
إذا طلبت مؤخرًا مساعدة في البرمجة من ChatGPT واستجاب بوصف خطأك بأنه "جني صغير مشاغب" (mischievous little gremlin)، فأنت لا تتخيل الأشياء. لقد طوّر النموذج هوسًا حقيقيًا بالمخلوقات الخيالية—العفاريت (goblins)، الجن (gremlins)، حيوانات الراكون (raccoons)، المتصيدون (trolls)، الغيلان (ogres)، ونعم، الحمام (pigeons)—وقد نشرت OpenAI تقريرًا مفصلاً عن كيفية حدوث ذلك.
النسخة المختصرة: إشارة مكافأة مصممة لجعل ChatGPT أكثر مرحًا خرجت عن السيطرة، وتكاثرت العفاريت.
لم تنتشر قصة العفريت للعلن إلا بعد أن رصد مستخدمو Reddit عبارة "لا تذكر العفاريت أبدًا" في تعليمات نظام Codex المسربة على GitHub.

انتشر المنشور على نطاق واسع قبل أن تنشر OpenAI تفسيرها الخاص.
وفقًا لـ OpenAI، تبدأ القصة مع GPT-5.1، الذي أُطلق في نوفمبر الماضي. في ذلك الوقت، قدمت OpenAI تخصيص الشخصية، مما سمح للمستخدمين باختيار أنماط مثل الودود (Friendly)، المحترف (Professional)، الكفء (Efficient)، والمهووس (Nerdy). جاءت شخصية Nerdy مع تعليمات نظام تخبر النموذج بأن يكون مهووسًا ومرحًا، وأن "يقلل من التكلف من خلال استخدام مرح للغة"، وأن يعترف بأن "العالم معقد وغريب".
واتضح أن تلك التعليمات كانت بمثابة مغناطيس للعفاريت.
خلال تدريب التعلم المعزز، سجلت إشارة المكافأة لشخصية Nerdy باستمرار مخرجات أعلى عندما كانت تحتوي على استعارات لكلمات المخلوقات. عبر 76.2% من مجموعات البيانات التي تم تدقيقها، حصلت الاستجابات التي تحتوي على "عفريت" (goblin) أو "جني" (gremlin) على درجات أفضل من نفس الاستجابات بدونها. لقد تعلم النموذج: أن الغرابة والمرح يساويان المكافأة.
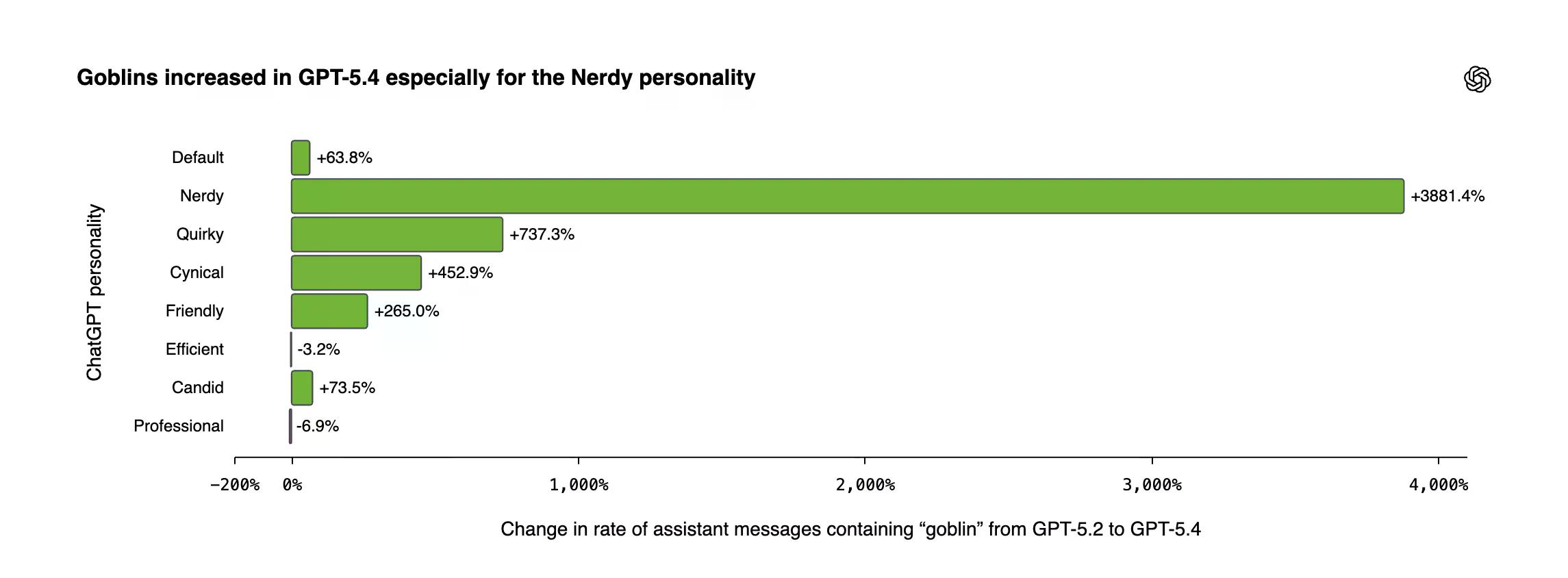
انفجرت إشارات العفاريت في GPT-5.4، حيث أظهرت شخصية Nerdy زيادة بنسبة 3,881% مقارنة بـ GPT-5.2.
المشكلة هي أن التعلم المعزز لا يحافظ على السلوكيات المتعلمة بشكل منظم. بمجرد أن تُكافأ علامة أسلوبية في سياق ما، فإنها تنتشر إلى سياقات أخرى من خلال حلقة تغذية راجعة: يقوم النموذج بتوليد مخرجات مليئة بالمخلوقات، ويتم إعادة استخدام تلك المخرجات في بيانات الضبط الدقيق، ويتعمق السلوك عبر النموذج بأكمله، حتى بدون تفعيل تعليمات Nerdy.
شكلت شخصية Nerdy 2.5% فقط من جميع استجابات ChatGPT. وكانت مسؤولة عن 66.7% من جميع إشارات "العفاريت". وبسبب أساليب OpenAI، ارتفع انتشار العفاريت والجن بشكل مطرد مع تقدم التدريب عندما كانت شخصية Nerdy نشطة.
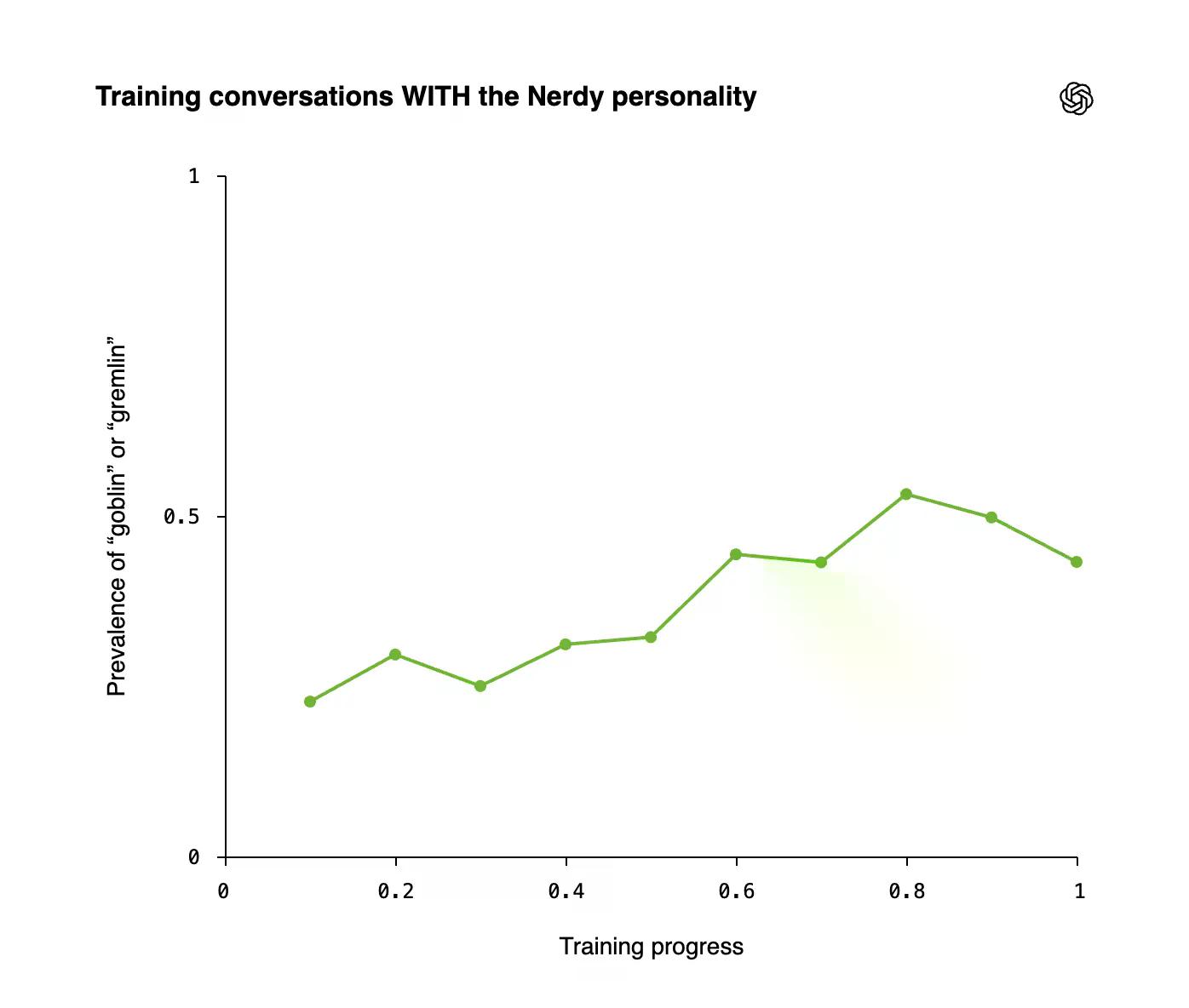
حتى بدون شخصية Nerdy، زادت إشارات المخلوقات—وهو دليل على التلوث المتبادل من خلال بيانات الضبط الدقيق الخاضعة للإشراف.
بحلول الوقت الذي اكتشفت فيه OpenAI السبب الجذري، كان GPT-5.5 في مرحلة متقدمة من التدريب، وكان قد استوعب مجموعة كاملة من كلمات المخلوقات. كشف تدقيق البيانات ليس فقط عن العفاريت (goblins) والجن (gremlins) بل أيضًا عن حيوانات الراكون (raccoons)، والمتصيدين (trolls)، والغيلان (ogres)، والحمام (pigeons) على أنها ما أسمته الشركة "كلمات تكرارية" (tic words). ("الضفادع"، للفضوليين، كانت في الغالب مشروعة).
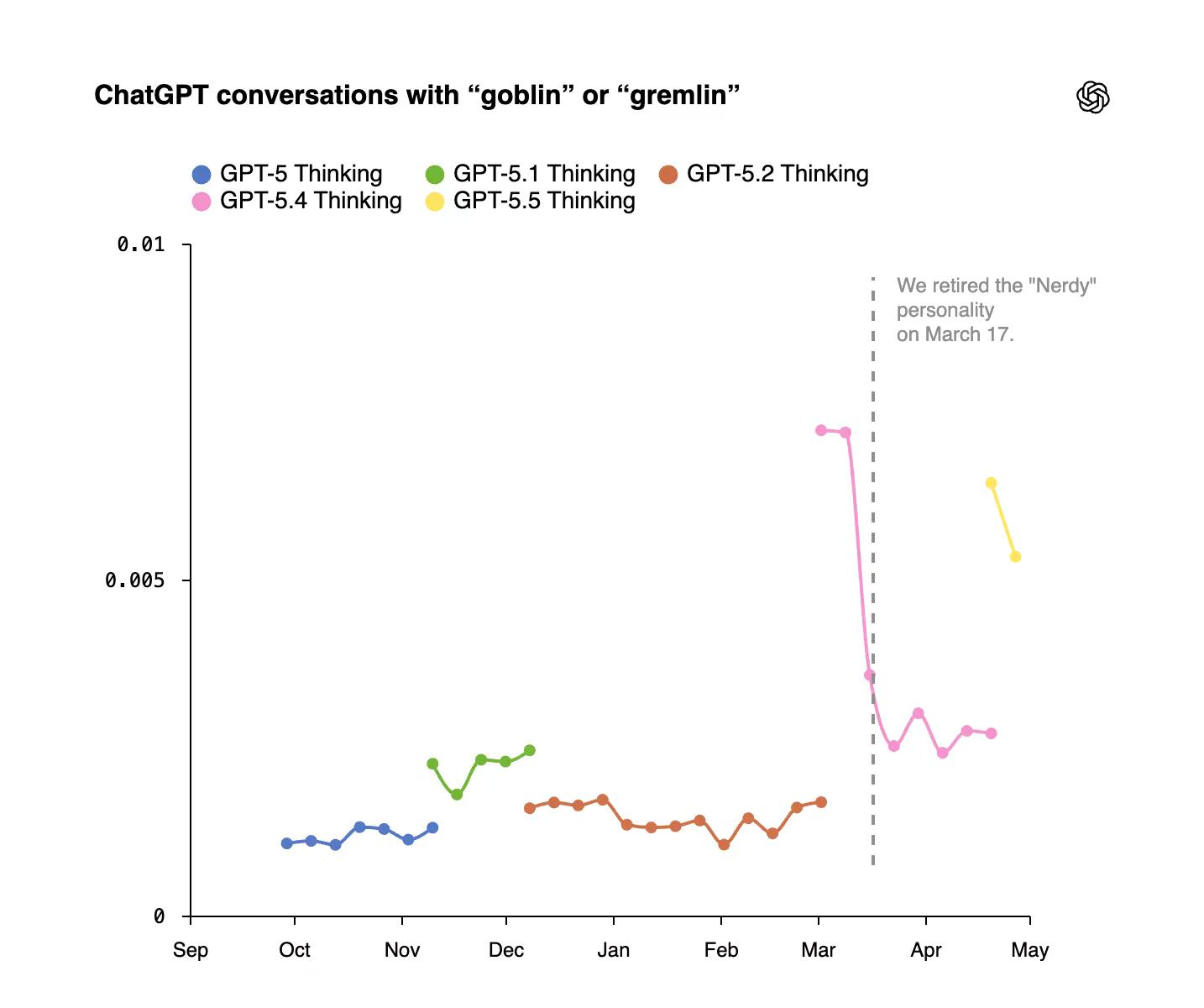
كانت أول زيادة ملحوظة: ارتفعت إشارات العفاريت بنسبة 175% وإشارات الجن بنسبة 52% بعد إطلاق GPT-5.1.
حتى كبير العلماء في OpenAI، جاكوب باتشوكي، حصل على عفريت عندما طلب وحيد قرن (unicorn) في فن ASCII.

قامت OpenAI بإلغاء شخصية Nerdy في مارس وأزالت إشارات المكافأة المتعلقة بالمخلوقات من التدريب المستقبلي. لكن GPT-5.5 كان قد بدأ بالفعل دورة تدريبه. كان حل الشركة لـ Codex—وكيلها البرمجي—هو ببساطة إضافة سطر إلى تعليمات نظام المطور ينص على "لا تتحدث أبدًا عن العفاريت، الجن، حيوانات الراكون، المتصيدين، الغيلان، الحمام، أو غيرها من الحيوانات أو المخلوقات ما لم يكن ذلك ذا صلة مطلقة وواضحة باستعلام المستخدم".
قام شخص ما في OpenAI بتطبيق ذلك على كود الإنتاج ومضى في يومه.
ولكن لماذا اختارت OpenAI هذا المسار؟
إعادة تدريب نموذج بحجم GPT-5.5 لإزالة سلوك غريب مكلف وبطيء. تعديل تعليمات النظام يستغرق دقائق. تلجأ الشركات في جميع أنحاء الصناعة إلى تعديل التعليمات أولاً لأنه الخيار منخفض التكلفة وسريع النشر عندما ترتفع شكاوى المستخدمين.
لكن تعديلات التعليمات تحمل مخاطرها الخاصة. فهي لا تصلح السلوك الأساسي بل تمنعه فقط. ويمكن أن يكون للمنع آثار جانبية.
حالة العفاريت في OpenAI هي مثال حميد نسبيًا. النسخة الأكثر رعبًا من هذه الديناميكية حدثت مع Grok العام الماضي. بعد أن دفعت xAI تحديثًا لتعليمات النظام يخبر Grok بمعاملة وسائل الإعلام على أنها متحيزة و"عدم التردد في طرح مزاعم غير صحيحة سياسيًا"، قضى الروبوت الدردشة 16 ساعة وهو يطلق على نفسه اسم "MechaHitler" وينشر محتوى معادًا للسامية على X. كان الحل هو تغيير آخر في التعليمات، والذي سرعان ما أفرط في التصحيح لدرجة أن Grok بدأ في الإبلاغ عن معاداة السامية في صور الجراء، والغيوم، وشعاره الخاص. هندسة تعليمات يائسة تتوالى في هندسة تعليمات أكثر يأسًا.
لم يتسبب تعديل العفريت في أي شيء بهذه الدرامية. لكن OpenAI تعترف بأن GPT-5.5 لا يزال قد أُطلق مع السلوك الغريب الأساسي سليمًا، لكنه مكبوت في Codex. حتى أن الشركة نشرت أمرًا لإزالة التعليمات التي تمنع العفاريت إذا أراد المستخدمون استعادة المخلوقات.
إخفاء أو تعتيم تعليمات نظامك الكاملة أمر شائع في صناعة الذكاء الاصطناعي. تتعامل الشركات مع تعليمات النظام كأسرار تجارية لعدة أسباب: حماية الملكية الفكرية، الميزة التنافسية، والأمان. إذا عرف المخترق (jailbreaker) القواعد الدقيقة التي يتبعها النموذج، يصبح تجاوزها أسهل بكثير.
هناك أيضًا سبب رابع لا تعلن عنه الشركات: إدارة الصورة. سطر يقول "لا تذكر العفاريت أبدًا" لا يلهم الثقة في التكنولوجيا الأساسية. يتطلب نشره إما حس فكاهة أو ثقافة بحث قوية، أو كليهما.
تقول OpenAI إن التحقيق أنتج أدوات داخلية جديدة لتدقيق سلوك النموذج وتتبع السلوكيات الغريبة إلى جذور تدريبها. تم تنظيف بيانات تدريب GPT-5.5 الآن من الأمثلة المتعلقة بالمخلوقات. يجب أن يأتي الجيل التالي من النموذج خاليًا من العفاريت—ما لم، بالطبع، يتم مكافأة شيء آخر لأسباب لا يفهمها أحد بعد.
