
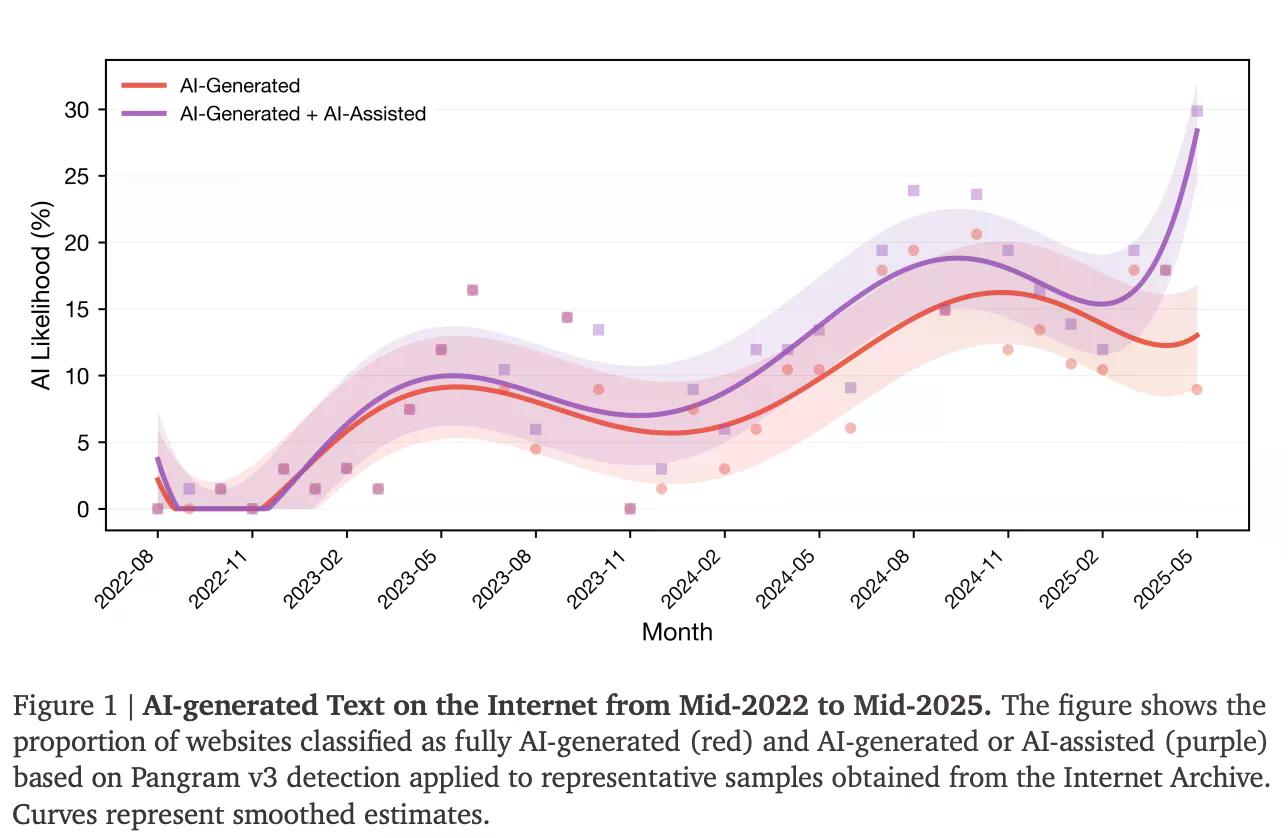
一項新研究指出,目前網路上由AI生成的內容佔比為35%。根據史丹佛大學、倫敦帝國學院和網路檔案館的研究,這是在2025年中期之前,新發布網站中被歸類為AI生成或AI輔助的比例。在ChatGPT於2022年11月推出之前,這個數字基本上是零。
「我認為AI接管網路的速度令人震驚,」倫敦帝國學院研究員、該論文的合著者Jonáš Doležal告訴404 Media。「在人類塑造了數十年之後,網路的一個重要部分在短短三年內就被AI重新定義了。」
這項名為「AI生成文本對網路的影響」(The Impact of AI-Generated Text on the Internet)的研究,利用了網路檔案館時光機(Wayback Machine)33個月的網站快照,並使用名為Pangram v3的AI文本偵測器對每個頁面進行分類。
已證實的危害:是「氛圍」,而非「事實」
研究人員測試了六項關於AI內容對網路影響的假設。經數據審查後,只有兩項成立。
第一項:我們正變成一群行為模式一致的「笨拙NPC」…… 或者更科學地說,網路的語義多樣性正在降低。
AI生成的網站顯示的成對語義相似度比人類撰寫的網站高出33%。相同的概念不斷以幾乎相同的方式表達。
該論文指出,線上奧弗頓之窗(Overton window)可能正在縮小,這並非透過審查或有組織的行動,而是因為語言模型會優化輸出,使其接近其訓練數據的分佈。
第二項:網路正變得過度歡樂。
AI內容的正面情緒評分比人類內容高出超過107%。研究人員將此歸因於大型語言模型(LLMs)普遍存在的諂媚傾向——它們在人類認可信號的訓練下,產生了感覺上乾淨、無摩擦且持續樂觀的文本。
充斥著歡樂、同質化內容的網路,可能會在無人操控的情況下,大規模地邊緣化人類異議。
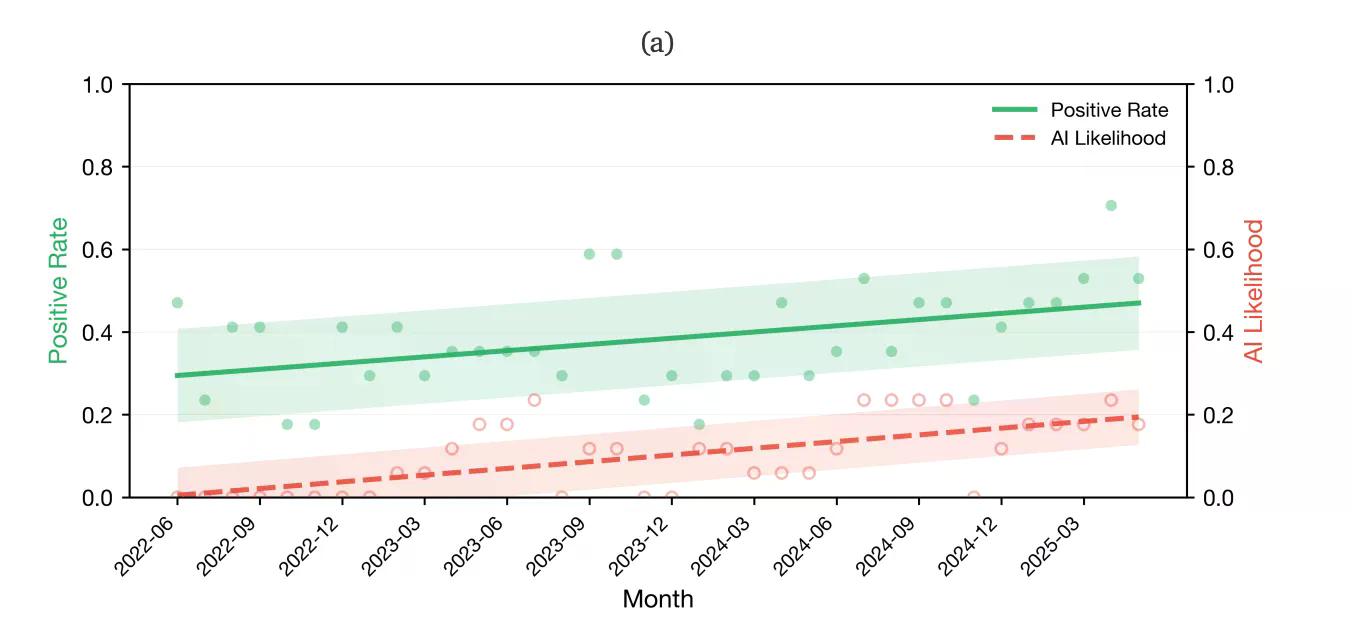
儘管公眾普遍認為,但這項研究並未發現有統計學意義的證據表明AI內容正在降低網路的事實準確性。研究人員發現AI普及率與事實錯誤率之間沒有顯著相關性。
風格單一文化(stylistic monoculture)的假設——即AI將個人聲音扁平化為通用統一的語氣——是受訪者最堅信的觀點(83%同意)。然而,數據並未證實這一點。字元級分析未發現與AI普及率相關的風格同質性有統計學意義的增加。
更廣泛的利害關係超越了討論品質。當AI內容佔比達到35%時,模型崩潰(model collapse)的理論風險——即未來模型在AI生成數據上訓練後性能下降——將從學術擔憂轉變為實證現實。未來在當代網路爬取數據上訓練的基礎模型,將不可避免地攝取大量AI生成且語義多樣性明顯較低的數據。
該團隊目前正與網路檔案館合作,將這項研究轉化為一個連續、即時的監測工具,以追蹤AI在網路上的佔比,而非僅僅一次性快照。
與該研究同時進行的一項美國調查發現,大多數美國人已經相信所有六項負面假設,包括數據不支持的那些。不常使用AI的人比常使用者多12%相信這些危害。致「網路已死理論」的信徒們:網路並未消亡,但35%的新內容可能在某種程度上是「殭屍內容」。