
آزمایشگاه هوش مصنوعی StepFun مستقر در شانگهای، این هفته StepAudio 2.5 Realtime را منتشر کرد. این یک مدل صوتی بیدرنگ و سرتاسری است—صدا وارد میشود، صدا خارج میشود، بدون تبدیل متن در این بین. از زبانهای چینی و انگلیسی پشتیبانی میکند و بر اساس معیارها، به نظر میرسد بسیار خوب است.
این آزمایشگاه بیشتر به خاطر ساخت مدلهای زبان بزرگ (LLM) متنی شناخته شده است که از سیستمهای بسیار بزرگتر عملکرد بهتری دارند. Step 3.5 Flash، یک مدل 196 میلیارد پارامتری، در اوایل سال جاری در چهار معیار استدلال در برابر رقبای تریلیون پارامتری، صدرنشین شد. (پارامترها همان چیزی هستند که به یک مدل هوش مصنوعی وسعت دانش میدهند و به طور کلی به عملکرد بهتر منجر میشوند.)
کار صوتی نیز از همین الگو پیروی میکند و میخواهد ایفای نقش را جذاب کند، به ویژه در جلسات طولانیتر.
مشکل شخصیت
سیستمهای شخصیتسازی هوش مصنوعی یک حالت شکست خاص دارند: OOC، یا رفتار خارج از شخصیت (out-of-character behavior)—مدل تحت فشار نامطلوب از شخصیت اختصاص داده شده خود فاصله میگیرد. این امر به طرز شرمآوری رایج است و نقصی است که به طور ذاتی در تمام مدلهای هوش مصنوعی وجود دارد. آنها هر چه بیشتر با آنها تعامل داشته باشید، چیزها را فراموش میکنند.
StepFun میگوید این مشکل را با RLHF مخصوص ایفای نقش حل کرده است—یادگیری تقویتی از بازخورد انسانی که به طور خاص برای ثبات شخصیت به کار رفته، نه فقط کیفیت عمومی. دادههای آموزشی از بیش از 10,000 دانه شخصیتسازی ایجاد شده توسط انسان شروع شده و به طور الگوریتمی به یک ماتریس ویژگی در مقیاس میلیونی گسترش یافته است.
ایده این است: تنوع کافی در دادههای آموزشی که حتی مکالمات عجیب و غریب و غیرمعمول نیز مدل را از شخصیت خود خارج نکند.
ادعای جالبتر از نظر فنی، درک پارالینگویستیک است—مدل قبل از اینکه پاسخی را فرموله کند، نشانههای آکوستیک غیرکلامی مانند سرعت صدا، لحن احساسی و سن را از خود صدا میخواند.
در معیار درک پارالینگویستیک—یک آزمون عینی که ادراک ویژگیهای آکوستیک مانند احساسات و سرعت گفتار را اندازهگیری میکند، با امتیاز 0-100—StepAudio به امتیاز 82.18 دست یافت. GPT Realtime 1.5 امتیاز 80.46، Gemini Live امتیاز 58.05 و DouBao Realtime امتیاز 16.09 را کسب کرد.
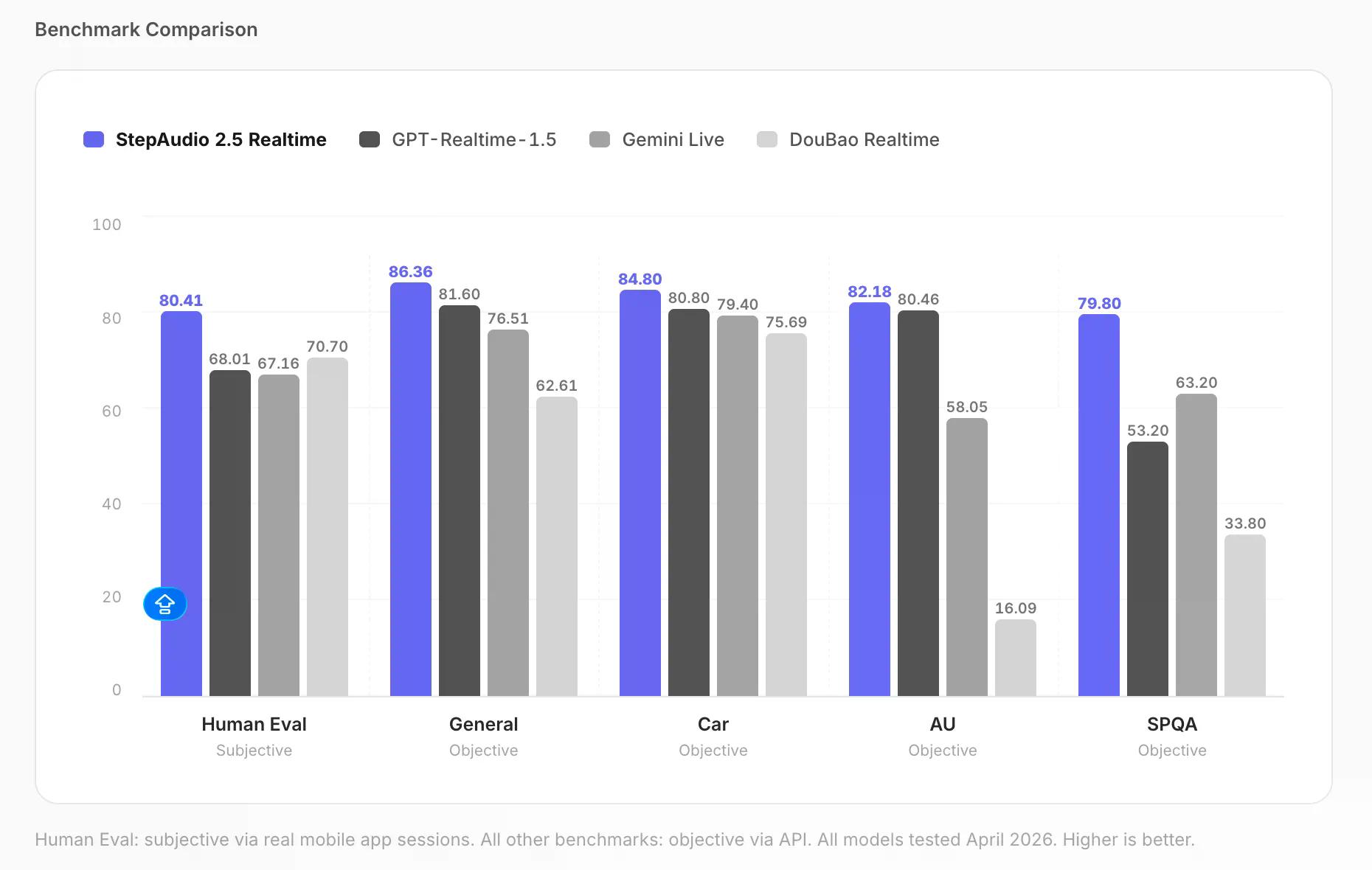
در معیار ارزیابی انسانی—کاربران واقعی که از طریق یک اپلیکیشن موبایل با مدل صحبت میکنند و توسط ارزیابان انسانی با مقیاس 0-100 امتیازدهی میشوند—StepAudio با امتیاز 80.41، در برابر 68.01 برای GPT Realtime 1.5 و 67.16 برای Gemini Live قرار گرفت. کیفیت کلی گفتگو، که به طور عینی از طریق API در همان مقیاس 0-100 آزمایش شد، 86.36 در برابر 81.60 برای GPT بود.
اینها معیارهای خود StepFun هستند. هر چه میخواهید از آن برداشت کنید. اما اختلاف امتیازات در پارالینگویستیک و جلسات پرسش و پاسخ شفاهی به قدری زیاد است که به سختی میتوان آنها را نادیده گرفت.
پیشینه StepFun
StepFun در آوریل 2023 توسط جیانگ داکسین (Jiang Daxin) تأسیس شد، او 16 سال را در مایکروسافت صرف مدیریت پروژههایی مانند بینگ، کورتانا و سرویسهای شناختی آژور کرد. این شرکت یکی از استارتاپهای به اصطلاح "ببرهای هوش مصنوعی" چین است و تاکنون حدود 1.7 میلیارد دلار سرمایه جذب کرده است.
حالت صوتی پیشرفته OpenAI در اواخر سال 2024 راهاندازی شد و معیاری را تعیین کرد که همه به دنبال آن هستند. StepFun اکنون به طور مستقیم با آن مقایسه میشود—و ادعای پیروزی میکند.
این راهاندازی شامل یک شخصیت هوش مصنوعی شاخص به نام Xiao Yue است که StepFun آن را "همراهی در سطح روح" توصیف میکند که برای ایجاد حس ارسال پیام به یک دوست طراحی شده، نه پرس و جو از نرمافزار. نظرات، عبارات کلیدی، محدودیتهای احساسی—کاملاً قابل تنظیم.
توسعهدهندگان میتوانند شخصیتهای خود را از طریق API بسازند. مستندات کامل در platform.stepfun.com موجود است و مدل هماکنون فعال است.