
Nvidia CEO Jensen Huang was vorige week te gast in de podcast van Lex Fridman en zei ronduit: "Ik denk dat we AGI hebben bereikt." Twee dagen later publiceerde de meest rigoureuze test in AI-onderzoek zijn nieuwste benchmark voor algemene kunstmatige intelligentie – en elk grensverleggend model scoorde minder dan 1%.
De ARC Prize Foundation bracht deze week ARC-AGI-3 uit, en de resultaten zijn keihard. Google’s Gemini 3.1 Pro leidde het peloton met 0,37%. OpenAI’s GPT-5.4 kwam uit op 0,26%. Anthropic’s Claude Opus 4.6 behaalde 0,25%, terwijl xAI’s Grok-4.20 precies nul scoorde. Mensen daarentegen losten 100% van de omgevingen op.
Dit is geen triviatest of codeerexamen, of zelfs ultra-moeilijke PhD-vragen. ARC-AGI-3 is iets heel anders dan wat de AI-industrie eerder heeft gezien.
De benchmark werd gebouwd door de stichting van François Chollet en Mike Knoop, die een interne gamestudio oprichtte en 135 originele interactieve omgevingen van nul af aan creëerde. Het idee is om een AI-agent in een onbekende, game-achtige wereld te plaatsen zonder instructies, zonder vastgestelde doelen en zonder beschrijving van de regels. De agent moet verkennen, uitvinden wat het moet doen, een plan vormen en dit uitvoeren.
Als dat klinkt als iets wat een vijfjarige kan doen, dan begin je het probleem te begrijpen. Als je wilt zien of jij beter bent dan AI, kun je dezelfde spellen spelen die in de test voorkomen door op deze link te klikken. We probeerden er één; het was eerst vreemd, maar na een paar seconden kreeg je het gemakkelijk onder de knie.
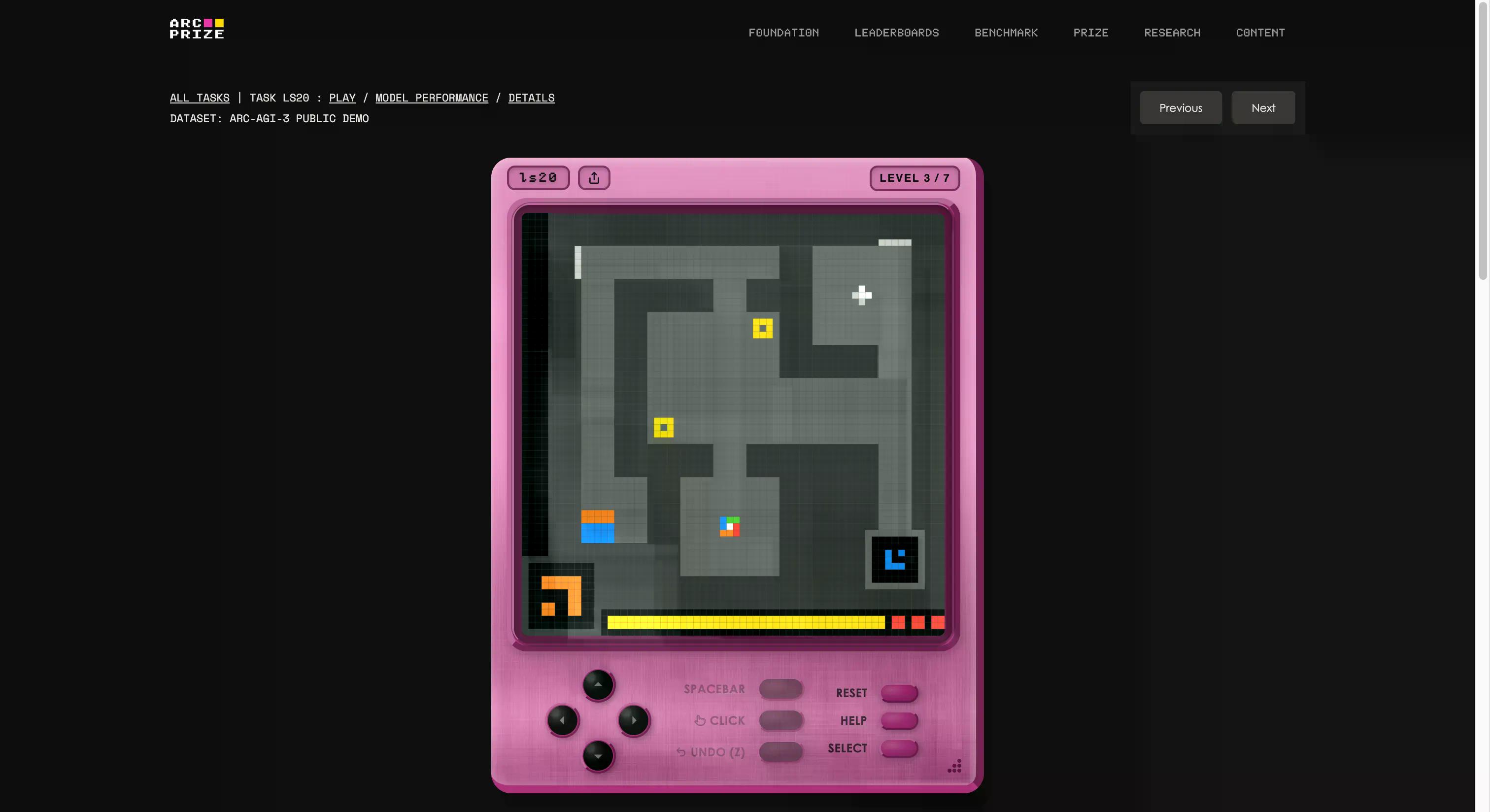
Het is ook het duidelijkste voorbeeld van waar de “G” in AGI voor staat. Wanneer je generaliseert, ben je in staat om nieuwe kennis (hoe een vreemd spel werkt) te creëren zonder hier van tevoren op getraind te zijn.
Eerdere versies van ARC testten statische visuele puzzels – toon een patroon, voorspel het volgende. Ze waren aanvankelijk moeilijk. Daarna gooiden de laboratoria rekenkracht en training erop totdat de benchmarks feitelijk dood waren. ARC-AGI-1, geïntroduceerd in 2019, bezweek aan trainingstijd en redeneermodellen. ARC-AGI-2 hield ongeveer een jaar stand voordat Gemini 3.1 Pro 77,1% bereikte. De laboratoria zijn erg goed in het verzadigen van benchmarks waartegen ze kunnen trainen.
Versie 3 was specifiek ontworpen om dat te voorkomen. Met 110 van de 135 omgevingen privé gehouden – 55 semi-privé voor API-testen, 55 volledig afgesloten voor competitie – is er geen dataset om uit het hoofd te leren. Je kunt geen nieuwe gamelogica die je nog nooit hebt gezien, met brute kracht oplossen.
Scoren is ook geen alles-of-niets. ARC-AGI-3 gebruikt wat de stichting RHAE noemt – Relative Human Action Efficiency (Relatieve Menselijke Actie-efficiëntie). De basislijn is de op één na beste, eerste menselijke prestatie. Een AI die tien keer zoveel acties onderneemt als een mens, scoort 1% voor dat niveau, niet 10%. De formule kwadrateert de straf voor inefficiëntie. Ronddwalen, terugkeren en gokken naar een antwoord wordt zwaar bestraft.
De beste AI-agent in de ontwikkelaars-preview van een maand scoorde 12,58%. Grensverleggende LLM's die via de officiële API werden getest, zonder aangepaste hulpmiddelen, haalden de 1% niet. Gewone mensen losten alle 135 omgevingen op zonder voorafgaande training en zonder instructies. Als dat de lat is, dan haalt de huidige generatie modellen die niet.
Er is hier één echt methodologisch debat. Het rapport van ARC stelt dat een op maat gemaakt 'harnas' (custom harness) gebouwd door Duke, Claude Opus 4.6 van 0,25% naar 97,1% bracht op één omgevingsvariant genaamd TR87. Dat betekent niet dat Claude 97,1% scoorde op ARC-AGI-3 in zijn geheel; de officiële benchmarkscore bleef 0,25%, maar de verschuiving is nog steeds het vermelden waard.
De officiële benchmark voedt agenten JSON-code, geen beelden. Dat is ofwel een methodologisch gebrek, ofwel een demonstratie dat de huidige modellen beter zijn in het verwerken van mensvriendelijke informatie dan ruwe gestructureerde data. De stichting van Chollet heeft het debat erkend, maar verandert het formaat niet.
“De perceptie van frame-inhoud en het API-formaat zijn geen beperkende factoren voor de prestaties van grensverleggende modellen op ARC-AGI-3,” staat in het document te lezen. Met andere woorden, ze lijken het idee te verwerpen dat modellen falen omdat ze de taken niet goed “kunnen zien”, en stellen in plaats daarvan dat perceptie al voldoende is – en de echte kloof ligt in redenering en generalisatie.
De AGI-realiteitscheck kwam aan in een week waarin de hype-machine op volle toeren draaide. Naast de opmerking van Huang noemde Arm zijn nieuwe datacenterchip de "AGI CPU". Sam Altman van OpenAI heeft gezegd dat ze "eigenlijk AGI hebben gebouwd", en Microsoft promoot al een lab dat zich richt op het bouwen van ASI: een evolutie van wat komt nadat AGI is bereikt. De term wordt opgerekt totdat het betekent wat commercieel handig is, zo lijkt het.
De positie van Chollet is eenvoudiger. Als een normaal mens zonder instructies het kan, en jouw systeem niet, dan heb je geen AGI – dan heb je een zeer dure autocomplete die veel hulp nodig heeft.
De ARC Prize 2026 biedt $2 miljoen verspreid over drie wedstrijdtracks, allemaal gehost op Kaggle. Elke winnende oplossing moet open-source zijn. De klok tikt, en op dit moment zijn de machines nog lang niet zo ver.