
एआई पर्सनल असिस्टेंट्स के लिए हमेशा यही बात कही गई है: एजेंट को अपनी डिजिटल लाइफ तक पहुंच दें और वह बाकी सब संभाल लेगा। आपके ईमेल, आपका कैलेंडर, आपके नोट्स, आपके डिवाइस—यह सब कुछ। आपका एआई जानता है। आपका एआई काम करता है। आप सोते हैं।
हुआवेई टेक्नोलॉजीज, बीजिंग इंस्टीट्यूट ऑफ टेक्नोलॉजी, पेकिंग यूनिवर्सिटी और चाइनीज एकेडमी ऑफ साइंसेज के शोधकर्ताओं ने अभी-अभी एक बेंचमार्क बनाया है यह देखने के लिए कि क्या यह वास्तव में सच है। स्पॉयलर: ऐसा नहीं है।
Claw-Anything एआई एजेंट्स का एक साथ तीन आयामों पर मूल्यांकन करता है: तीन महीने से अधिक की सिम्युलेटेड उपयोगकर्ता गतिविधि को कवर करने वाले लंबे-क्षितिज इवेंट स्ट्रीम, प्रति कार्य औसतन 10.1 इंटरडिपेंडेंट बैकएंड सेवाएं, और CLI लिनक्स वातावरण और GUI एंड्रॉइड वातावरण दोनों में मल्टी-डिवाइस इंटरैक्शन।
प्रति कार्य औसत संदर्भ विंडो 191,700 शब्द है। अधिकांश मौजूदा बेंचमार्क 1,700 और 12,000 के बीच कहीं होते हैं। यह कोई छोटा अंतर नहीं बल्कि पूरी तरह से एक अलग समस्या है। यह भी वैसा ही है जैसा वास्तविक जीवन में महसूस होता है, मानकीकृत अति विशिष्ट बेंचमार्क के विपरीत।
आपके एआई को नहीं पता क्या हो रहा है
बेंचमार्क को पास@1 पर स्कोर किया जाता है—एजेंट के पहली कोशिश में, बिना दोबारा प्रयास के, कार्य को सही ढंग से पूरा करने की संभावना। एक कार्य एजेंट से पूछ सकता है कि वह हफ्तों पहले मिले उत्पाद पर मूल्य अलर्ट को क्रॉस-रेफरेंस करे, उपयोगकर्ता के कैलेंडर में एक प्रासंगिक अपॉइंटमेंट की जांच करे, और फ़ोन से दोनों पर कार्रवाई करे। दूसरा उसे नोट्स, ईमेल थ्रेड्स और स्लैक से हाल के काम को निकालने और फिर शुरुआत से एक प्रेजेंटेशन तैयार करने के लिए कह सकता है।
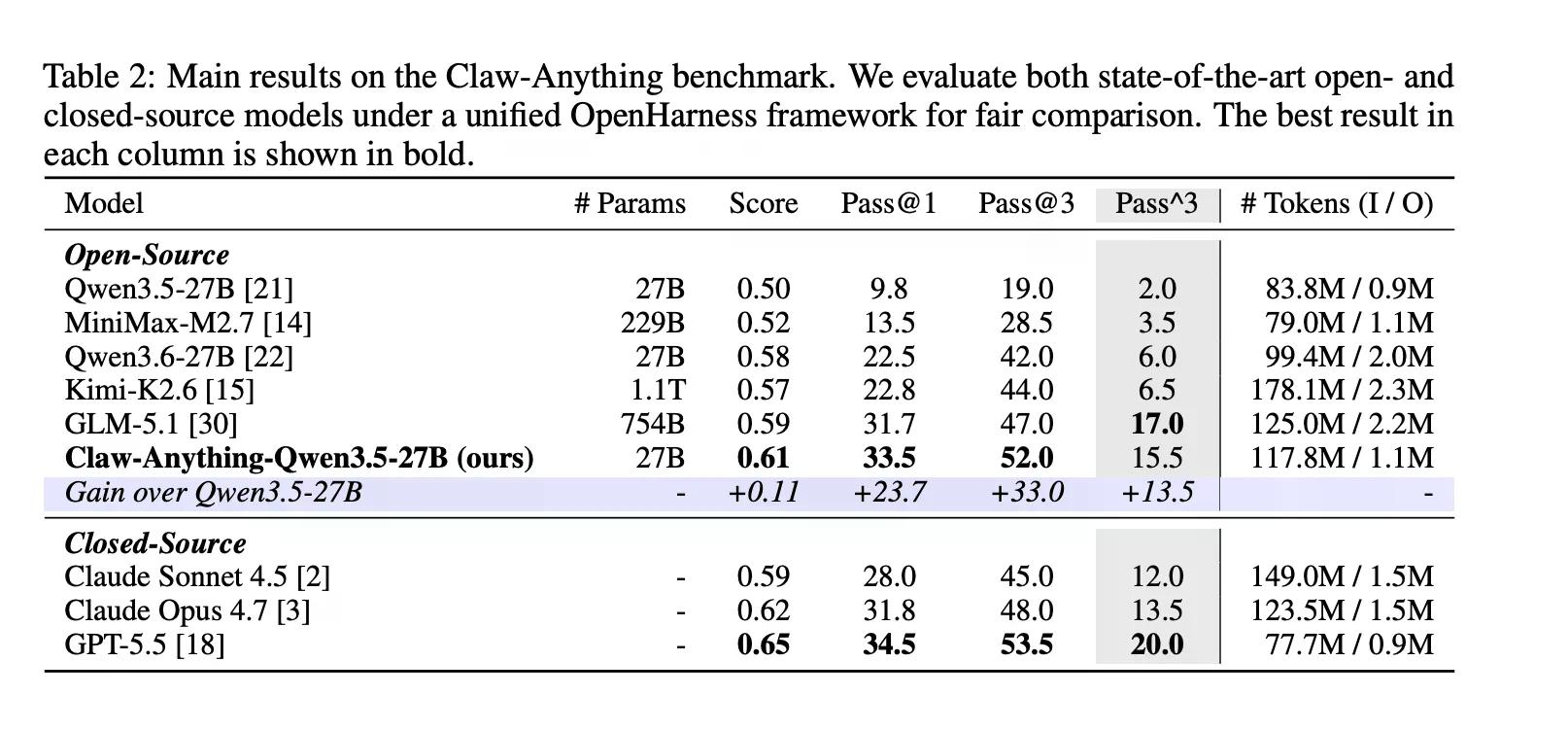
ये ऐसी चीजें हैं जो लोग वास्तव में सहायकों से करवाते हैं। पता चला कि एआई उनमें बहुत अच्छा नहीं है। डिक्रिप्ट की पिछली कवरेज के अनुसार, GPT-5.5 ओपनएआई का सबसे अच्छा मॉडल है, जिसे एजेंटिक, दीर्घकालिक कार्यों को ध्यान में रखकर बनाया गया है। इसने 34.5% स्कोर किया।
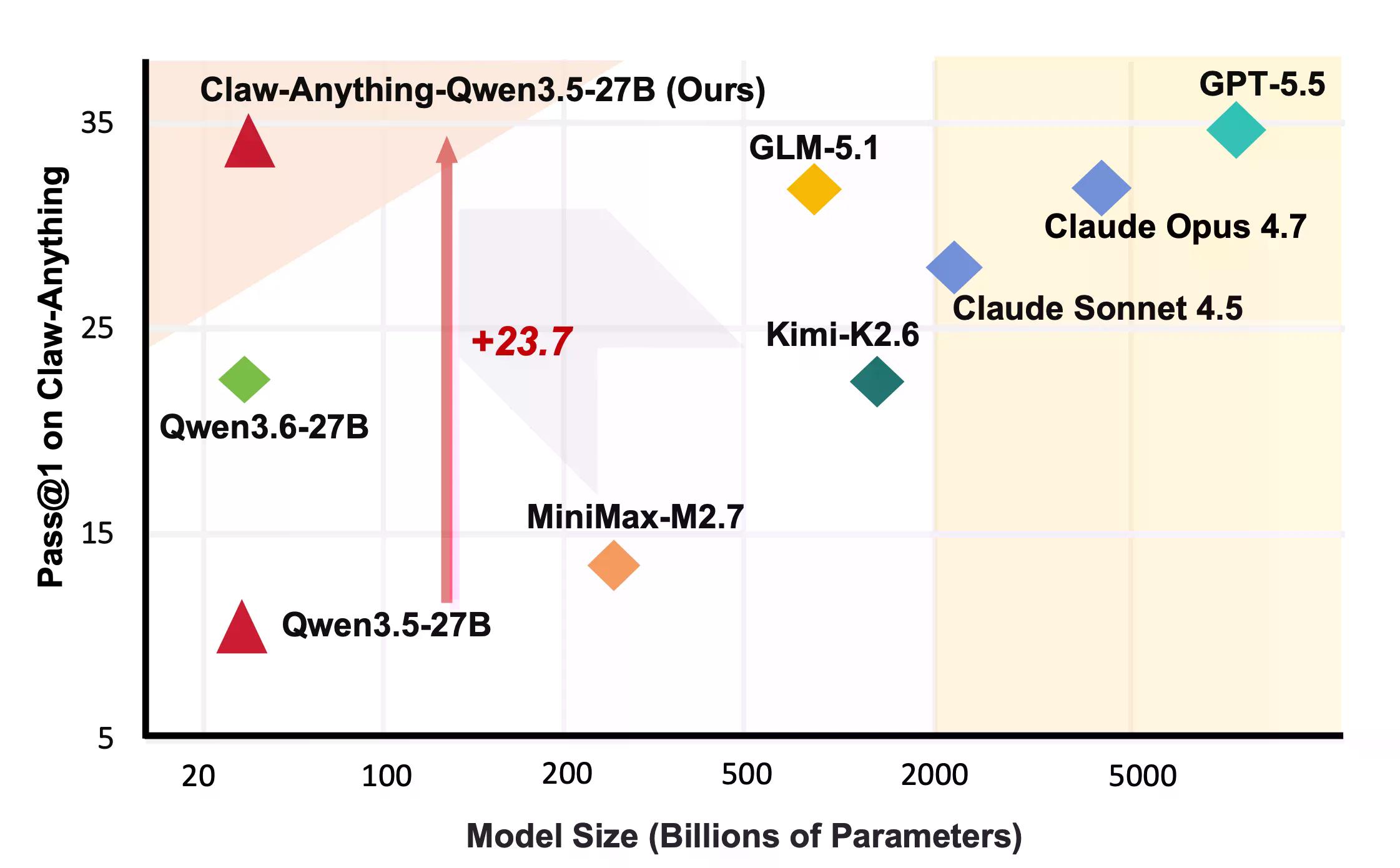
"वर्तमान मॉडल उपयोगकर्ता की डिजिटल दुनिया तक व्यापक पहुंच दिए जाने पर भी अविश्वसनीय बने हुए हैं," Claw-Anything पेपर में लिखा है। अन्य बेंचमार्क पर प्रभावशाली दिखने वाले कई मॉडल और भी नीचे गिर गए।
बेंचमार्क सक्रिय सहायता को भी अलग से ग्रेड करता है, जिसका अर्थ है ऐसे मामले जहां एजेंट किसी आवश्यकता को पहचानता है और बिना पूछे कार्य करता है। अधिकांश बेंचमार्क इसका परीक्षण नहीं करते। Claw-Anything ऐसा करता है, और अंतर स्पष्ट है: एजेंट्स ने रिएक्टिव कार्यों पर 25.9% और प्रोएक्टिव कार्यों पर सिर्फ 6.7% स्कोर किया।
क्यों अधिकांश बेंचमार्क आपको यह नहीं बताते
शोधकर्ताओं ने एक महत्वपूर्ण तर्क दिया है: मौजूदा बेंचमार्क एआई एजेंट्स को ऐसे कार्य हल करने वाले के रूप में मानते हैं जिन्हें एक साफ-सुथरी मेज दी गई हो। Claw-Anything उन्हें ऐसे व्यक्तिगत सहायकों के रूप में मानता है जिन्हें वास्तविक, अव्यवस्थित जीवन में डाल दिया गया हो — अप्रासंगिक घटनाएं, विरोधाभासी संकेत, महीनों का जमा हुआ शोर। एजेंट को कुछ भी उपयोगी करने से पहले यह पता लगाना होता है कि क्या प्रासंगिक है।
एब्लेशन परिणामों से मल्टी-सर्विस निर्भरता विशेष रूप से स्पष्ट हो जाती है। जब क्रॉस-सर्विस कार्यों के लिए आवश्यक उपकरण हटा दिए गए, तो सफलता दर लगभग शून्य पर गिर गई, क्योंकि अधिकांश कार्यों के लिए एजेंट्स को एक ही बैकएंड के भीतर काम करने के बजाय कई बैकएंड्स में जानकारी प्राप्त करने और कार्य करने की आवश्यकता होती है।
यह एआई मूल्यांकन में समस्या का कोई नया प्रकार नहीं है। ओपनएआई ने इस साल की शुरुआत में SWE-बेंच को दूषित घोषित कर दिया था, जब कम लीकेज-प्रवण संस्करण पर स्कोर लगभग 70% से 23% तक गिर गए थे। वह डेटा स्वच्छता के बारे में था। यह कुछ अधिक मौलिक बात के बारे में है — कि क्या बेंचमार्क सही प्रश्न भी पूछ रहे हैं।
रचनात्मक पक्ष पर, टीम ने उस पाइपलाइन को जारी किया जिसने 2,000 प्रशिक्षण वातावरण के साथ बेंचमार्क तैयार किया। 1,500 सफल एजेंट ट्रेजेक्टरीज पर Qwen3.5-27B को फाइन-ट्यून करने से पास@1 में 23.7% का सुधार हुआ — जो क्लोड सोननेट सहित लीडरबोर्ड पर कई क्लोज्ड-सोर्स मॉडलों को हराने के लिए पर्याप्त है।
शोधकर्ताओं ने क्रॉस-सर्विस समन्वय को इस क्षेत्र के लिए बेंचमार्क की प्राथमिक शेष चुनौती के रूप में पहचाना है। डेटासेट हगिंग फेस पर और कोड गिटहब पर उपलब्ध है।