
CEO Nvidia Jensen Huang tampil di podcast Lex Fridman minggu lalu dan menyatakan dengan jelas, "Saya pikir kita telah mencapai AGI." Dua hari kemudian, uji coba paling ketat dalam penelitian AI merilis benchmark kecerdasan umum buatan terbarunya—dan setiap model mutakhir mencetak di bawah 1%.
ARC Prize Foundation merilis ARC-AGI-3 minggu ini, dan hasilnya sangat brutal. Google Gemini 3.1 Pro memimpin dengan 0,37%. OpenAI GPT-5.4 meraih 0,26%. Anthropic Claude Opus 4.6 berhasil mencapai 0,25%, sementara xAI Grok-4.20 mencetak persis nol. Sementara itu, manusia menyelesaikan 100% lingkungan.
Ini bukan tes trivia atau ujian coding, atau bahkan pertanyaan tingkat PhD yang sangat sulit. ARC-AGI-3 adalah sesuatu yang sama sekali berbeda dari apa pun yang pernah dihadapi industri AI sebelumnya.
Benchmark ini dibangun oleh yayasan François Chollet dan Mike Knoop, yang mendirikan studio game internal dan menciptakan 135 lingkungan interaktif asli dari awal. Idenya adalah menjatuhkan agen AI ke dunia seperti game yang tidak dikenal tanpa instruksi, tanpa tujuan yang dinyatakan, dan tanpa deskripsi aturan. Agen harus menjelajahi, mencari tahu apa yang harus dilakukannya, membuat rencana, dan melaksanakannya.
Jika itu terdengar seperti sesuatu yang bisa dilakukan oleh anak berusia lima tahun, Anda mulai memahami masalahnya. Jika Anda ingin melihat apakah Anda lebih baik dari AI, Anda bisa memainkan game yang sama yang ditampilkan dalam tes dengan mengklik tautan ini. Kami mencoba salah satunya; awalnya aneh, tetapi setelah beberapa detik, Anda bisa dengan mudah memahaminya.
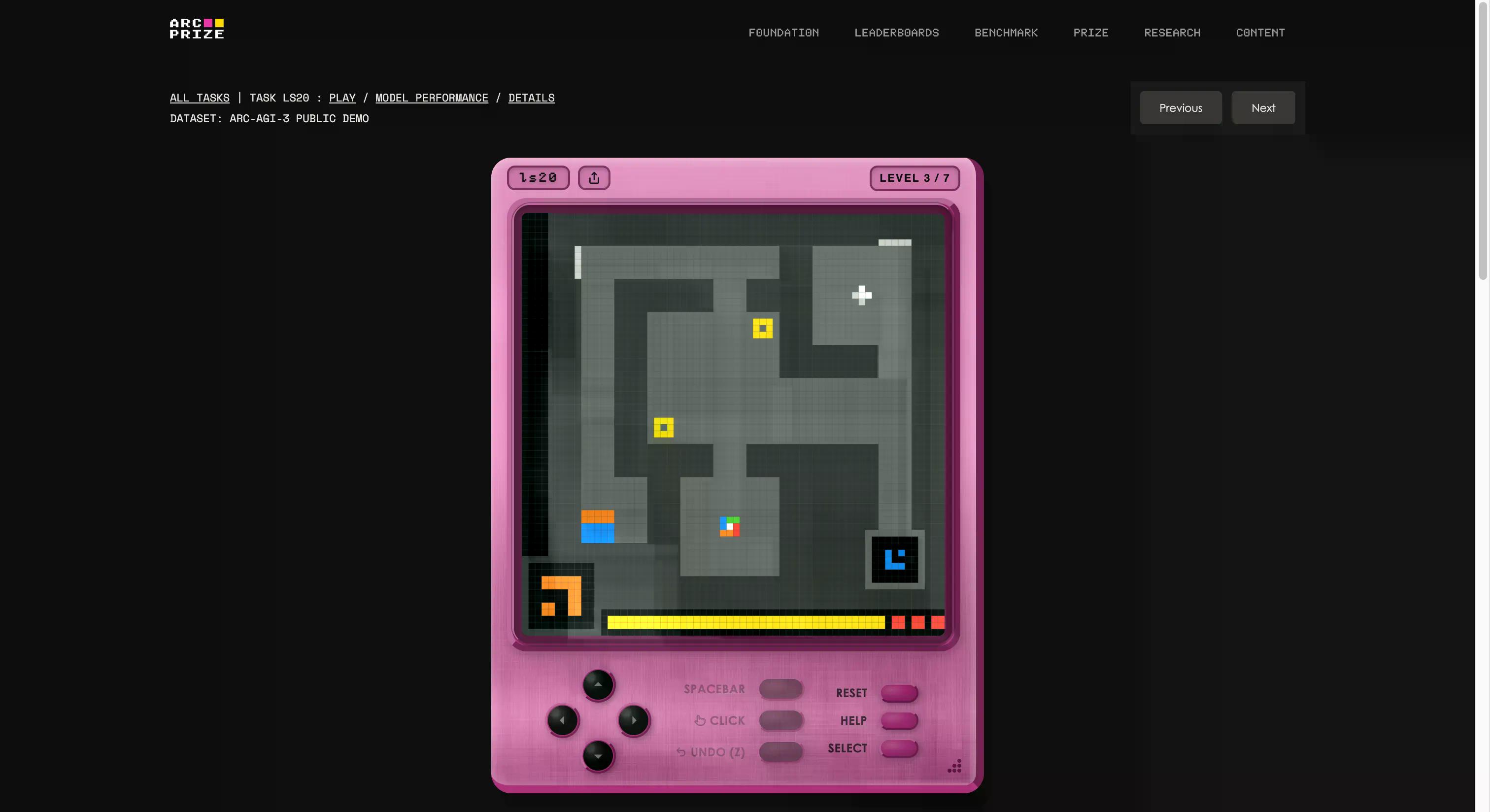
Ini juga merupakan contoh paling jelas dari makna "G" dalam AGI. Ketika Anda melakukan generalisasi, Anda mampu menciptakan pengetahuan baru (cara kerja game yang aneh) tanpa dilatih sebelumnya.
Versi ARC sebelumnya menguji puzzle visual statis—menunjukkan pola, memprediksi pola berikutnya. Awalnya sulit. Kemudian laboratorium mengerahkan daya komputasi dan pelatihan sampai benchmark tersebut secara efektif tidak berlaku lagi. ARC-AGI-1, yang diperkenalkan pada tahun 2019, kalah oleh pelatihan waktu uji dan model penalaran. ARC-AGI-2 bertahan sekitar satu tahun sebelum Gemini 3.1 Pro mencapai 77,1%. Laboratorium sangat pandai dalam menjenuhkan benchmark yang bisa mereka latih.
Versi 3 dirancang khusus untuk mencegah hal itu. Dengan 110 dari 135 lingkungan yang dirahasiakan—55 semi-pribadi untuk pengujian API, 55 sepenuhnya dikunci untuk kompetisi—tidak ada kumpulan data untuk dihafal. Anda tidak bisa memecahkan secara paksa logika game baru yang belum pernah Anda lihat.
Penilaian juga bukan lulus/gagal. ARC-AGI-3 menggunakan apa yang disebut yayasan sebagai RHAE—Relative Human Action Efficiency (Efisiensi Tindakan Manusia Relatif). Dasar penilaian adalah kinerja manusia terbaik kedua pada percobaan pertama. AI yang membutuhkan sepuluh kali lebih banyak tindakan daripada manusia mencetak 1% untuk level tersebut, bukan 10%. Formula ini mengkuadratkan penalti untuk inefisiensi. Berkeliaran, mundur, dan menebak jalan menuju jawaban akan dihukum berat.
Agen AI terbaik dalam pratinjau pengembang selama sebulan mencetak 12,58%. LLM mutakhir yang diuji melalui API resmi, tanpa alat kustom, tidak bisa mencapai 1%. Manusia biasa menyelesaikan semua 135 lingkungan tanpa pelatihan sebelumnya dan tanpa instruksi. Jika itu standarnya, maka model-model yang ada saat ini belum mampu melampauinya.
Ada satu perdebatan metodologis nyata di sini. Laporan ARC menyatakan bahwa sebuah perangkat kustom buatan Duke mendorong Claude Opus 4.6 dari 0,25% menjadi 97,1% pada varian lingkungan tunggal yang disebut TR87. Itu tidak berarti Claude mencetak 97,1% pada keseluruhan ARC-AGI-3; skor benchmark resminya tetap 0,25%, tetapi pergeseran ini tetap perlu dicatat.
Benchmark resmi memberi agen kode JSON, bukan visual. Itu bisa menjadi kelemahan metodologis atau demonstrasi bahwa model saat ini lebih baik dalam memproses informasi yang ramah manusia daripada data terstruktur mentah. Yayasan Chollet telah mengakui perdebatan ini, tetapi tidak mengubah formatnya.
"Persepsi konten bingkai dan format API bukan faktor pembatas kinerja model mutakhir pada ARC-AGI-3," demikian isi makalah tersebut. Dengan kata lain, mereka tampaknya menolak gagasan bahwa model gagal karena mereka "tidak dapat melihat" tugas dengan benar, sebaliknya berargumen bahwa persepsi sudah cukup—dan kesenjangan sebenarnya terletak pada penalaran dan generalisasi.
Pemeriksaan realitas AGI tiba pada minggu ketika mesin promosi berjalan dengan kecepatan penuh. Selain komentar Huang, Arm menamai chip pusat datanya yang baru sebagai "CPU AGI." Sam Altman dari OpenAI telah mengatakan bahwa mereka "pada dasarnya telah membangun AGI," dan Microsoft sudah memasarkan lab yang berfokus pada pembangunan ASI: Evolusi dari apa yang datang setelah AGI tercapai. Istilah ini diregangkan sampai berarti apa pun yang nyaman secara komersial, tampaknya.
Posisi Chollet lebih sederhana. Jika manusia normal tanpa instruksi bisa melakukannya, dan sistem Anda tidak bisa, maka Anda tidak memiliki AGI—Anda memiliki pelengkapan otomatis yang sangat mahal yang membutuhkan banyak bantuan.
ARC Prize 2026 menawarkan $2 juta di tiga jalur kompetisi, semuanya diselenggarakan di Kaggle. Setiap solusi pemenang harus bersumber terbuka. Waktu terus berjalan, dan saat ini, mesin-mesin itu bahkan belum mendekati.