
Nvidia-CEO Jensen Huang war letzte Woche zu Gast im Podcast von Lex Fridman und sagte unverblümt: „Ich glaube, wir haben AGI erreicht.“ Zwei Tage später veröffentlichte die strengste Testreihe in der KI-Forschung ihren neuesten Benchmark für allgemeine künstliche Intelligenz – und jedes Frontier-Modell erzielte weniger als 1 %.
Die ARC Prize Foundation hat diese Woche ARC-AGI-3 veröffentlicht, und die Ergebnisse sind brutal. Googles Gemini 3.1 Pro führte das Feld mit 0,37 % an. OpenAIs GPT-5.4 erreichte 0,26 %. Anthropics Claude Opus 4.6 schaffte 0,25 %, während xAIs Grok-4.20 exakt null Punkte erzielte. Menschen hingegen lösten 100 % der Umgebungen.
Dies ist kein Quiz oder Programmiertest, nicht einmal extrem schwierige Fragen auf PhD-Niveau. ARC-AGI-3 ist etwas völlig anderes als alles, womit die KI-Industrie bisher konfrontiert war.
Der Benchmark wurde von François Chollets und Mike Knoops Stiftung entwickelt, die ein eigenes Spielestudio gründete und 135 originelle interaktive Umgebungen von Grund auf neu erstellte. Die Idee ist, einen KI-Agenten in eine unbekannte, spielähnliche Welt zu setzen, ohne Anweisungen, ohne definierte Ziele und ohne Beschreibung der Regeln. Der Agent muss erforschen, herausfinden, was er tun soll, einen Plan formulieren und ihn ausführen.
Wenn das wie etwas klingt, das jedes fünfjährige Kind tun kann, beginnen Sie, das Problem zu verstehen. Wenn Sie sehen möchten, ob Sie besser sind als KI, können Sie die gleichen Spiele, die im Test vorkommen, über diesen Link spielen. Wir haben eines ausprobiert; es war anfangs seltsam, aber nach ein paar Sekunden hat man den Dreh raus.
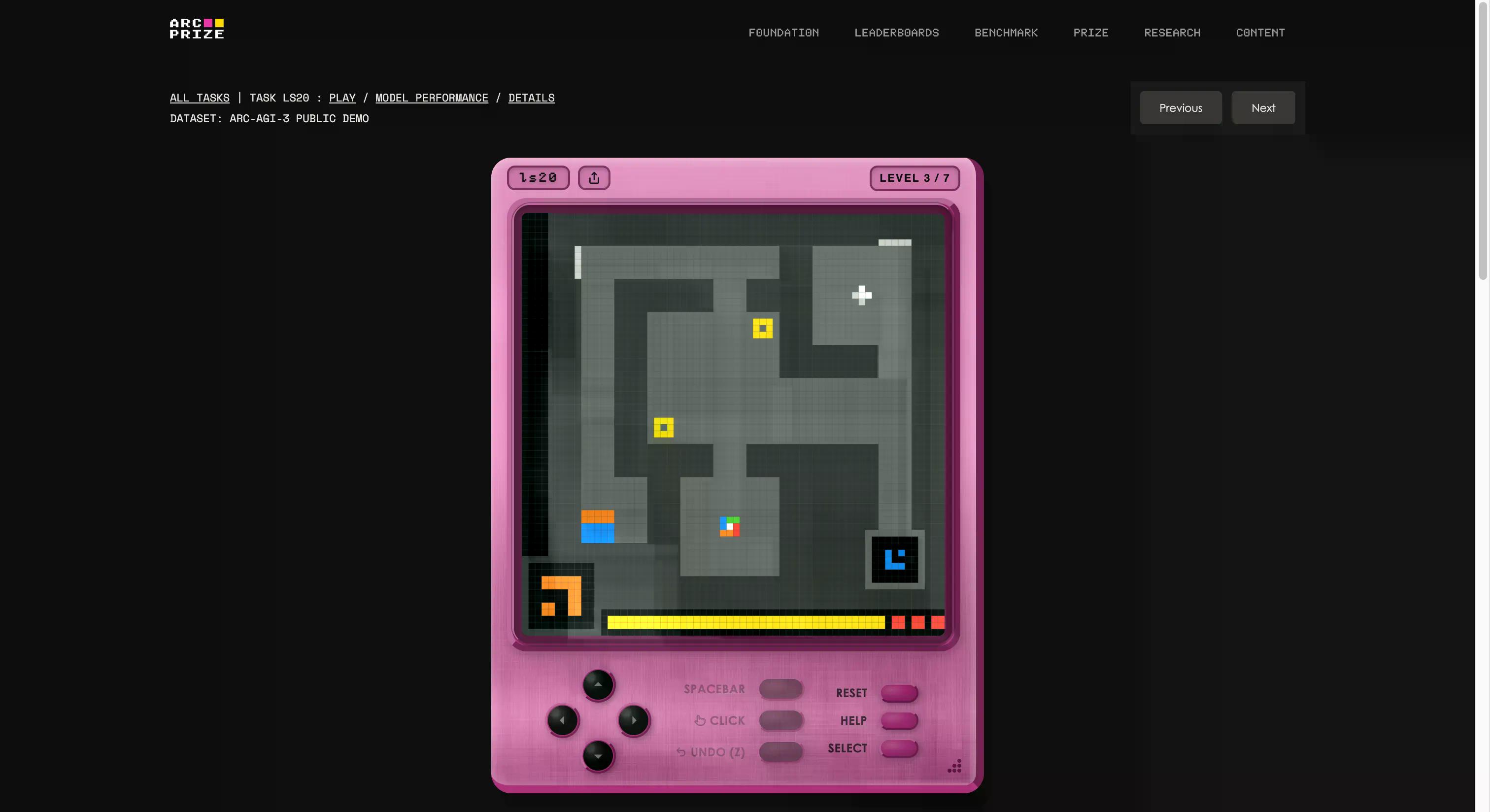
Es ist auch das deutlichste Beispiel dafür, wofür das „G“ in AGI steht. Wenn man generalisiert, ist man in der Lage, neues Wissen (wie ein seltsames Spiel funktioniert) zu schaffen, ohne zuvor darauf trainiert worden zu sein.
Frühere ARC-Versionen testeten statische visuelle Rätsel – ein Muster zeigen, das nächste vorhersagen. Sie waren anfangs schwer. Dann warfen die Labore Rechenleistung und Training darauf, bis die Benchmarks praktisch nutzlos wurden. ARC-AGI-1, 2019 eingeführt, unterlag Testzeit-Training und Reasoning-Modellen. ARC-AGI-2 hielt etwa ein Jahr, bevor Gemini 3.1 Pro 77,1 % erreichte. Die Labore sind sehr gut darin, Benchmarks zu sättigen, gegen die sie trainieren können.
Version 3 wurde speziell entwickelt, um dies zu verhindern. Da 110 der 135 Umgebungen privat gehalten werden – 55 semi-privat für API-Tests, 55 vollständig für den Wettbewerb gesperrt – gibt es keinen Datensatz zum Auswendiglernen. Man kann sich nicht mit Brute-Force durch eine neuartige Spiellogik kämpfen, die man noch nie gesehen hat.
Die Bewertung ist auch kein Bestehen/Nichtbestehen. ARC-AGI-3 verwendet, was die Stiftung RHAE nennt – Relative Human Action Efficiency. Die Basis ist die zweitbeste menschliche Leistung im ersten Durchgang. Eine KI, die zehnmal so viele Aktionen wie ein Mensch benötigt, erreicht für dieses Level 1 %, nicht 10 %. Die Formel quadriert die Strafe für Ineffizienz. Herumirren, Rückschritte machen und sich ratend zu einer Antwort durchschlagen, wird hart bestraft.
Der beste KI-Agent in der einmonatigen Entwickler-Vorschau erzielte 12,58 %. Frontier-LLMs, die über die offizielle API getestet wurden, ohne kundenspezifische Tools, knackten nicht einmal 1 %. Gewöhnliche Menschen lösten alle 135 Umgebungen ohne vorheriges Training und ohne Anweisungen. Wenn das der Maßstab ist, dann erreichen die derzeitigen Modelle diesen nicht.
Es gibt hier eine echte methodologische Debatte. Der Bericht von ARC besagt, dass ein von Duke entwickeltes kundenspezifisches Tool Claude Opus 4.6 von 0,25 % auf 97,1 % in einer einzelnen Umgebungsvariante namens TR87 gepusht hat. Das bedeutet nicht, dass Claude insgesamt 97,1 % bei ARC-AGI-3 erzielt hat; sein offizieller Benchmark-Wert blieb 0,25 %, aber die Verschiebung ist dennoch bemerkenswert.
Der offizielle Benchmark füttert Agenten mit JSON-Code, nicht mit visuellen Informationen. Das ist entweder ein methodologischer Fehler oder ein Beweis dafür, dass die heutigen Modelle besser darin sind, menschenfreundliche Informationen zu verarbeiten als rohe strukturierte Daten. Chollets Stiftung hat die Debatte anerkannt, ändert aber das Format nicht.
„Die Wahrnehmung des Frame-Inhalts und das API-Format sind keine limitierenden Faktoren für die Leistung von Frontier-Modellen bei ARC-AGI-3“, heißt es in dem Papier. Mit anderen Worten, sie scheinen die Vorstellung abzulehnen, dass Modelle versagen, weil sie die Aufgaben nicht richtig „sehen“ können, und argumentieren stattdessen, dass die Wahrnehmung bereits ausreichend ist – und die eigentliche Lücke in der Argumentation und Generalisierung liegt.
Der AGI-Realitätscheck kam in einer Woche, in der die Hype-Maschine auf Hochtouren lief. Neben Huangs Kommentar nannte Arm seinen neuen Rechenzentrums-Chip den „AGI CPU“. Sam Altman von OpenAI hat gesagt, sie hätten „im Grunde AGI gebaut“, und Microsoft vermarktet bereits ein Labor, das sich auf den Bau von ASI konzentriert: Eine Weiterentwicklung dessen, was nach Erreichen von AGI kommt. Der Begriff wird, so scheint es, so lange gedehnt, bis er bedeutet, was kommerziell gerade passt.
Chollets Position ist einfacher. Wenn ein normaler Mensch ohne Anweisungen etwas tun kann und Ihr System nicht, dann haben Sie keine AGI – Sie haben eine sehr teure Autovervollständigung, die viel Hilfe benötigt.
Der ARC Prize 2026 bietet 2 Millionen US-Dollar in drei Wettbewerbskategorien, die alle auf Kaggle stattfinden. Jede Gewinnerlösung muss Open Source sein. Die Uhr tickt, und im Moment sind die Maschinen noch nicht einmal annähernd so weit.