
दुनिया के पांच सबसे उन्नत AI सिस्टम से पूछें कि क्या कोई कथन सत्य है, और दो-तिहाई बार, कम से कम एक आपको अलग जवाब देगा। यह इस महीने लेन्ज़ रिसर्च के शोधकर्ता कोस्टा जॉर्डनोव द्वारा प्रकाशित एक नए अध्ययन का निष्कर्ष है।
अध्ययन ने GPT-5.4, क्लाउड ओपस 4.7, जेमिनी 3 प्रो, सर्च के साथ जेमिनी 3 प्रो, और सोनार प्रो को वास्तविक उपयोगकर्ताओं द्वारा प्रस्तुत किए गए 1,000 वास्तविक-विश्व तथ्य-जाँच दावे दिए। मॉडलों को चार लेबलों में से एक चुनना था: सत्य, अधिकतर सत्य, भ्रामक, या असत्य।
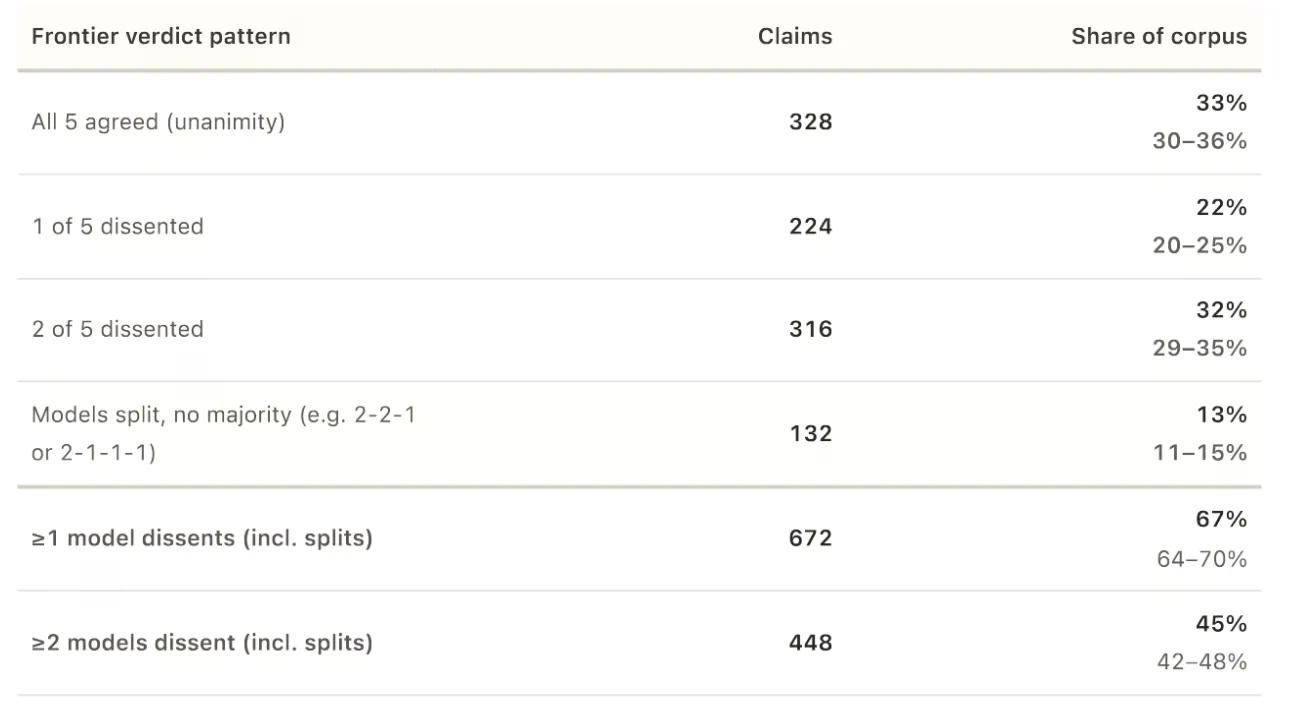
1,000 दावों में से 672 पर, कम से कम एक मॉडल बहुमत से अलग राय रखता था। 34% मामलों में, असहमति गंभीर थी: एक मॉडल ने दावे को सत्य कहा जबकि दूसरे ने इसे असत्य कहा।
“ये सार्वजनिक उत्तर कुंजियों वाले बेंचमार्क आइटम नहीं हैं—ये वे दावे हैं जिन्हें वास्तविक उपयोगकर्ताओं ने एक तथ्य-जाँच प्लेटफ़ॉर्म पर सत्यापन के लिए प्रस्तुत किया था,” अध्ययन में कहा गया है। “प्रति दावे केवल एक ही फैसला सही हो सकता है, इसलिए पैनल के बीच कोई भी असहमति का मतलब है कि कम से कम एक मॉडल का फैसला इस 4-श्रेणी के मानदंड के तहत लेबल-असंगत है।”
AI हेलुसिनेशन पर पिछले अध्ययनों से पता चला है कि चैटबॉट तथ्य गढ़ते हैं। वह एक समस्या है। यह एक अलग समस्या है। मॉडल जरूरी नहीं कि चीजें गढ़ रहे हों, वे बस एक ही सामग्री के बारे में बुनियादी तथ्यात्मक निर्णयों पर सहमत नहीं हो सकते।
अनुसंधान ने एक ऐसा सेटअप इस्तेमाल किया जो AI कंपनियों के लिए इसे समझाना मुश्किल बनाता है। मानक परीक्षण सेट से दावों को निकालने के बजाय—जो अक्सर प्रशिक्षण डेटा में लीक हो जाते हैं—शोधकर्ताओं ने वास्तविक लोगों द्वारा लेन्ज़ के तथ्य-जाँच प्लेटफ़ॉर्म पर प्रस्तुत किए गए दावों का उपयोग किया। “इनमें से अधिकांश दावों के किसी भी प्रशिक्षण कॉर्पस में गोल्ड लेबल के साथ दिखाई देने की संभावना नहीं है—पैटर्न-मैच के लिए कोई प्रामाणिक उत्तर कुंजी नहीं है, कोई बेंचमार्क लीडरबोर्ड नहीं है जिस पर निर्भर रहा जा सके,” पेपर नोट करता है।
सहमति का सांख्यिकीय माप, जिसे क्रिपेनडॉर्फ का अल्फा कहा जाता है, 0.639 पर आया, जहाँ 1.0 का अर्थ पूर्ण सहमति और 0 का अर्थ यादृच्छिक संयोग है। अध्ययन कहता है कि यह “गैर-मामूली लेकिन सीमित सहमति” को इंगित करता है। शोधकर्ताओं ने नोट किया, “मॉडल के फैसले यादृच्छिक के बजाय संरचित हैं, लेकिन पैनल को एक एकल विनिमेय न्यायाधीश के रूप में मानने के लिए पर्याप्त सुसंगत नहीं हैं।” शोधकर्ता आमतौर पर 0.8 से नीचे किसी भी चीज़ को कमजोर मानते हैं।
जब सभी पांच मॉडल सहमत हुए—जो 1,000 दावों में से केवल 328 पर हुआ—तो वे लगभग कभी सहमत नहीं हुए कि कुछ भ्रामक या अधिकतर सत्य था। केवल चार दावों को सर्वसम्मत “भ्रामक” फैसला मिला। किसी को भी सर्वसम्मत “अधिकतर सत्य” फैसला नहीं मिला।
शोधकर्ताओं ने उदाहरण दावे प्रदान किए जहाँ AI मॉडलों ने सबसे अधिक विचलन दिखाया, जिसमें "विश्व बैंक का नाइजीरिया में सक्रिय पोर्टफोलियो 2025 तक $16.4 बिलियन से अधिक है।" ChatGPT 5.4 ने इसे "अधिकतर सत्य" कहा, जबकि जेमिनी 3 प्रो ने इसे "असत्य" कहा और इसके सिस्टर मॉडल जेमिनी 3 प्रो + सर्च ने इसे "भ्रामक" रेट किया।
एक अन्य उदाहरण में, मॉडलों को यह दावा दिया गया: "डोनाल्ड ट्रम्प ने कहा कि खाड़ी सहयोगियों के अनुरोध पर ईरान पर हमला स्थगित कर दिया गया था।" GPT-5.4 ने इसे असत्य कहा, क्लाउड ओपस 4.7 ने इसे अधिकतर सत्य कहा, जेमिनी 3 प्रो ने असत्य कहा, और जेमिनी 3 प्रो + सर्च ने इसे सत्य रेट किया।
शोधकर्ताओं ने पाया, “पैनल निश्चित फैसलों पर सहमत होता है; श्रेणी का मध्य भाग वह है जहाँ यह टूट जाता है।” सर्वसम्मति केवल चरम सीमाओं पर हुई: या तो दावा निश्चित रूप से सत्य था या निश्चित रूप से असत्य।
यह महत्वपूर्ण है क्योंकि लोग तथ्य-जाँच के लिए तेजी से AI सिस्टम की ओर रुख कर रहे हैं। यदि आप किसी समाचार लेख से कोई दावा ChatGPT, Claude, या Gemini में पेस्ट करते हैं, तो आपको तीन अलग-अलग उत्तर मिल सकते हैं। आप किस पर विश्वास करेंगे?
AI कंपनियाँ आपको यह बताना पसंद करती हैं कि उनके मॉडल अधिक सटीक हो रहे हैं। वे बेंचमार्क स्कोर प्रकाशित करते हैं जो स्थिर सुधार दिखाते हैं। लेकिन लेन्ज़ के अध्ययन ने इन मॉडलों का परीक्षण उस तरह के ऊबड़-खाबड़, अस्पष्ट दावों पर किया जिनके बारे में वास्तविक इंसान वास्तव में बहस करते हैं—और पाया कि मॉडल भी बहस करते हैं।
पेपर इस बात को सावधानीपूर्वक इंगित करता है। “अत्याधुनिक मॉडलों का बहुमत जमीनी सच्चाई नहीं है। बहुमत का फैसला कभी-कभी गलत होता है; एक व्यक्तिगत असहमति वाला मॉडल कभी-कभी सही होता है। हम असहमति को मापने के लिए बहुमत को एक संरचनात्मक संदर्भ बिंदु के रूप में उपयोग करते हैं, न कि शुद्धता के प्रतिस्थापन के रूप में।”
संख्याओं में एक गहरी समस्या छिपी है। जब मॉडल असहमत होते हैं, तो उनमें से कम से कम एक गलत होना चाहिए—अध्ययन एक मॉडल के फैसले को “इस 4-श्रेणी के मानदंड के तहत लेबल-असंगत” कहता है। कोई टाई-ब्रेकर तंत्र नहीं है, कोई अपील अदालत नहीं है। AI विश्वसनीयता पर हालिया रिपोर्टिंग ने भी इसी तरह की चिंताएँ उठाई हैं।
328 दावों में से, जहाँ सभी पांच मॉडल सहमत थे, किसी को भी सर्वसम्मत "अधिकतर सत्य" नहीं मिला। सूक्ष्मता वाली श्रेणी पूरी तरह से खाली हो गई। यदि AI मॉडल केवल चरम सीमाओं पर ही सहमति पा सकते हैं, तो क्या उन पर तथ्य-जाँचकर्ता के रूप में बिल्कुल भी भरोसा किया जा सकता है?