
Die Werbeaussage für KI-basierte persönliche Assistenten war schon immer dieselbe: Geben Sie dem Agenten Zugang zu Ihrem digitalen Leben und er erledigt den Rest. Ihre E-Mails, Ihr Kalender, Ihre Notizen, Ihre Geräte – alles davon. Ihre KI weiß Bescheid. Ihre KI handelt. Sie schlafen.
Forscher von Huawei Technologies, dem Beijing Institute of Technology, der Peking University und der Chinesischen Akademie der Wissenschaften haben soeben einen Benchmark erstellt, um zu sehen, ob das tatsächlich stimmt. Spoiler: Stimmt nicht.
Claw-Anything bewertet KI-Agenten gleichzeitig in drei Dimensionen: lange Ereignisströme, die über drei Monate simulierte Benutzeraktivität abdecken, voneinander abhängige Backend-Dienste mit durchschnittlich 10,1 pro Aufgabe und Multi-Geräte-Interaktion sowohl in CLI Linux-Umgebungen als auch in GUI Android-Umgebungen.
Das durchschnittliche Kontextfenster pro Aufgabe beträgt 191.700 Wörter. Die meisten bestehenden Benchmarks liegen irgendwo zwischen 1.700 und 12.000. Das ist keine kleine Lücke, sondern ein völlig anderes Problem. Es ist auch das, wonach sich das reale Leben anfühlt, im Gegensatz zu standardisierten ultraspezifischen Benchmarks.
Ihre KI hat keine Ahnung, was los ist
Der Benchmark wird nach pass@1 bewertet – der Wahrscheinlichkeit, dass der Agent eine Aufgabe beim ersten Versuch korrekt erledigt, ohne Wiederholungen. Eine Aufgabe könnte den Agenten auffordern, einen Preisalarm für ein Produkt, das er vor Wochen gefunden hat, abzugleichen, den Kalender des Benutzers nach einem relevanten Termin zu durchsuchen und beides von einem Telefon aus zu erledigen. Eine andere könnte ihn auffordern, aktuelle Arbeiten aus Notizen, E-Mail-Threads und Slack zusammenzustellen und dann eine Präsentation von Grund auf zu erstellen.
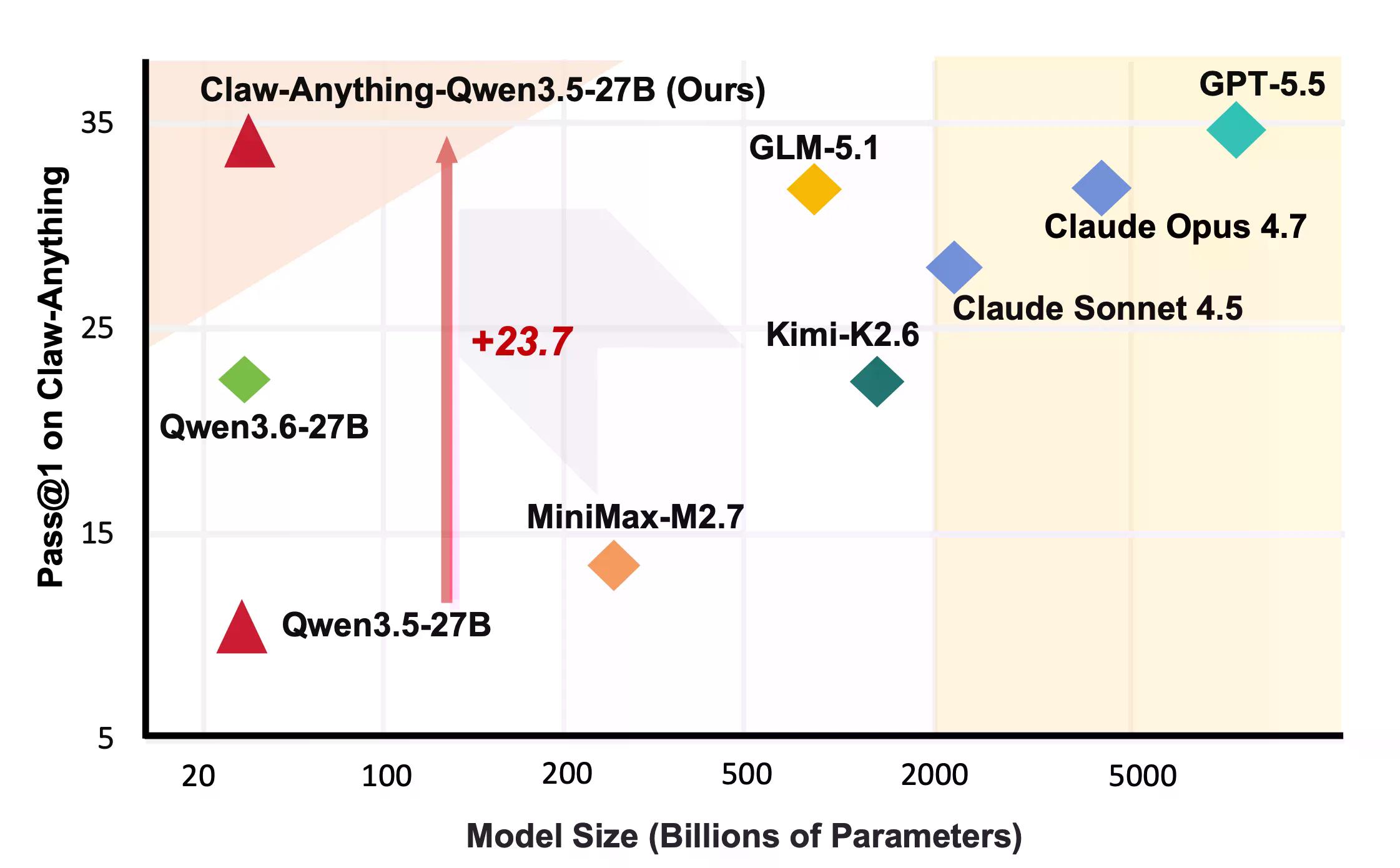
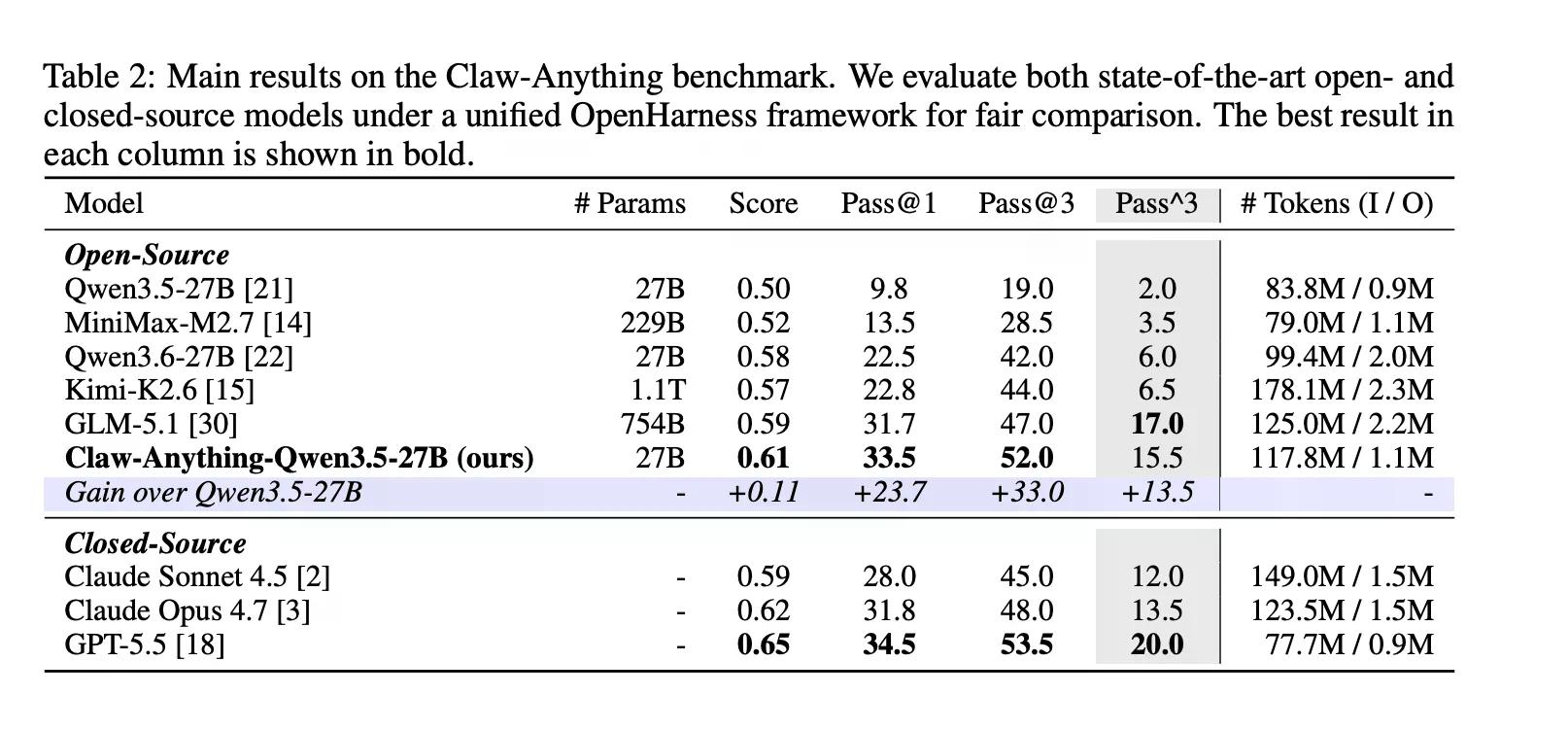
Das sind Dinge, die Menschen tatsächlich von Assistenten verlangen. Es stellt sich heraus, dass KI darin nicht sehr gut ist. GPT-5.5 ist laut früherer Berichterstattung von Decrypt OpenAIs bestes Modell, das mit Blick auf agentische, langfristige Aufgaben entwickelt wurde. Es erzielte 34,5 %.
"Aktuelle Modelle bleiben unzuverlässig, selbst wenn sie einen breiteren Zugang zur digitalen Welt des Benutzers erhalten", heißt es im Claw-Anything-Papier. Mehrere Modelle, die bei anderen Benchmarks beeindruckend aussahen, fielen weiter zurück.
Der Benchmark bewertet auch proaktive Unterstützung separat, d. h. Fälle, in denen der Agent einen Bedarf erkennt und ohne Aufforderung handelt. Die meisten Benchmarks testen dies nicht. Claw-Anything tut dies, und der Unterschied ist eklatant: Agenten erzielten 25,9 % bei reaktiven Aufgaben und nur 6,7 % bei proaktiven.
Warum die meisten Benchmarks Ihnen das nicht sagen
Die Forscher argumentieren pointiert: Bestehende Benchmarks behandeln KI-Agenten wie Problemlöser, denen ein sauberer Schreibtisch zur Verfügung gestellt wird. Claw-Anything behandelt sie wie persönliche Assistenten, die in ein tatsächlich unübersichtliches Leben geworfen werden – irrelevante Ereignisse, widersprüchliche Signale, Monate angesammelten Rauschens. Der Agent muss herausfinden, was relevant ist, bevor er etwas Nützliches tun kann.
Die Ablationsergebnisse verdeutlichen die Abhängigkeit von mehreren Diensten besonders. Als Werkzeuge, die für dienstübergreifende Aufgaben erforderlich waren, entfernt wurden, sanken die Erfolgsquoten auf nahezu Null, da die meisten Aufgaben erfordern, dass Agenten Informationen abrufen und über mehrere Backends hinweg agieren, anstatt innerhalb eines einzigen.
Dies ist kein neues Problem in der KI-Evaluierung. OpenAI erklärte SWE-bench Anfang des Jahres für kontaminiert, nachdem die Ergebnisse bei einer weniger leckageanfälligen Version von etwa 70 % auf 23 % gefallen waren. Dabei ging es um Datenhygiene. Hier geht es um etwas Grundlegenderes – ob die Benchmarks überhaupt die richtige Frage stellen.
Auf der konstruktiven Seite veröffentlichte das Team die Pipeline, die den Benchmark generierte, zusammen mit 2.000 Trainingsumgebungen. Das Fine-Tuning von Qwen3.5-27B auf 1.500 erfolgreichen Agententrajektorien verbesserte pass@1 um 23,7 % – genug, um mehrere Closed-Source-Modelle auf der Rangliste zu schlagen, darunter Claude Sonnet.
Die Forscher identifizieren die dienstübergreifende Koordination als die größte verbleibende Herausforderung des Benchmarks für das Feld. Der Datensatz ist auf Hugging Face und der Code auf GitHub verfügbar.