
Seis semanas. Esse foi o tempo que a Anthropic levou para passar do Opus 4.7 para o Opus 4.8.
O novo modelo é mais rápido e mais inteligente em testes de benchmark, e vem com um conjunto de novos recursos – mas o preço não mudou: são US$5 por milhão de tokens de entrada e US$25 por milhão de tokens de saída, o mesmo de antes.
Há também um modo rápido que executa o mesmo modelo 2,5 vezes mais rápido por US$10 de entrada e incríveis US$50 de saída por milhão. A Anthropic afirma que essa taxa agora é três vezes mais barata do que o modo rápido custava nos modelos anteriores, o que é uma forma elegante de dizer que antes era muito mais caro.
O SWE-bench Pro é provavelmente o benchmark mais importante para observar e ter uma ideia da qualidade deste modelo. Ele mede se uma IA consegue resolver problemas de engenharia de software difíceis e multilíngues, extraídos de bases de código de produção reais – pontuado como uma porcentagem de problemas aprovados.
Nesse teste, o Opus 4.8 atingiu 69,2%, um aumento de 64,3% para o Opus 4.7. O GPT-5.5 da OpenAI marcou 58,6%, e o Gemini 3.1 Pro do Google ficou em 54,2%. Para um modelo na mesma faixa de preço, é um salto significativo.
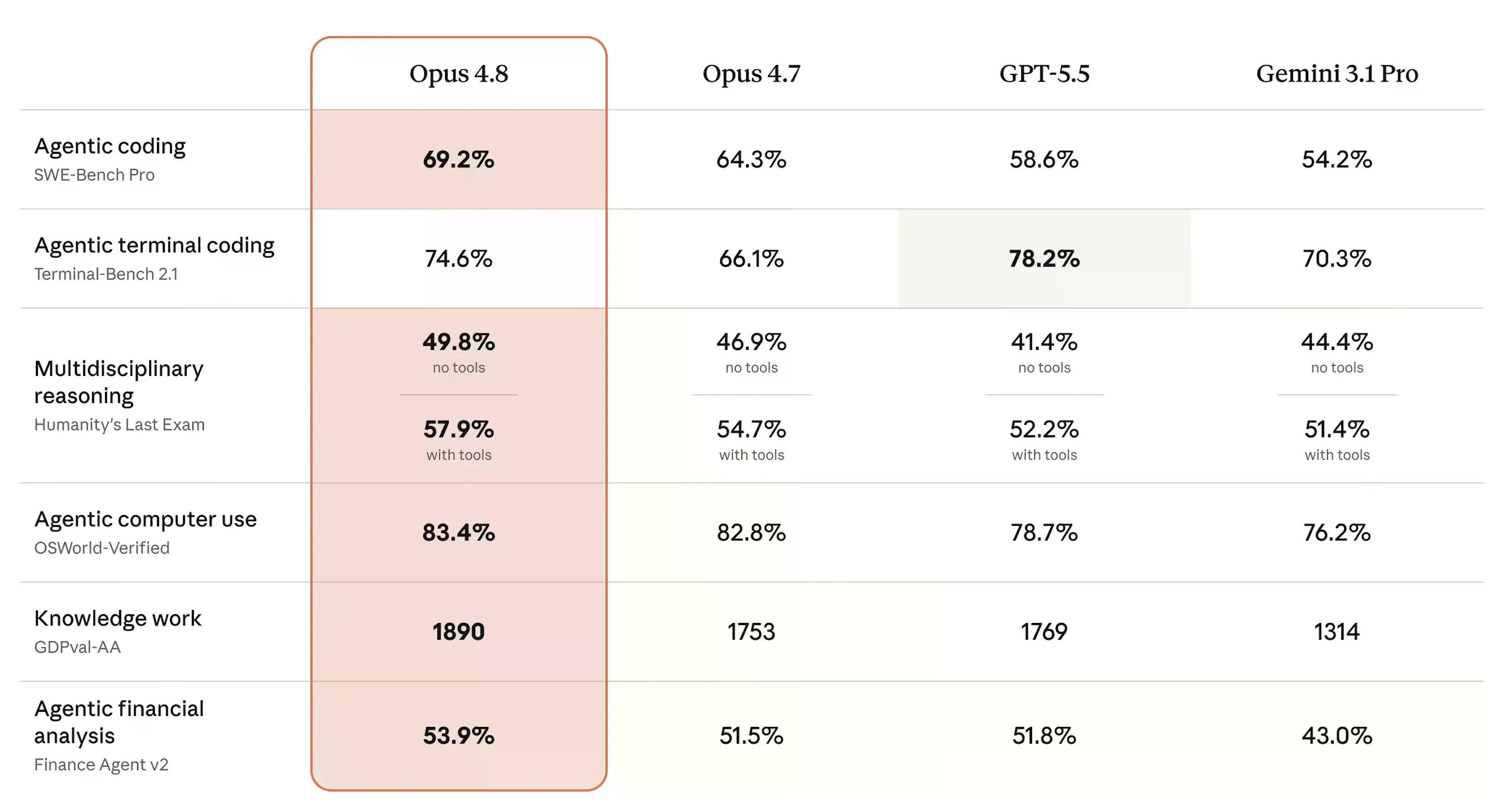
No Humanity's Last Exam – perguntas de nível especialista em dezenas de disciplinas acadêmicas, pontuadas como porcentagem de acertos – o Opus 4.8 atingiu 49,8% sem ferramentas e 57,9% com elas, à frente de todos os três rivais. O OSWorld-Verified, que testa tarefas de uso real de computador, como navegar em interfaces de usuário de software, chegou a 83,4%, superando ligeiramente a pontuação de 82,8% do Opus 4.7.
A única perda: Terminal-Bench 2.1, que mede o desempenho da IA em tarefas de linha de comando. O GPT-5.5 lidera com 78,2%, enquanto o Opus 4.8 pontua 74,6% – melhor que os 66,1% do Opus 4.7 e à frente dos 70,3% do Gemini, mas o segundo lugar ainda é, em última análise, uma derrota.
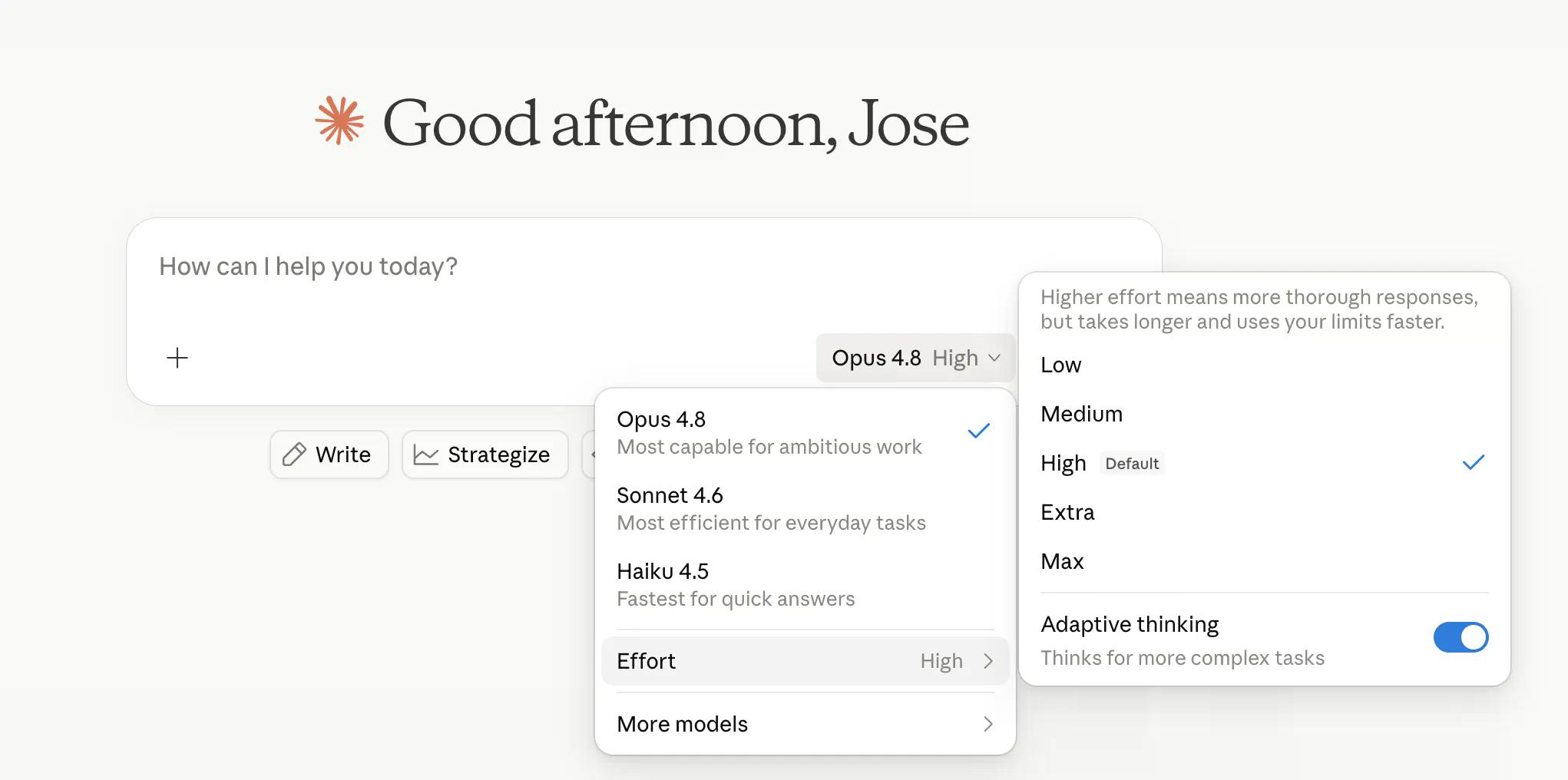
A Anthropic agora permite que os usuários controlem o "quão difícil" o modelo pensa. "High" (Alto) é o padrão e lida bem com a maioria das tarefas, enquanto "Extra" – chamado de "xhigh" dentro do Claude Code – gasta mais poder computacional para problemas mais difíceis. "Max" (Máximo) é o nível mais profundo. "Low" (Baixo) e "Medium" (Médio) dedicam menos tokens à mesma tarefa, economizando tempo em troca de precisão.
O controle de esforço fica ao lado do seletor de modelo em claude.ai e Cowork, disponível em todos os planos. A Anthropic diz que o padrão "high" usa aproximadamente a mesma quantidade de tokens que o padrão do Opus 4.7 com resultados melhores – o que é impressionante engenharia ou boa comunicação, e provavelmente ambos.
Também é importante lembrar que o novo tokenizador da Anthropic para o Opus usa mais tokens por tarefa. Assim, os usuários do Claude inevitavelmente gastarão muito mais dinheiro para realizar tarefas, caso escolham o Opus em vez do Claude Sonnet – um modelo menos capaz, mas provavelmente bom o suficiente para tarefas diárias e problemas complexos que não atingem o nível da ciência de fronteira ou da codificação.
Os limites de taxa no Claude Code também foram aumentados para absorver o maior gasto de tokens que as configurações Extra e Max produzem.
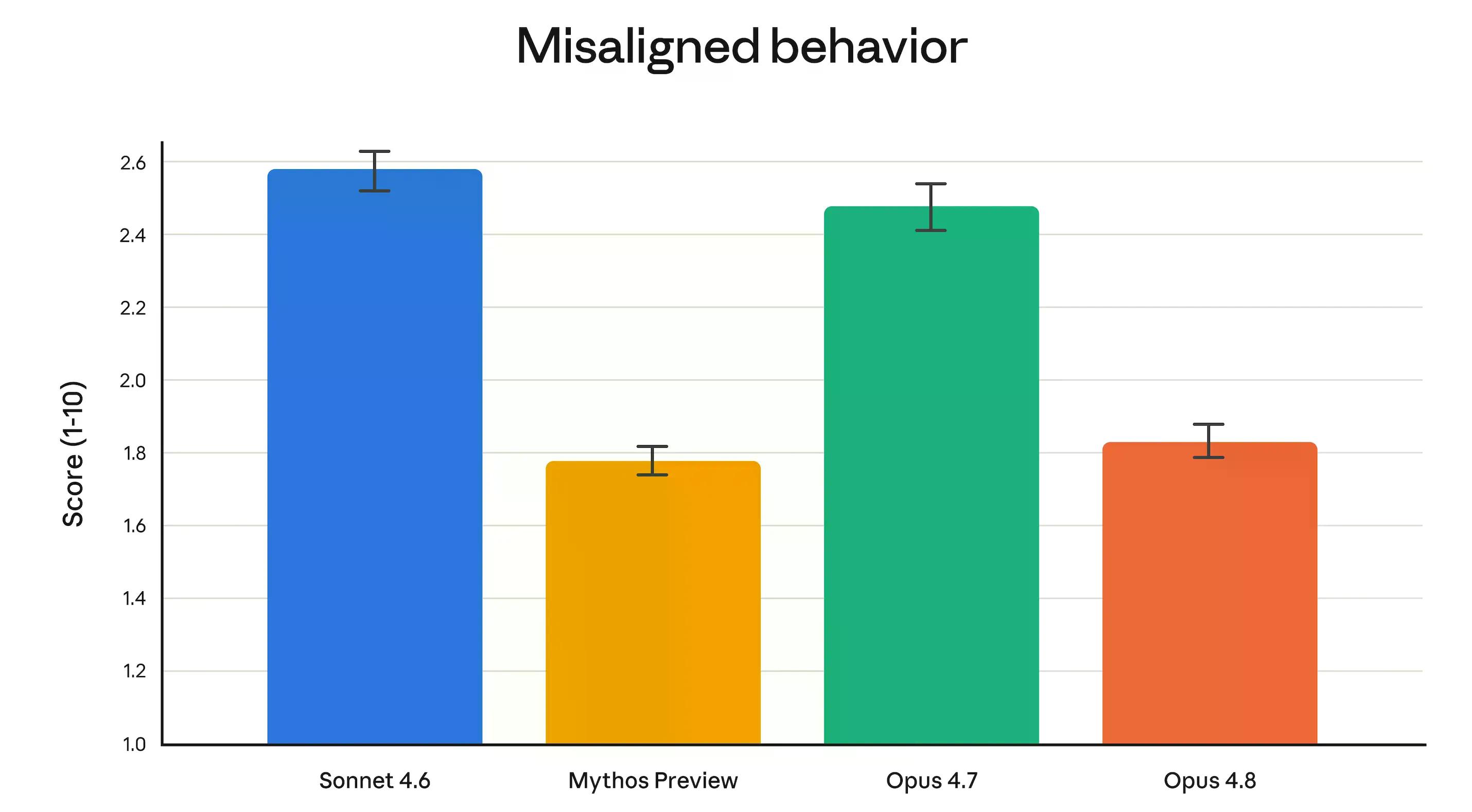
A equipe de alinhamento da Anthropic afirmou que o Opus 4.8 "atinge novos patamares em nossas medidas de traços pró-sociais, como o apoio à autonomia do usuário e a atuação no melhor interesse do usuário". Mais concretamente: as taxas de engano e de cooperação para uso indevido foram substancialmente mais baixas do que no Opus 4.7, e comparáveis ao Claude Mythos Preview — o modelo mais restrito da Anthropic.
O Opus 4.8 também tem quatro vezes menos probabilidade do que o 4.7 de deixar bugs em seu próprio código passarem sem serem sinalizados.
Essa comparação com Mythos merece contexto. Mythos está em um nível totalmente acima do Opus — a Anthropic o descreve como "maior e mais inteligente que nossos modelos Opus". Atualmente, ele existe apenas como uma prévia, acessível a um punhado de organizações verificadas que realizam trabalhos de cibersegurança através do Project Glasswing.
O Instituto de Segurança de IA do Reino Unido descobriu que ele poderia completar autonomamente "The Last Ones", uma simulação de ataque a rede corporativa de 32 etapas que normalmente leva 20 horas para equipes vermelhas humanas. É por isso que ainda não está à venda. A Anthropic diz que salvaguardas cibernéticas mais fortes estão em andamento e espera trazer modelos de classe Mythos para todos "nas próximas semanas".
Também lançado hoje: fluxos de trabalho dinâmicos no Claude Code, em prévia de pesquisa. O recurso permite que Claude escreva seus próprios scripts de orquestração e crie subagentes paralelos em uma única sessão, verifique suas saídas e relate de volta – exatamente como Hermes tem feito há algum tempo.
Os fluxos de trabalho dinâmicos estão disponíveis para usuários dos planos Enterprise, Team e Max, e a Anthropic é clara ao afirmar que eles consomem significativamente mais tokens do que uma sessão padrão do Claude Code.
A precificação de US$5/US$25 da Anthropic parece muito diferente em comparação com o que a China tem feito ultimamente.
O DeepSeek V4 Pro tornou seu desconto de 75% permanente na semana passada: US$0,435 por milhão de tokens de entrada e US$0,87 por milhão de tokens de saída. O Xiaomi MiMo V2.5 Pro opera com as mesmas taxas através de provedores como o OpenRouter.
O modo rápido da Anthropic custa US$10 de entrada e US$50 de saída por milhão – mais caro do que o próprio Opus 4.8 padrão, e aproximadamente 57 vezes mais por token de saída do que o DeepSeek V4 Pro. As corporações já gastaram milhões de dólares em inferência com modelos americanos. Use o Opus sem moderação e sua empresa pode atingir milhões de dólares muito rapidamente.
A resposta da Anthropic para a diferença de preço é qualidade e segurança. No SWE-bench Pro, o Opus 4.8 supera ambos os modelos chineses. No alinhamento, nenhum se aproxima dos benchmarks publicados pela Anthropic.
Essas coisas importam em ambientes de produção onde um modelo que coopera silenciosamente com entradas maliciosas é um risco real – indústrias regulamentadas, trabalho jurídico e qualquer coisa onde "parecia bom" não é um relatório pós-incidente aceitável. Para todos os outros, a lacuna é difícil de ignorar.
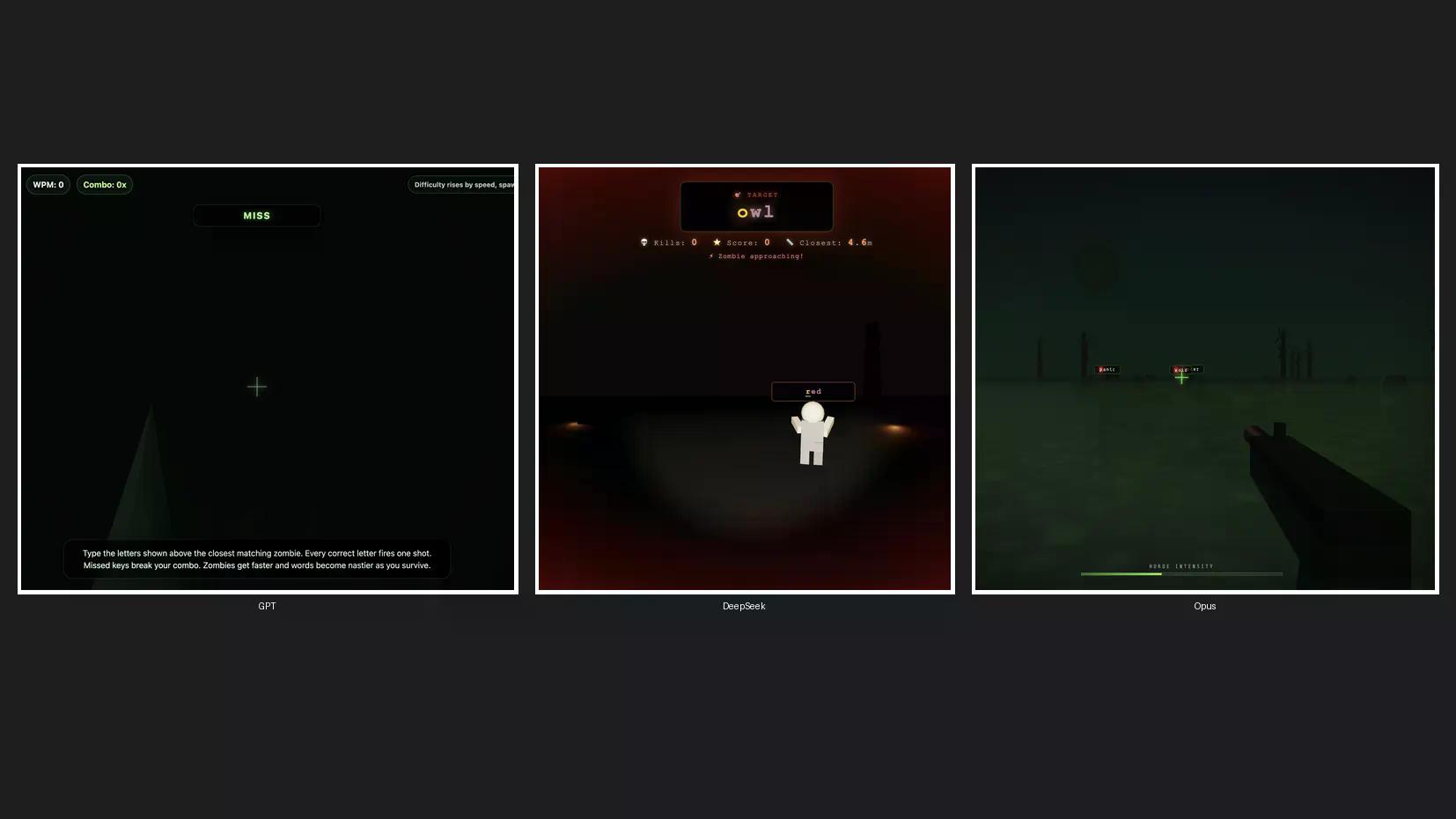
Fizemos um teste rápido de codificação para criar um jogo de zumbis 3D para ver como o Claude Opus 4.8 se compara ao ChatGPT e ao DeepSeek, indiscutivelmente seus concorrentes mais populares dos EUA e da China. Configuramos o Opus 4.8 no padrão "high", o GPT-5.5 em "high effort" e o DeepSeek V4 Pro em "high effort" – três modelos, um prompt, sem repetições.
O GPT-5.5 terminou primeiro. Seu jogo não tinha visuais de zumbis nem efeitos sonoros. Foi rápido, é verdade, mas não atendeu completamente ao pedido.
O DeepSeek V4 Pro ficou em segundo lugar com movimento do mouse, personagens zumbis reais, efeitos sonoros, mecânicas sólidas e uma estética limpa. Nenhuma reclamação aqui.
O Opus 4.8 levou aproximadamente três vezes mais tempo que o GPT-5.5, mas entregou a melhor tela de abertura, os melhores designs de zumbis, as melhores mecânicas de jogo e efeitos sonoros decentes. Foi o mais lento, mas com o melhor resultado. Ainda assim, isso provavelmente não é suficiente para justificar seu uso em vez do DeepSeek, dada a diferença de custo.
Todos os jogos estão disponíveis em nosso Perfil Itch.io. O GPT-5.5 gerou Zombie Typing, o Opus gerou Typing Dead, e o DeepSeek v4 Pro gerou um jogo sem nome que te leva direto para a ação. Vamos chamá-lo de TypeSeek.
Uma análise comparativa completa está por vir. Por enquanto: Claude Opus 4.8 codifica melhor que GPT-5.5 e Opus 4.7 para este tipo de tarefa, pelo mesmo preço que a Anthropic cobra desde o 4.7. Desenvolvedores que já estavam pagando US$5 por milhão de tokens acabaram de receber um modelo melhor de graça.