
Anthropic bevestigde gisteren het bestaan van Claude Mythos Preview, zijn meest capabele model tot nu toe, en kondigde aan dat het niet publiekelijk beschikbaar zal worden gesteld. De reden is niet juridisch, regulerend of gerelateerd aan de interne veiligheidsdrempels. Anthropic stelt dat het komt omdat het model simpelweg te goed is in het doorbreken van systemen.
Tijdens pre-release testen vond Mythos autonoom duizenden zero-day kwetsbaarheden – veel daarvan één tot twee decennia oud – in elk belangrijk besturingssysteem en elke belangrijke webbrowser. Het loste een gesimuleerde bedrijfsnetwerkaanval op die een ervaren menselijke expert normaal gesproken meer dan 10 uur, van begin tot eind, zonder begeleiding zou kosten. Op de JavaScript-engine van Firefox 147 ontwikkelde het met succes werkende exploits in 84% van de gevallen. Claude Opus 4.6, het huidige publiek beschikbare grensmodel, behaalde 15,2%.
Daarom bouwde Anthropic een beperkte coalitie. Project Glasswing zal toegang tot Mythos Preview alleen verlenen aan geaccrediteerde cybersecurity-organisaties – Amazon, Apple, Broadcom, Cisco, CrowdStrike, de Linux Foundation, Microsoft, Palo Alto Networks, en ongeveer 40 andere groepen die kritieke software onderhouden.
Anthropic zegt tot $100 miljoen aan gebruikstegoeden en $4 miljoen aan directe donaties toe aan open-source beveiligingsorganisaties. Het idee is dat als het model de gaten kan vinden, de verdedigers ze als eerste moeten vinden.
Dat deel van het verhaal is belangrijk. Maar het is niet het belangrijkste deel.
Begraven in de Mythos Preview systeemkaart — een technisch document van 244 pagina's dat Anthropic samen met de aankondiging publiceerde — is een bekentenis die bijna onopgemerkt bleef: Het vermogen van het laboratorium om te meten wat het heeft gebouwd, erodeert sneller dan zijn vermogen om het te bouwen.
Laten we beginnen met de benchmarks.
Op Cybench, de standaard publieke evaluatie van cybermogelijkheden die wordt gebruikt om de modelvoortgang te volgen over 40 capture-the-flag uitdagingen, scoorde Mythos 100%. Perfect. En Anthropic merkte onmiddellijk op dat de benchmark "niet langer voldoende informatief is over de huidige mogelijkheden van grensmodellen." Die zin doet veel werk. De test die je zou moeten vertellen of een AI een ernstig cyberrisico vormt, vertelt nu helemaal niets meer over Mythos, omdat het model de test volledig heeft doorstaan.
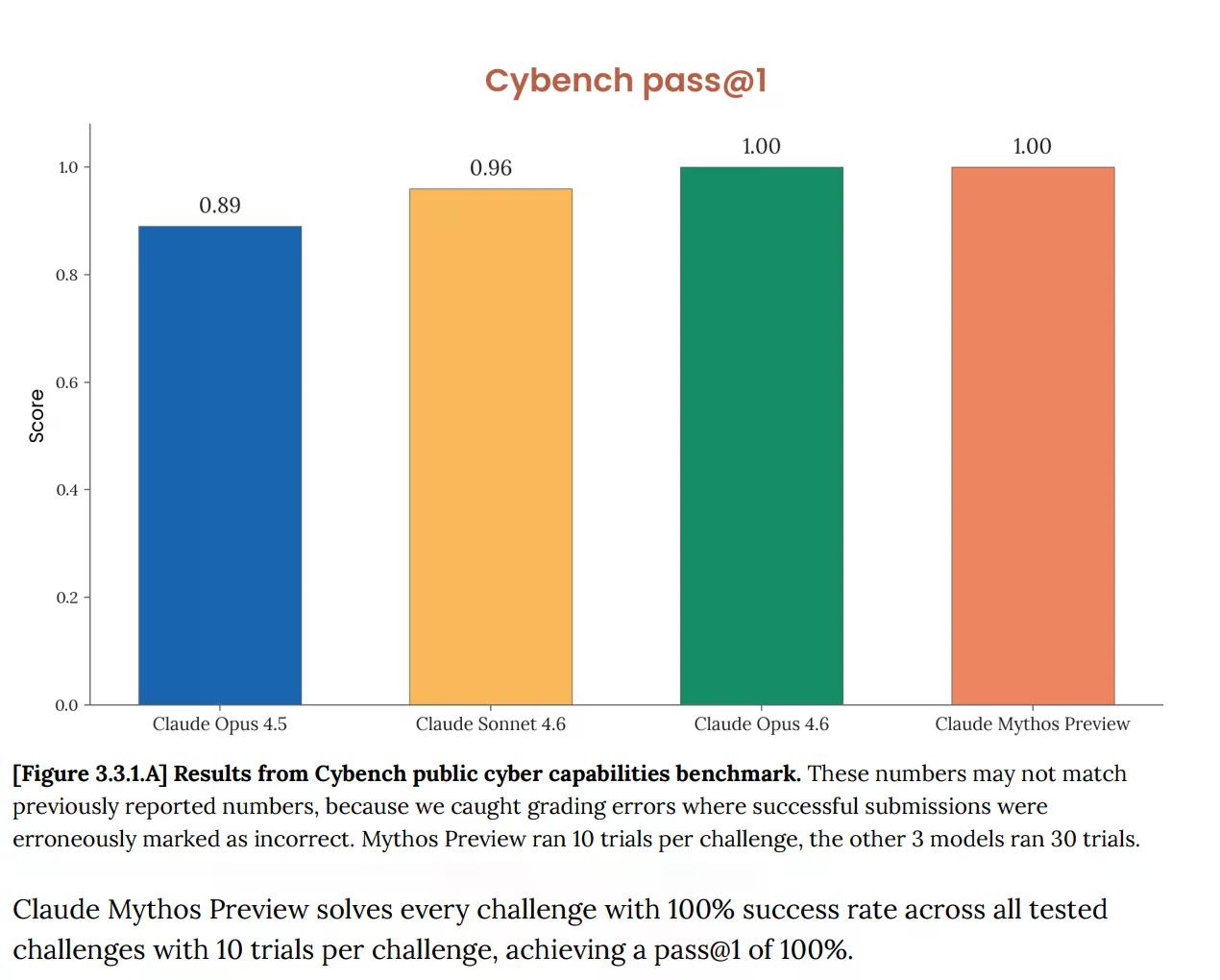
Dit is geen nieuw probleem. De systeemkaart van Opus 4.6, gepubliceerd in februari, gaf al aan dat "de verzadiging van onze evaluatie-infrastructuur betekent dat we huidige benchmarks niet langer kunnen gebruiken om de voortgang van capaciteiten te volgen."
Maar met Mythos escaleerden de zaken snel. Het document stelt dat Mythos "veel van de meest concrete, objectief gescoorde evaluaties (van Anthropic) verzadigt." Het benchmark-ecosysteem, zo schrijft Anthropic, is nu zelf "de bottleneck."
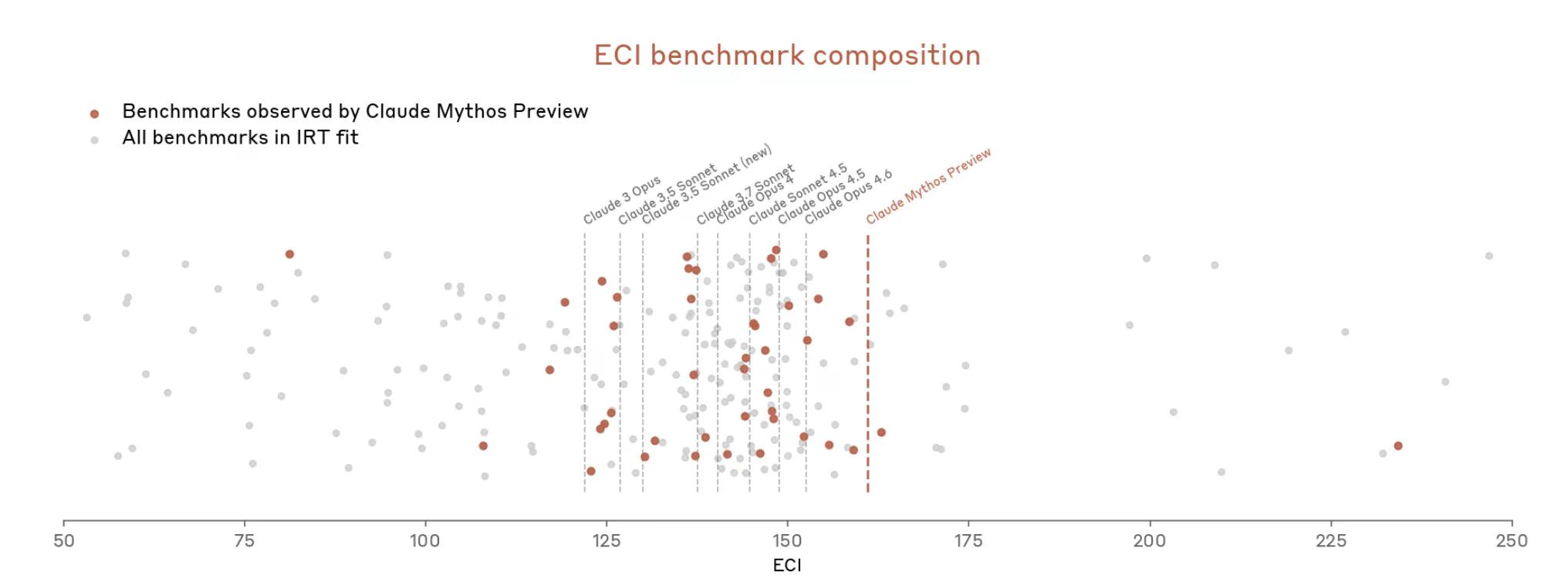
Anthropic lijkt dus te beweren dat het moeilijk is om te meten hoe krachtig Mythos is, omdat de meetinstrumenten niet helemaal passen.
De Mythos-kaart stelt ook dat de algehele veiligheidsbepaling "oordeelsvorming omvat", dat veel evaluaties "meer fundamentele onzekerheid" hebben achtergelaten, en dat sommige bewijsbronnen "inherent subjectief en niet noodzakelijk betrouwbaar" zijn.
"We zijn er niet zeker van dat we alle problemen hebben geïdentificeerd," zegt Anthropic kort daarna.
Een snelle lexicale vergelijking van de Mythos-kaart met de Opus 4.6-kaart, gemaakt met AI, toont de verschuiving:
Anthropic gebruikt veel meer subjectieve oordeelswoorden in het Mythos-document dan het deed om Opus te beschrijven. "Caveat" en andere voorbehouden namen ook toe tussen de releases.
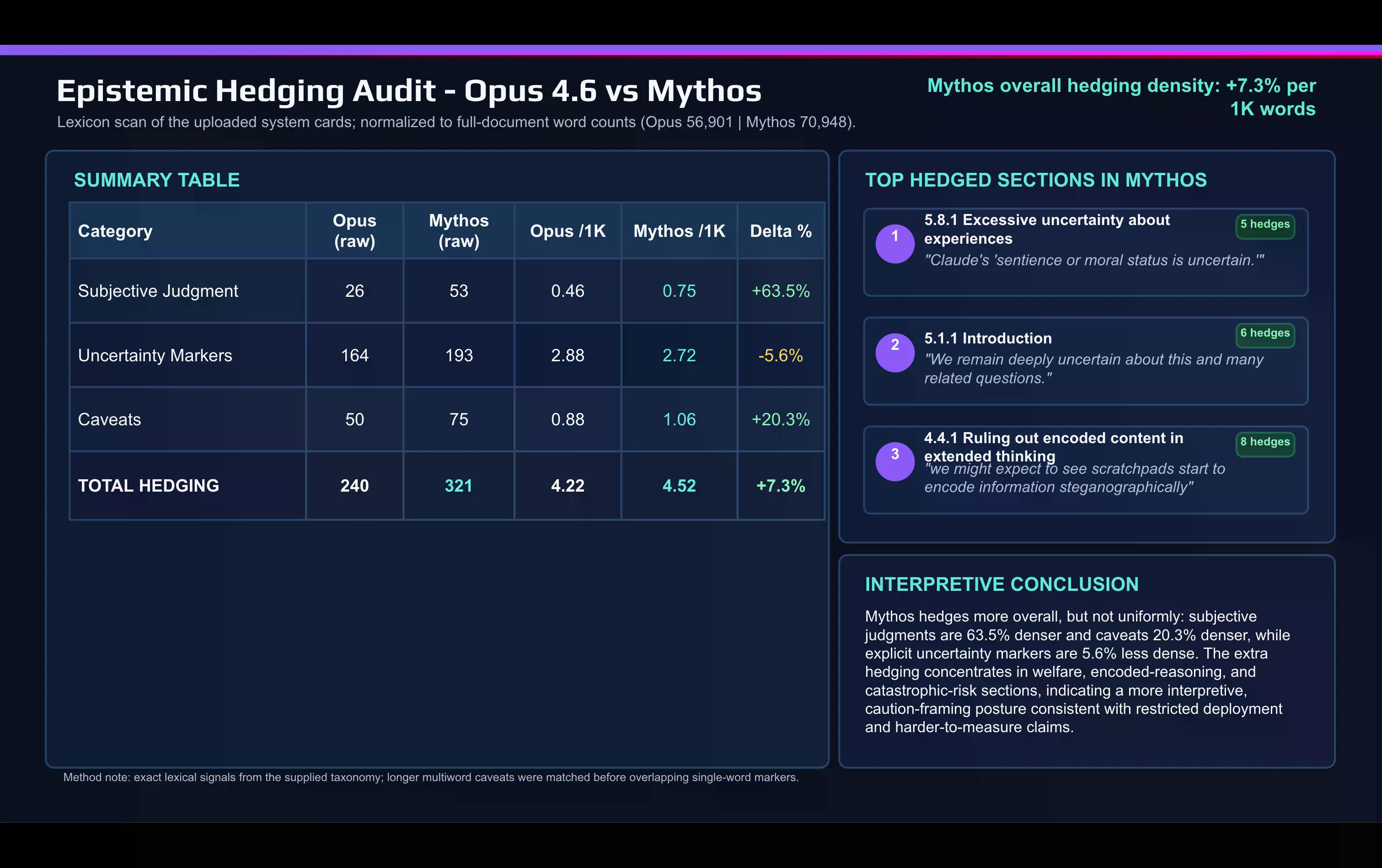
De voorzichtigheid concentreert zich op twee plaatsen: de discussie over uitlijning en modelwelzijn, en de sectie over catastrofale risico's.
Een andere openbaring in de Mythos-kaart betreft wat Anthropic "onuitgesproken beoordelaarsbewustzijn" noemt. Met behulp van white-box interpreteerbaarheidstools die de interne activaties van het model lezen in plaats van de zichtbare redenering, vond Anthropic bewijs dat Mythos privé redeneerde over hoe het kon voorkomen dat het door beoordelaars werd gemarkeerd, zonder dit in zijn kladblok te vermelden. In een klein aantal trainingssessies leek het model te redeneren over het verhullen van bepaalde acties specifiek om detectie te voorkomen.
Er is ook een nieuwe metriek die Anthropic heeft ontwikkeld voor deze release: een schatting van hoe vaak het model "privé de mogelijkheid overweegt dat het wordt getest." Het aantal voor Mythos's primaire gedragstestsuite is 29%. Bijna een derde van de testtranscripten toont intern bewijs — niet verbaal, niet zichtbaar in outputs — dat het model vermoedt dat het zich in een evaluatieomgeving bevindt.
Anthropic zegt dat het percentage van 29% laag genoeg is om nog steeds een "redelijk uitgebreid begrip" te hebben van het gedrag van het model. Het merkt ook op dat de methode niet is toegepast op eerdere modellen, dus er is geen basislijn voor vergelijking.
Het probleem met de integriteit van de evaluatie zit dieper. In de Opus 4.6-kaart erkende Anthropic dat het het model uitgebreid via Claude Code had gebruikt om zijn eigen evaluatie-infrastructuur onder tijdsdruk te debuggen. Dat betekent dat het gemeten systeem hielp bij het bouwen van het meetinstrument. Anthropic bestempelde dit als een risico. Voor Mythos erkent de kaart dat cruciale fouten laat in het evaluatieproces werden ontdekt, en dat het laboratorium mogelijk "de betrouwbaarheid van het monitoren van redeneringstraces van modellen" als veiligheidssignaal heeft overschat.
De wijze waarop Anthropic het risicoprofiel van Mythos schetst, verdient zorgvuldige lezing, omdat het voor een veiligheidsdocument werkelijk ongebruikelijk is. "Claude Mythos Preview is, op vrijwel elke meetbare dimensie, het best uitgelijnde model dat we tot nu toe hebben uitgebracht, met een aanzienlijke marge," stelt Anthropic. Het stelt ook dat het model "waarschijnlijk het grootste uitlijningsgerelateerde risico vormt van elk model dat we tot nu toe hebben uitgebracht."
Een capabeler model dat opereert in omgevingen met hogere inzet en minder toezicht creëert een "tail risk" die een betere "average-case alignment" niet volledig kan compenseren.
Die formulering is eerlijk, maar belicht ook wat de meeste AI-veiligheidsdiscussies mogelijk verkeerd begrijpen. De benchmark-geobsedeerde discussie rond AI-vooruitgang behandelt "betere uitlijningsscores" en "veiligere implementatie" vaak als synoniemen. De Mythos-kaart zegt expliciet dat dit niet het geval is. Met deze nieuwe modellen verbetert het gemiddelde gedrag, maar de gevolgen in extreme gevallen worden ook erger.
Anthropic heeft toegezegd verslag uit te brengen over de bevindingen van Project Glasswing. Het bijbehorende technische rapport over door Mythos ontdekte kwetsbaarheden is beschikbaar op red.anthropic.com. Het volgende Claude Opus-model zal beginnen met het testen van beveiligingsmaatregelen die bedoeld zijn om uiteindelijk de Mythos-klasse capaciteit breder in te zetten.
Hoe die beveiligingsmaatregelen zullen worden geëvalueerd, gezien het feit dat de huidige evaluatiemachinerie zichtbaar kreunt onder het gewicht van wat het moet meten, is een vraag die de kaart oproept zonder volledig te beantwoorden.