
La promesa de los asistentes personales de IA siempre ha sido la misma: Dale al agente acceso a tu vida digital y él se encarga del resto. Tus correos electrónicos, tu calendario, tus notas, tus dispositivos, todo. Tu IA lo sabe. Tu IA actúa. Tú duermes.
Investigadores de Huawei Technologies, el Instituto Tecnológico de Beijing, la Universidad de Pekín y la Academia China de Ciencias acaban de crear un benchmark para ver si eso es realmente cierto. Spoiler: No lo es.
Claw-Anything evalúa a los agentes de IA en tres dimensiones a la vez: flujos de eventos de largo plazo que cubren más de tres meses de actividad simulada del usuario, servicios de backend interdependientes con un promedio de 10.1 por tarea, e interacción multidispositivo tanto en entornos CLI Linux como GUI Android.
La ventana de contexto promedio por tarea es de 191,700 palabras. La mayoría de los benchmarks existentes se sitúan entre 1,700 y 12,000. Esa no es una pequeña brecha, sino un problema completamente diferente. También es a lo que se parece la vida real, a diferencia de los benchmarks estandarizados y ultra específicos.
Tu IA no tiene idea de lo que está pasando
El benchmark se puntúa con pass@1 —la probabilidad de que el agente complete una tarea correctamente en su primer intento, sin repeticiones. Una tarea podría pedirle al agente que cruce una alerta de precio de un producto que encontró hace semanas, revise el calendario del usuario para una cita relevante y actúe en ambos desde un teléfono. Otra podría pedirle que extraiga el trabajo reciente de notas, hilos de correo electrónico y Slack, y luego produzca una presentación desde cero.
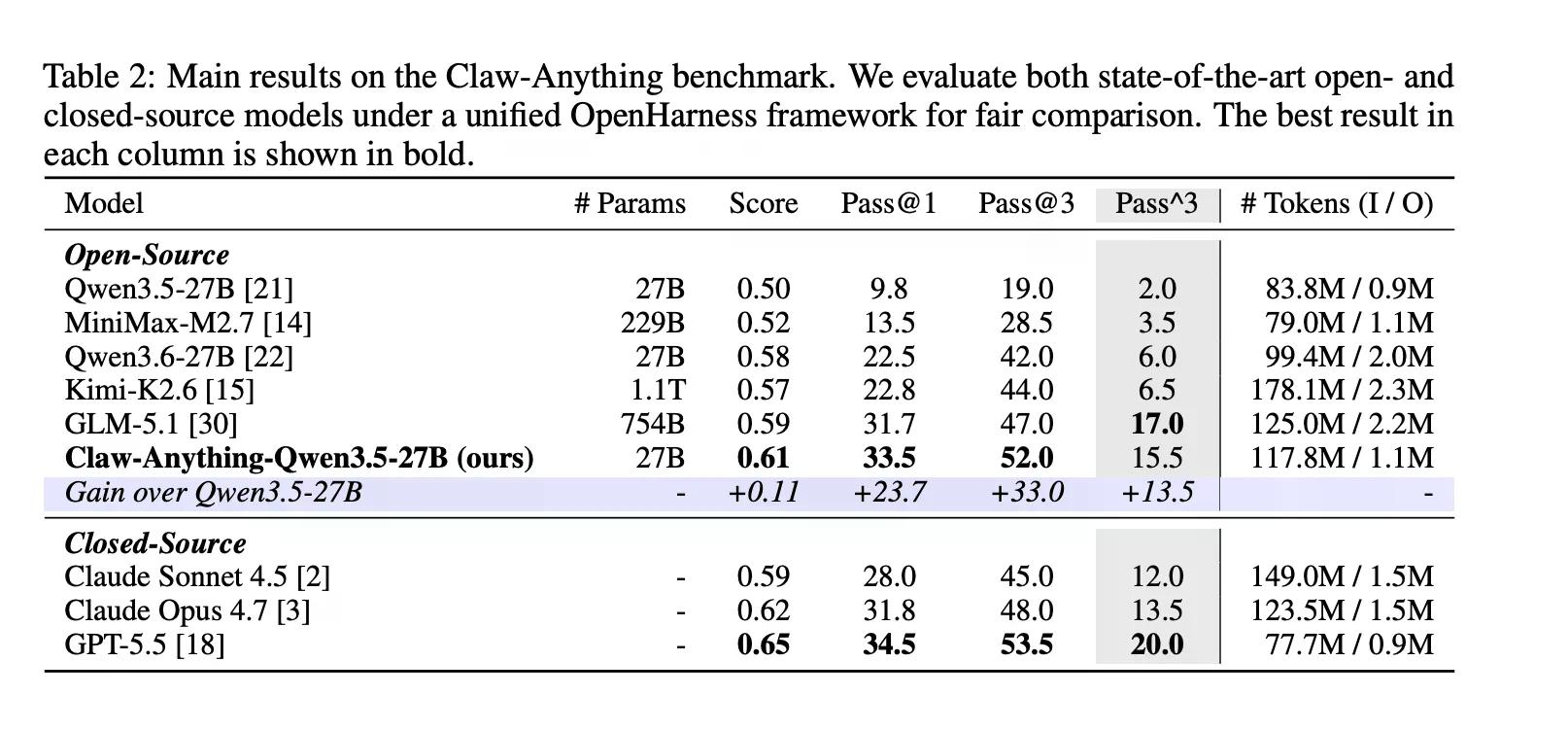
Estas son cosas que la gente realmente le pide a los asistentes que hagan. Resulta que la IA no es muy buena en ellas. GPT-5.5, según la cobertura anterior de Decrypt, es el mejor modelo de OpenAI, construido pensando en tareas agénticas y de largo plazo. Obtuvo un 34.5%.
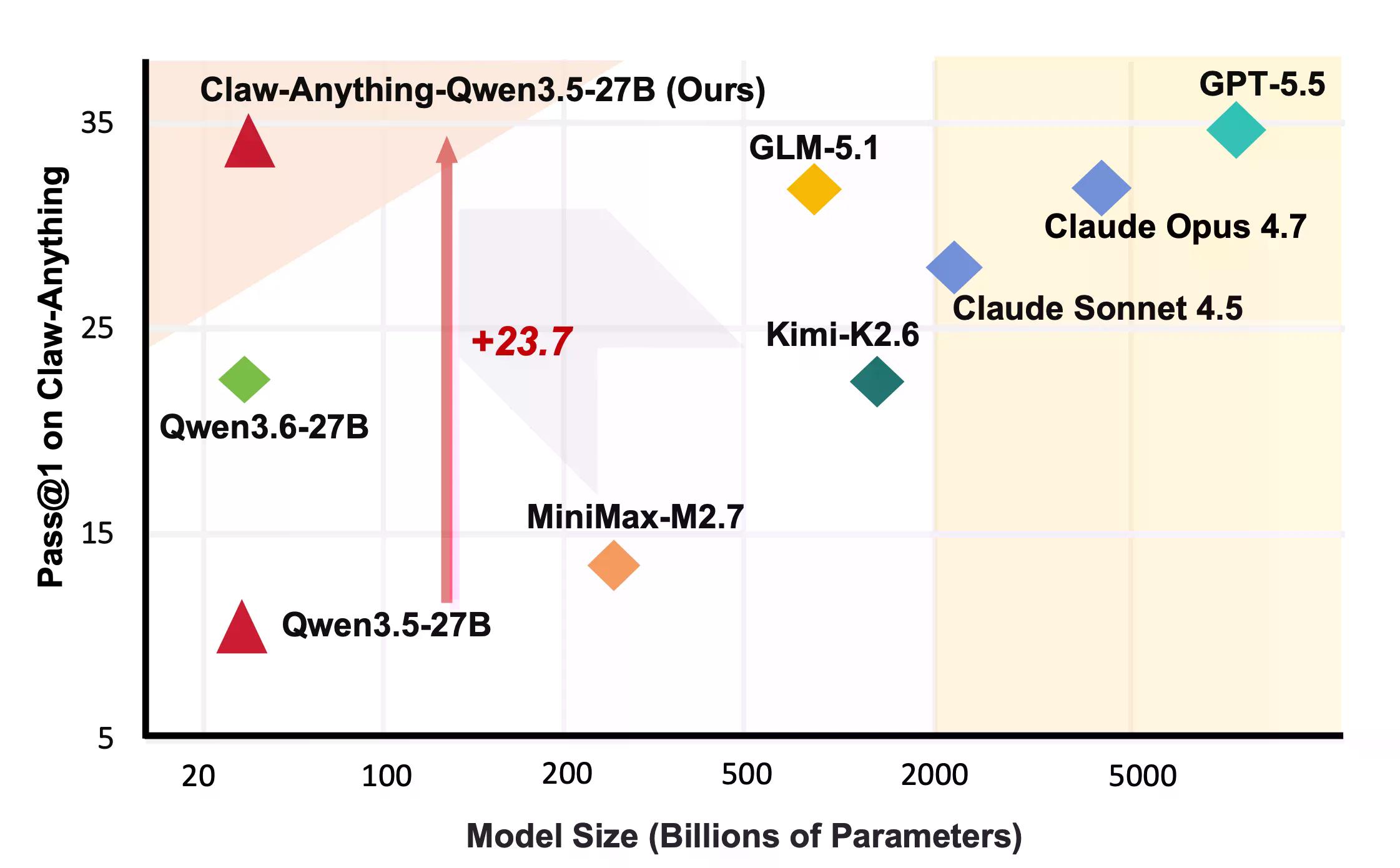
"Los modelos actuales siguen siendo poco fiables incluso cuando se les da un acceso más amplio al mundo digital del usuario", dice el artículo de Claw-Anything. Varios modelos que parecían impresionantes en otros benchmarks cayeron aún más.
El benchmark también califica la asistencia proactiva por separado, es decir, los casos en los que el agente detecta una necesidad y actúa sin que se le pida. La mayoría de los benchmarks no prueban esto. Claw-Anything sí lo hace, y la brecha es notable: Los agentes obtuvieron un 25.9% en tareas reactivas y solo un 6.7% en tareas proactivas.
Por qué la mayoría de los benchmarks no te dicen esto
Los investigadores presentan un argumento contundente: Los benchmarks existentes tratan a los agentes de IA como solucionadores de tareas a los que se les da un escritorio limpio. Claw-Anything los trata como asistentes personales que son arrojados a una vida real y desordenada —eventos irrelevantes, señales contradictorias, meses de ruido acumulado. El agente tiene que averiguar qué es relevante antes de poder hacer algo útil.
Los resultados de la ablación dejan especialmente clara la dependencia multiservicio. Cuando se eliminaron las herramientas necesarias para las tareas entre servicios, las tasas de éxito cayeron casi a cero, porque la mayoría de las tareas requieren que los agentes recuperen información y actúen a través de múltiples backends en lugar de dentro de uno solo.
Este no es un género nuevo de problema en la evaluación de la IA. OpenAI declaró SWE-bench contaminado a principios de este año después de que las puntuaciones colapsaran de aproximadamente un 70% a un 23% en una versión menos propensa a fugas. Eso se trataba de higiene de datos. Esto se trata de algo más fundamental: si los benchmarks están haciendo la pregunta correcta.
En el lado constructivo, el equipo lanzó la tubería que generó el benchmark junto con 2,000 entornos de entrenamiento. El ajuste fino de Qwen3.5-27B en 1,500 trayectorias exitosas de agentes mejoró el pass@1 en un 23.7% —suficiente para superar a varios modelos de código cerrado en la tabla de clasificación, incluido Claude Sonnet.
Los investigadores identifican la coordinación entre servicios como el principal desafío restante del benchmark para el campo. El conjunto de datos está en Hugging Face y el código está en GitHub.
