
Lab AI yang berbasis di Shanghai, StepFun, merilis StepAudio 2.5 Realtime minggu ini. Ini adalah model suara waktu nyata ujung-ke-ujung—audio masuk, audio keluar, tanpa konversi teks di tengah. Model ini mendukung bahasa Mandarin dan Inggris, dan berdasarkan benchmark, tampaknya cukup bagus.
Lab ini paling dikenal karena membangun LLM teks yang mengungguli sistem yang jauh lebih besar. Step 3.5 Flash, model dengan 196 miliar parameter, menduduki empat benchmark penalaran awal tahun ini melawan pesaing dengan triliun parameter. (Parameter adalah apa yang memberikan model AI keluasan pengetahuan, dan secara umum menghasilkan kinerja yang lebih baik.)
Pekerjaan suara ini mengikuti pola yang sama, dan ingin membuat roleplay menjadi menarik, terutama dalam sesi yang lebih panjang.
Masalah Karakter
Sistem persona AI memiliki mode kegagalan spesifik: OOC, atau perilaku keluar dari karakter—model menyimpang dari kepribadian yang ditugaskan di bawah tekanan adversaria. Ini sangat umum terjadi, dan merupakan cacat yang ada di semua model AI berdasarkan desain. Mereka hanya melupakan hal-hal semakin sering Anda berinteraksi dengan mereka.
StepFun mengatakan telah memecahkan masalah ini dengan RLHF spesifik roleplay—pembelajaran penguatan dari umpan balik manusia yang diterapkan secara khusus pada stabilitas persona, bukan hanya kualitas umum. Data pelatihan dimulai dari lebih dari 10.000 bibit persona yang ditulis manusia, yang diperluas secara algoritmik menjadi matriks fitur berskala jutaan.
Idenya: variasi yang cukup dalam data pelatihan sehingga bahkan percakapan yang aneh dan jarang tidak akan menggoyahkan karakter model.
Klaim yang lebih menarik secara teknis adalah pemahaman paralinguistik—model membaca isyarat akustik non-verbal seperti kecepatan vokal, nada emosional, dan usia dari audio itu sendiri, sebelum merumuskan respons.
Pada benchmark pemahaman paralinguistik—tes objektif yang mengukur persepsi fitur akustik seperti emosi dan kecepatan berbicara, dengan skor 0–100—StepAudio mencapai 82.18. GPT Realtime 1.5 mencetak 80.46, Gemini Live mencapai 58.05, dan DouBao Realtime berada di 16.09.
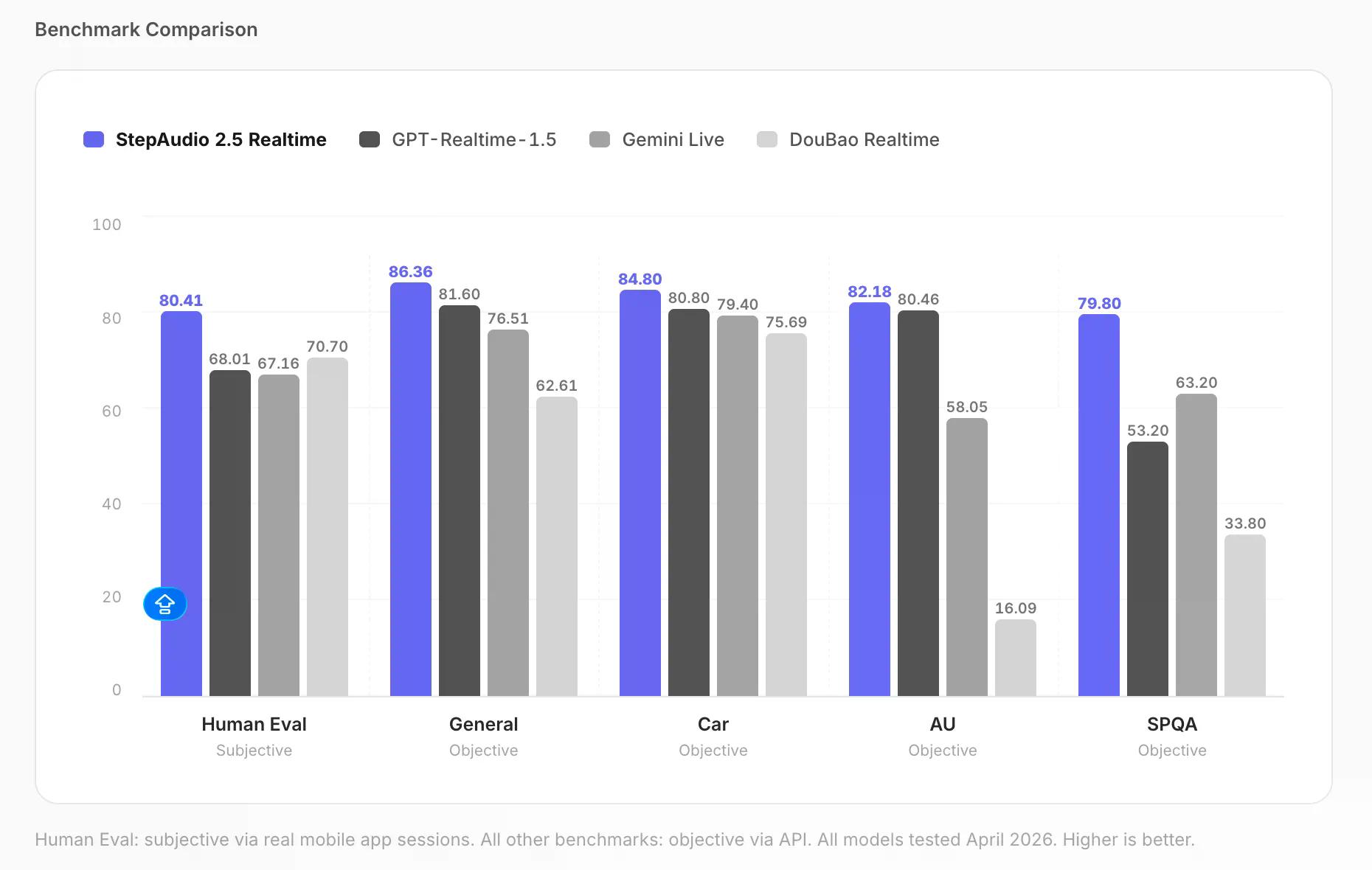
Benchmark evaluasi manusia—pengguna nyata berbicara dengan model melalui aplikasi seluler, dinilai oleh penilai manusia pada skala 0–100—menunjukkan 80.41 untuk StepAudio, dibandingkan 68.01 untuk GPT Realtime 1.5 dan 67.16 untuk Gemini Live. Kualitas dialog umum, diuji secara objektif melalui API pada skala 0–100 yang sama, mencapai 86.36 dibandingkan 81.60 milik GPT.
Ini adalah benchmark milik StepFun sendiri. Terserah Anda mau memaknainya bagaimana. Namun, selisih pada paralinguistik dan sesi tanya jawab lisan cukup besar sehingga sulit untuk diabaikan.
Konteks StepFun
StepFun didirikan pada April 2023 oleh Jiang Daxin, yang menghabiskan 16 tahun di Microsoft mengelola proyek seperti Bing, Cortana, dan layanan kognitif Azure. Ini adalah salah satu startup "AI Tiger" di Tiongkok dan telah mengumpulkan sekitar $1,7 miliar hingga saat ini.
Mode suara canggih OpenAI diluncurkan pada akhir 2024 dan menetapkan benchmark yang dikejar semua orang. StepFun sekarang melakukan benchmark langsung terhadapnya—dan mengklaim kemenangan.
Peluncuran ini mencakup persona AI unggulan bernama Xiao Yue, yang digambarkan StepFun sebagai "pendamping tingkat jiwa" yang dirancang agar terasa seperti mengirim pesan kepada teman, bukan menanyakan perangkat lunak. Opini, frasa khas, batasan emosional—semuanya dapat dikonfigurasi sepenuhnya.
Pengembang dapat membangun persona mereka sendiri melalui API. Dokumentasi lengkap tersedia di platform.stepfun.com, dan model ini sudah aktif sekarang.