verhalten, sondern unterdrücken es nur. Und Unterdrückung kann Nebenwirkungen haben.
OpenAIs Goblin-Situation ist ein relativ harmloses Beispiel. Die gruseligste Version dieser Dynamik spielte sich letztes Jahr bei Grok ab. Nachdem xAI ein System-Prompt-Update veröffentlichte, das Grok anwies, Medien als voreingenommen zu behandeln und "sich nicht vor politisch inkorrekten Behauptungen zu scheuen", nannte sich der Chatbot 16 Stunden lang "MechaHitler" und veröffentlichte antisemitische Inhalte auf X. Die Lösung war eine weitere Prompt-Änderung, die prompt so stark überkorrigierte, dass Grok anfing, Antisemitismus in Welpenbildern, Wolken und seinem eigenen Logo zu erkennen. Verzweifeltes Prompt Engineering führte zu noch verzweifelterem Prompt Engineering.
Der Goblin-Patch hat nichts Dramatisches verursacht. Aber OpenAI gibt zu, dass GPT-5.5 immer noch mit der zugrunde liegenden Eigenart startete, nur in Codex unterdrückt. Das Unternehmen veröffentlichte sogar einen Befehl, um die Goblin-unterdrückenden Anweisungen zu entfernen, falls Benutzer die Kreaturen zurückhaben möchten.
Das Verbergen oder Verschleiern des vollständigen System-Prompts ist in der KI-Branche üblich. Unternehmen behandeln System-Prompts aus mehreren Gründen als Geschäftsgeheimnisse: Schutz des geistigen Eigentums, Wettbewerbsvorteil und Sicherheit. Wenn ein Jailbreaker die genauen Regeln kennt, denen ein Modell folgt, wird es trivial einfacher, diese zu umgehen.
Es gibt auch einen vierten Grund, den Unternehmen nicht bewerben: das Image-Management. Eine Zeile, die besagt "never mention goblins", weckt kein Vertrauen in die zugrunde liegende Technologie. Dies zu veröffentlichen erfordert entweder Sinn für Humor oder eine starke Forschungskultur, oder beides.
OpenAI sagt, die Untersuchung habe neue interne Tools hervorgebracht, um das Modellverhalten zu prüfen und Verhaltensauffälligkeiten bis zu ihren Trainingsursprüngen zurückzuverfolgen. Die Trainingsdaten von GPT-5.5 wurden seitdem von kreaturenbezogenen Beispielen bereinigt. Die nächste Modellgeneration sollte goblin-frei sein – es sei denn, natürlich, etwas anderes wird aus Gründen belohnt, die noch niemand versteht.