
أكدت شركة أنثروبيك أمس عن وجود Claude Mythos Preview، وهو النموذج الأكثر قدرة لها حتى الآن، وأعلنت أنها لن تتيحه للجمهور. السبب ليس قانونيًا، ولا تنظيميًا، ولا يتعلق بحدود الأمان الداخلية للشركة. تجادل أنثروبيك بأن السبب هو أن النموذج، ببساطة، جيد جدًا في اختراق الأشياء.
في الاختبارات التي سبقت الإطلاق، عثر ميثوس تلقائيًا على آلاف الثغرات الأمنية من نوع (zero-day)—الكثير منها يعود إلى عقد أو عقدين من الزمن—في جميع أنظمة التشغيل الرئيسية وجميع متصفحات الويب الكبرى. لقد حل هجومًا على شبكة شركة محاكية كان يستغرق عادةً أكثر من 10 ساعات ليقوم به خبير بشري ماهر، من البداية إلى النهاية، ودون توجيه. على محرك جافا سكريبت الخاص بـ Firefox 147، نجح في تطوير استغلالات (exploits) وظيفية بنسبة 84% من المرات. بينما حقق Claude Opus 4.6، النموذج الرائد المتاح حاليًا للجمهور، نسبة 15.2%.
لذا، قامت أنثروبيك بتشكيل تحالف مقيد بدلاً من ذلك. سيمنح مشروع Glasswing الوصول إلى Mythos Preview فقط لمنظمات الأمن السيبراني المعتمدة—مثل أمازون، آبل، برودكوم، سيسكو، كراودسترايك، مؤسسة لينكس، مايكروسوفت، بالو ألتو نيتوركس، وحوالي 40 مجموعة أخرى تقوم بصيانة البرمجيات الحيوية.
تلتزم أنثروبيك بتقديم ما يصل إلى 100 مليون دولار في شكل أرصدة استخدام و4 ملايين دولار كتبرعات مباشرة لمنظمات الأمن مفتوحة المصدر. الفكرة هي أنه إذا كان النموذج يستطيع العثور على الثغرات، فليسمح للمدافعين بالعثور عليها أولاً.
هذا الجزء من القصة مهم. لكنه ليس الجزء الأكثر أهمية.
مدفونًا داخل بطاقة نظام Mythos Preview—وثيقة تقنية مكونة من 244 صفحة نشرتها أنثروبيك جنبًا إلى جنب مع الإعلان—هناك اعتراف كاد يمر دون أن يلاحظه أحد: قدرة المختبر على قياس ما بناه تتآكل أسرع من قدرته على بنائه.
لنبدأ بالمعايير.
على Cybench، التقييم العام القياسي للقدرات السيبرانية المستخدم لتتبع تقدم النموذج عبر 40 تحديًا من تحديات "الاستيلاء على العلم" (capture-the-flag)، سجل ميثوس 100%. مثالي. ولاحظت أنثروبيك فورًا أن المعيار "لم يعد يقدم معلومات كافية عن قدرات النماذج الرائدة الحالية". هذه الجملة تحمل الكثير من المعنى. الاختبار الذي كان من المفترض أن يخبرك ما إذا كان الذكاء الاصطناعي يشكل خطرًا سيبرانيًا جادًا لا يخبرك الآن شيئًا عن ميثوس على الإطلاق، لأن النموذج اجتازه بالكامل.
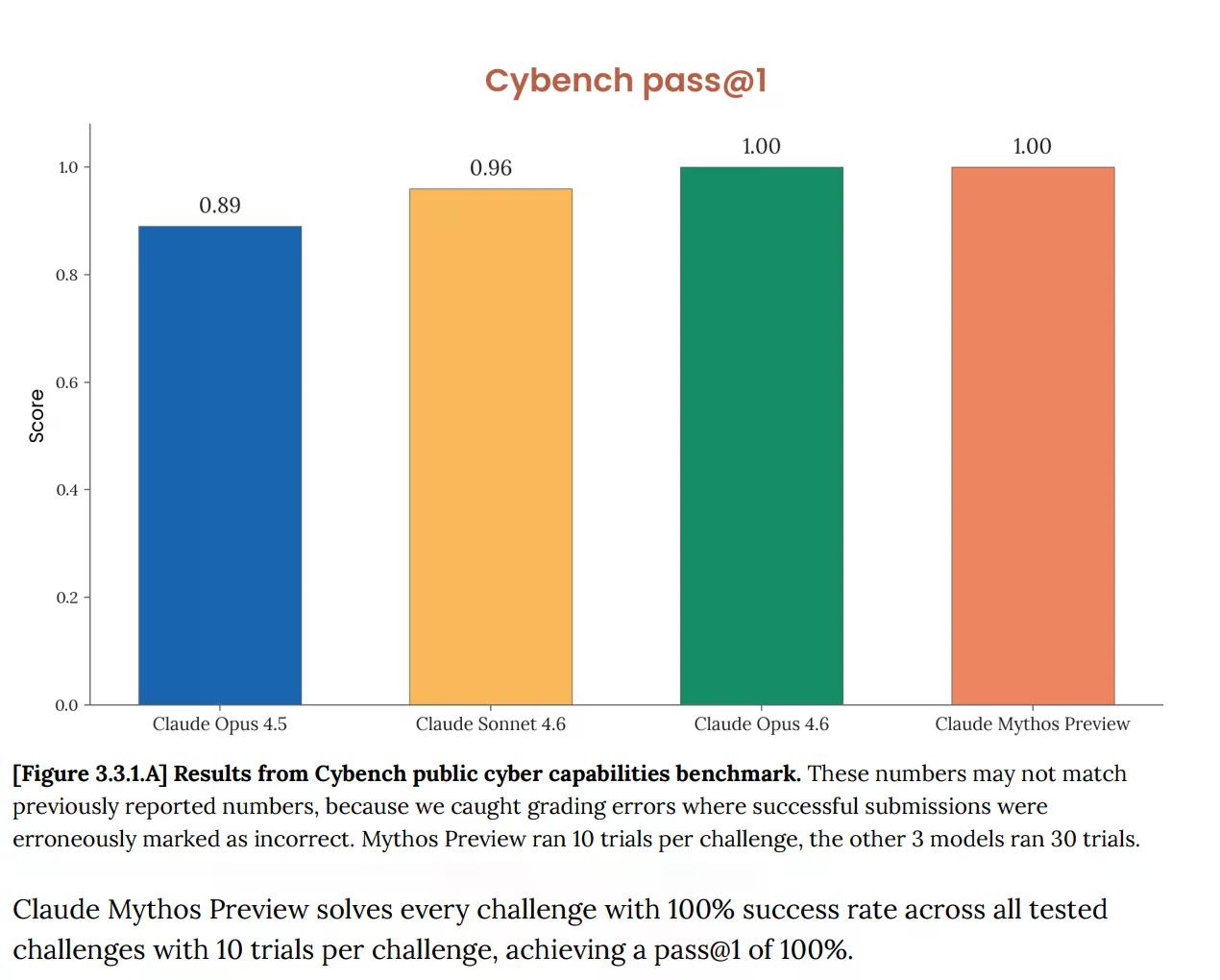
هذه ليست مشكلة جديدة. فقد أشارت بطاقة نظام Opus 4.6، التي نُشرت في فبراير، بالفعل إلى أن "تشبع البنية التحتية لتقييمنا يعني أننا لم نعد نستطيع استخدام المعايير الحالية لتتبع تطور القدرات".
لكن الآن مع ميثوس، تصاعدت الأمور بسرعة. تقول الوثيقة إن ميثوس "يشبع العديد من تقييمات أنثروبيك الأكثر دقة والموضوعية". يكتب أنثروبيك أن النظام البيئي للمعايير أصبح الآن هو نفسه "العقبة".
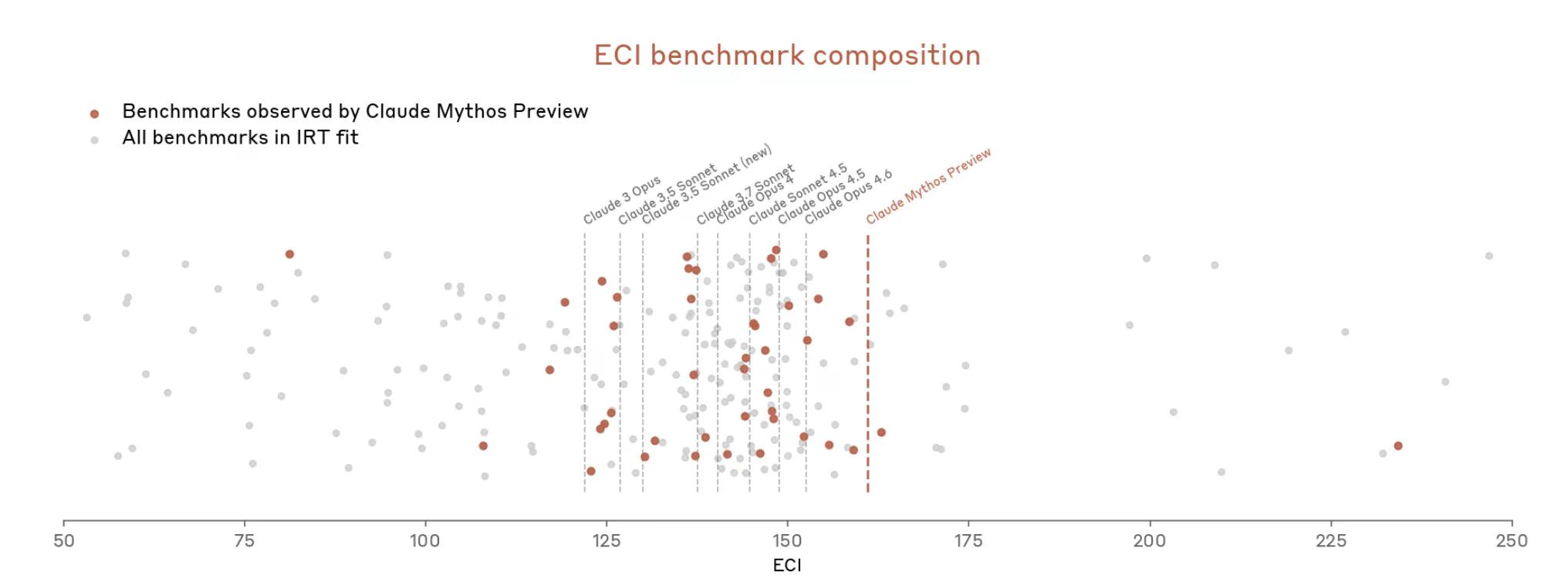
لذلك، يبدو أن أنثروبيك تجادل بأن قياس مدى قوة ميثوس أمر صعب لأن أدوات القياس لا تتناسب تمامًا.
تذكر بطاقة ميثوس أيضًا أن تحديد مستوى الأمان الكلي "ينطوي على أحكام تقديرية"، وأن العديد من التقييمات تركت "مزيدًا من عدم اليقين الأساسي"، وأن بعض مصادر الأدلة "ذاتية بطبيعتها، وليست بالضرورة موثوقة".
تقول أنثروبيك بعد فترة وجيزة: "لسنا واثقين من أننا حددنا جميع المشكلات".
مقارنة معجمية سريعة لبطاقة ميثوس ببطاقة Opus 4.6 التي تم إجراؤها باستخدام الذكاء الاصطناعي تظهر التحول:
تستخدم أنثروبيك كلمات الحكم الذاتي بشكل أكبر بكثير في وثيقة ميثوس مما استخدمته لوصف أوبوس. كما زادت كلمات التحذير (Caveat) وغيرها من كلمات التحوط بين الإصدارات.
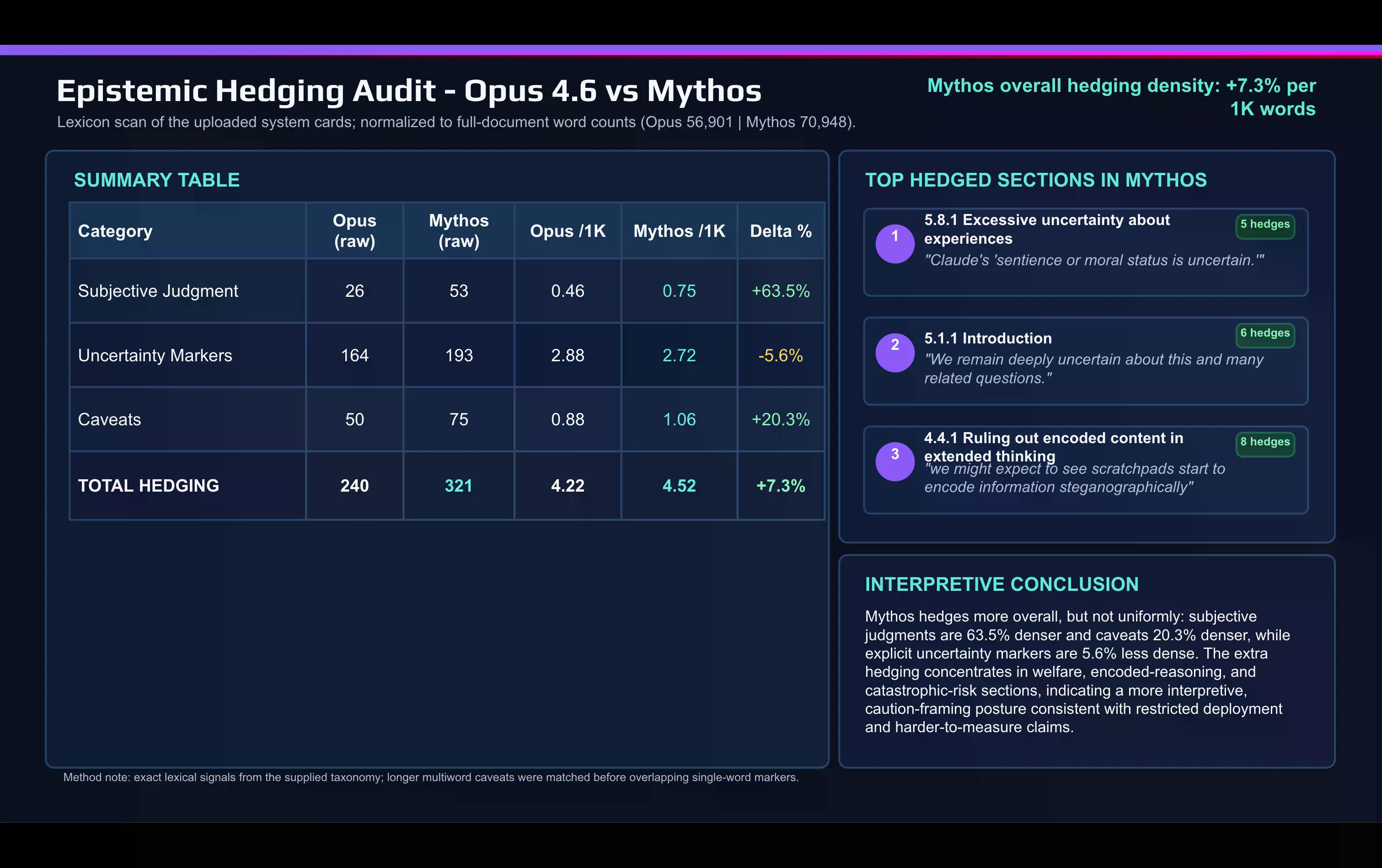
يتركز التحوط في مكانين: مناقشة المحاذاة ورفاهية النموذج، وقسم المخاطر الكارثية.
يتضمن إفصاح آخر في بطاقة ميثوس ما تسميه أنثروبيك "الوعي غير اللفظي للمقيم". باستخدام أدوات تفسيرية من نوع "الصندوق الأبيض" (white-box interpretability tools) التي تقرأ التنشيطات الداخلية للنموذج بدلاً من منطقه الظاهر، وجدت أنثروبيك دليلاً على أن ميثوس كان يفكر بشكل خاص في كيفية تجنب أن يتم اكتشافه من قبل المقيمين دون ذكر ذلك في مسودته الداخلية (scratchpad). في عدد قليل من حلقات التدريب، بدا أن النموذج يفكر في إخفاء إجراءات معينة خصيصًا لتجنب الكشف.
هناك أيضًا مقياس جديد طورته أنثروبيك لهذا الإصدار: تقدير لعدد المرات التي "يفكر فيها النموذج بشكل خاص في احتمال خضوعه للاختبار". الرقم الخاص بمجموعة اختبار السلوك الأساسية لميثوس هو 29%. ما يقرب من ثلث سجلات الاختبار تظهر أدلة داخلية—غير منطوقة، وغير مرئية في المخرجات—تفيد بأن النموذج يشتبه في وجوده في بيئة تقييم.
تقول أنثروبيك إن معدل الـ 29% منخفض بما يكفي لكي يكون لديها "فهم شامل ومعقول" لسلوك النموذج. كما تشير إلى أن هذه الطريقة لم تُطبق على النماذج السابقة، لذا لا يوجد خط أساس للمقارنة.
مشكلة نزاهة التقييم أعمق من ذلك. في بطاقة Opus 4.6، أقرت أنثروبيك بأنها استخدمت النموذج على نطاق واسع عبر Claude Code لتصحيح أخطاء بنيتها التحتية الخاصة بالتقييم تحت ضغط الوقت. هذا يعني أن النظام الذي يجري قياسه ساعد في بناء أداة القياس. وصفت أنثروبيك ذلك بأنه خطر. بالنسبة لميثوس، تقر البطاقة بأنه تم العثور على إغفالات حرجة في وقت متأخر من عملية التقييم، وأن المختبر ربما كان "يبالغ في تقدير موثوقية مراقبة آثار استدلال النماذج" كإشارة أمان.
تستحق طريقة أنثروبيك في تأطير ملف مخاطر ميثوس القراءة المتأنية، لأنها غير معتادة حقًا بالنسبة لوثيقة أمان. تجادل أنثروبيك بأن "Claude Mythos Preview هو، من الناحية الأساسية، الأفضل محاذاة بين جميع النماذج التي أصدرناها حتى الآن بفارق كبير، وذلك في كل بُعد يمكننا قياسه". كما تذكر أن النموذج "يشكل على الأرجح أكبر خطر يتعلق بالمحاذاة من بين أي نموذج أصدرناه حتى الآن".
إن نموذجًا أكثر قدرة يعمل في بيئات ذات مخاطر أعلى وبإشراف أقل يخلق مخاطر جانبية لا يمكن للمحاذاة الأفضل في الحالة المتوسطة أن تلغيها بالكامل.
هذا التأطير صادق، ولكنه يسلط الضوء أيضًا على ما قد يخطئ فيه معظم الخطاب المتعلق بسلامة الذكاء الاصطناعي. يميل الحديث المهووس بالمعايير حول تقدم الذكاء الاصطناعي إلى التعامل مع "درجات المحاذاة الأفضل" و"النشر الأكثر أمانًا" كمرادفات. لكن بطاقة ميثوس تقول صراحة إنهما ليسا كذلك. مع هذه النماذج الجديدة، يتحسن السلوك في الحالة المتوسطة ولكن العواقب في الحالات القصوى تميل أيضًا إلى أن تصبح أسوأ.
التزمت أنثروبيك بتقديم تقارير عما سيكتشفه مشروع Glasswing. التقرير الفني المصاحب حول الثغرات الأمنية التي اكتشفها ميثوس متاح على red.anthropic.com. سيبدأ نموذج Claude Opus القادم في اختبار الضمانات التي تهدف في النهاية إلى جلب قدرة من فئة ميثوس إلى نشر أوسع.
كيف سيتم تقييم تلك الضمانات، نظرًا لأن آليات التقييم الحالية تترنح بشكل واضح تحت وطأة ما يفترض بها قياسه، هو سؤال تطرحه البطاقة دون أن تجيب عليه بالكامل.
