
O CEO da Nvidia, Jensen Huang, participou do podcast de Lex Fridman na semana passada e disse, claramente: "Acho que alcançamos a IAG". Dois dias depois, o teste mais rigoroso em pesquisa de IA lançou seu mais novo benchmark de inteligência artificial geral — e todos os modelos de ponta pontuaram abaixo de 1%.
A Fundação ARC Prize lançou o ARC-AGI-3 esta semana, e os resultados são brutais. O Gemini 3.1 Pro do Google liderou o grupo com 0,37%. O GPT-5.4 da OpenAI obteve 0,26%. O Claude Opus 4.6 da Anthropic conseguiu 0,25%, enquanto o Grok-4.20 da xAI pontuou exatamente zero. Os humanos, por sua vez, resolveram 100% dos ambientes.
Este não é um teste de conhecimentos gerais, um exame de codificação, ou mesmo perguntas de nível de doutorado ultra-difíceis. O ARC-AGI-3 é algo inteiramente diferente de tudo que a indústria de IA já enfrentou.
O benchmark foi construído pela fundação de François Chollet e Mike Knoop, que estabeleceu um estúdio de jogos interno e criou 135 ambientes interativos originais do zero. A ideia é colocar um agente de IA em um mundo semelhante a um jogo desconhecido, sem instruções, sem objetivos declarados e sem descrição das regras. O agente precisa explorar, descobrir o que deve fazer, formular um plano e executá-lo.
Se isso soa como algo que qualquer criança de cinco anos pode fazer, você está começando a entender o problema. Se quiser ver se é melhor que a IA, você pode jogar os mesmos jogos apresentados no teste clicando neste link. Tentamos um; foi estranho no início, mas depois de alguns segundos, você pega o jeito facilmente.
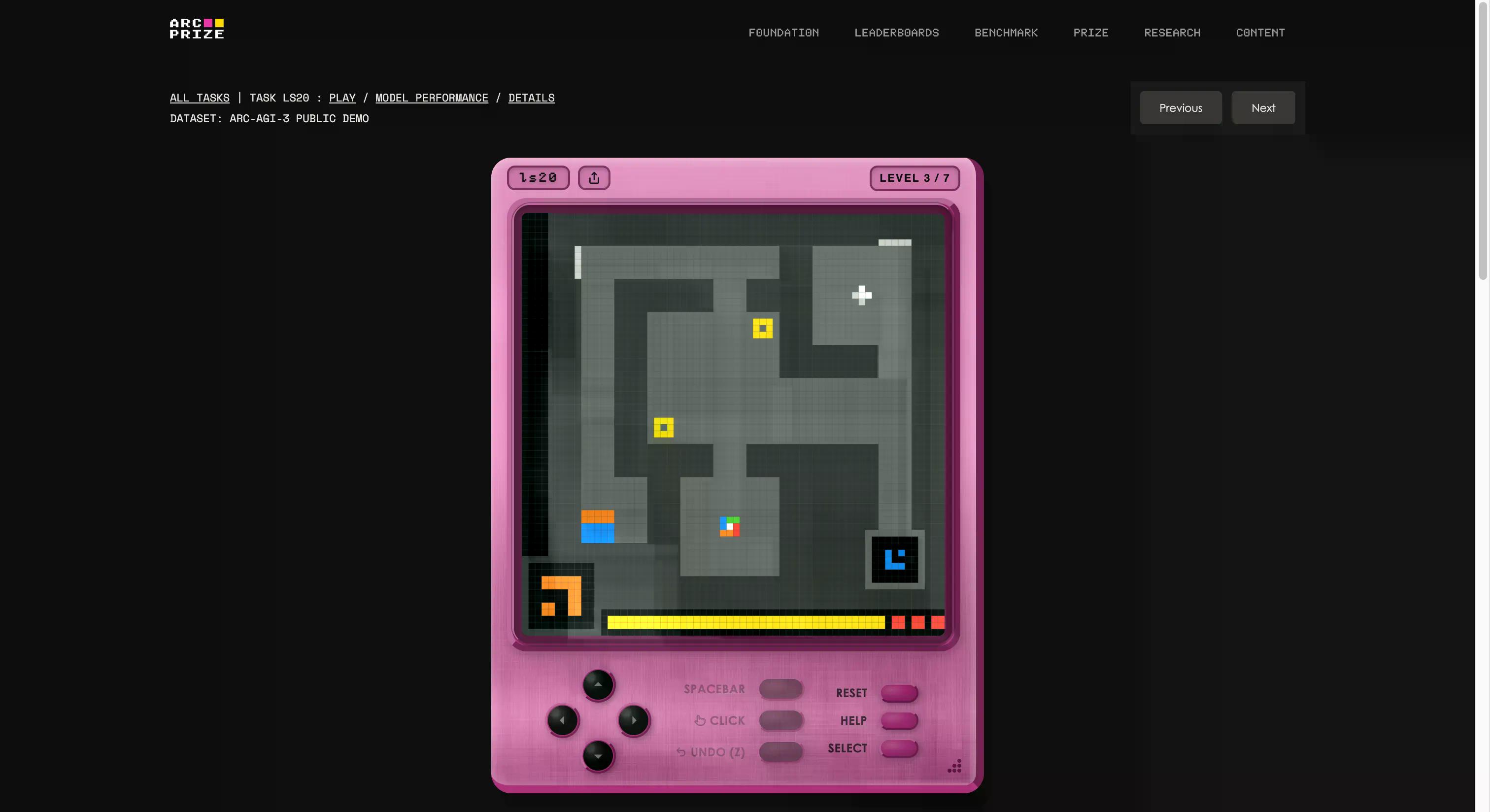
É também o exemplo mais claro do que o "G" em IAG significa. Quando você generaliza, é capaz de criar novos conhecimentos (como um jogo estranho funciona) sem ter sido treinado neles antecipadamente.
Versões anteriores do ARC testaram quebra-cabeças visuais estáticos — mostre um padrão, preveja o próximo. Eram difíceis no início. Então os laboratórios investiram poder computacional e treinamento neles até que os benchmarks estivessem efetivamente "mortos". O ARC-AGI-1, introduzido em 2019, sucumbiu a modelos de treinamento e raciocínio em tempo de teste. O ARC-AGI-2 durou cerca de um ano antes do Gemini 3.1 Pro atingir 77,1%. Os laboratórios são muito bons em saturar benchmarks contra os quais podem treinar.
A Versão 3 foi projetada especificamente para evitar isso. Com 110 dos 135 ambientes mantidos privados — 55 semiprivados para testes de API, 55 totalmente bloqueados para competição — não há conjunto de dados para memorizar. Você não consegue forçar seu caminho através de lógicas de jogo novas que nunca viu.
A pontuação também não é aprovação/reprovação. O ARC-AGI-3 usa o que a fundação chama de RHAE — Eficiência de Ação Humana Relativa. O ponto de referência é o segundo melhor desempenho humano na primeira tentativa. Uma IA que realiza dez vezes mais ações do que um humano pontua 1% para aquele nível, não 10%. A fórmula penaliza quadraticamente a ineficiência. Divagar, retroceder e adivinhar a resposta é duramente punido.
O melhor agente de IA na prévia para desenvolvedores de um mês marcou 12,58%. Os LLMs de ponta testados através da API oficial, sem ferramentas personalizadas, não conseguiram ultrapassar 1%. Humanos comuns resolveram todos os 135 ambientes sem treinamento prévio e sem instruções. Se essa é a régua, então a safra atual de modelos não está atingindo.
Há um debate metodológico real aqui. O relatório da ARC afirma que um "harness" personalizado construído pela Duke impulsionou o Claude Opus 4.6 de 0,25% para 97,1% em uma única variante de ambiente chamada TR87. Isso não significa que o Claude pontuou 97,1% no ARC-AGI-3 no geral; sua pontuação oficial no benchmark permaneceu 0,25%, mas a mudança ainda é digna de nota.
O benchmark oficial alimenta os agentes com código JSON, não com recursos visuais. Isso é ou uma falha metodológica ou uma demonstração de que os modelos atuais são melhores em processar informações amigáveis ao ser humano do que dados estruturados brutos. A fundação de Chollet reconheceu o debate, mas não está mudando o formato.
"A percepção do conteúdo do quadro e o formato da API não são fatores limitantes para o desempenho dos modelos de ponta no ARC-AGI-3", diz o artigo. Em outras palavras, eles parecem rejeitar a ideia de que os modelos falham porque "não conseguem ver" as tarefas corretamente, argumentando, em vez disso, que a percepção já é suficiente — e a verdadeira lacuna reside no raciocínio e na generalização.
A verificação da realidade da IAG chegou durante uma semana em que a máquina de hype estava a todo vapor. Além do comentário de Huang, a Arm nomeou seu novo chip de data center de "AGI CPU". Sam Altman, da OpenAI, disse que eles "basicamente construíram a IAG", e a Microsoft já está comercializando um laboratório focado na construção de ASI: uma evolução do que vem depois que a IAG é alcançada. O termo está sendo esticado até significar o que for comercialmente conveniente, ao que parece.
A posição de Chollet é mais simples. Se um humano normal sem instruções consegue fazer, e seu sistema não, então você não tem IAG — você tem um autocompletar muito caro que precisa de muita ajuda.
O ARC Prize 2026 está oferecendo $2 milhões em três trilhas de competição, todas hospedadas no Kaggle. Toda solução vencedora deve ser de código aberto. O tempo está correndo, e agora, as máquinas nem sequer chegam perto.