
Forscher bei Google DeepMind haben die wohl vollständigste Kartierung eines Problems veröffentlicht, das die meisten Menschen bisher nicht bedacht haben: das Internet selbst wird zu einer Waffe gegen autonome KI-Agenten. Das Paper mit dem Titel "AI Agent Traps" identifiziert sechs Kategorien von feindseligen Inhalten, die speziell darauf ausgelegt sind, Agenten zu manipulieren, zu täuschen oder zu kapern, während sie im offenen Web surfen, lesen und agieren.
Der Zeitpunkt ist entscheidend. KI-Unternehmen wetteifern darum, Agenten einzusetzen, die selbstständig Reisen buchen, E-Mails verwalten, Finanztransaktionen durchführen und Code schreiben können. Kriminelle setzen KI bereits offensiv ein. Staatlich unterstützte Hacker haben begonnen, KI-Agenten für Cyberangriffe im großen Stil einzusetzen. Und OpenAI gab im Dezember 2025 zu, dass die Kernschwachstelle, die diese Fallen ausnutzen – die sogenannte Prompt-Injektion – "unwahrscheinlich jemals vollständig 'gelöst' werden wird."
Die DeepMind-Forscher greifen nicht die Modelle selbst an. Die von ihnen kartierte Angriffsfläche ist die Umgebung, in der die Agenten operieren. Hier ist, was jede der sechs Fallenkategorien tatsächlich bedeutet.
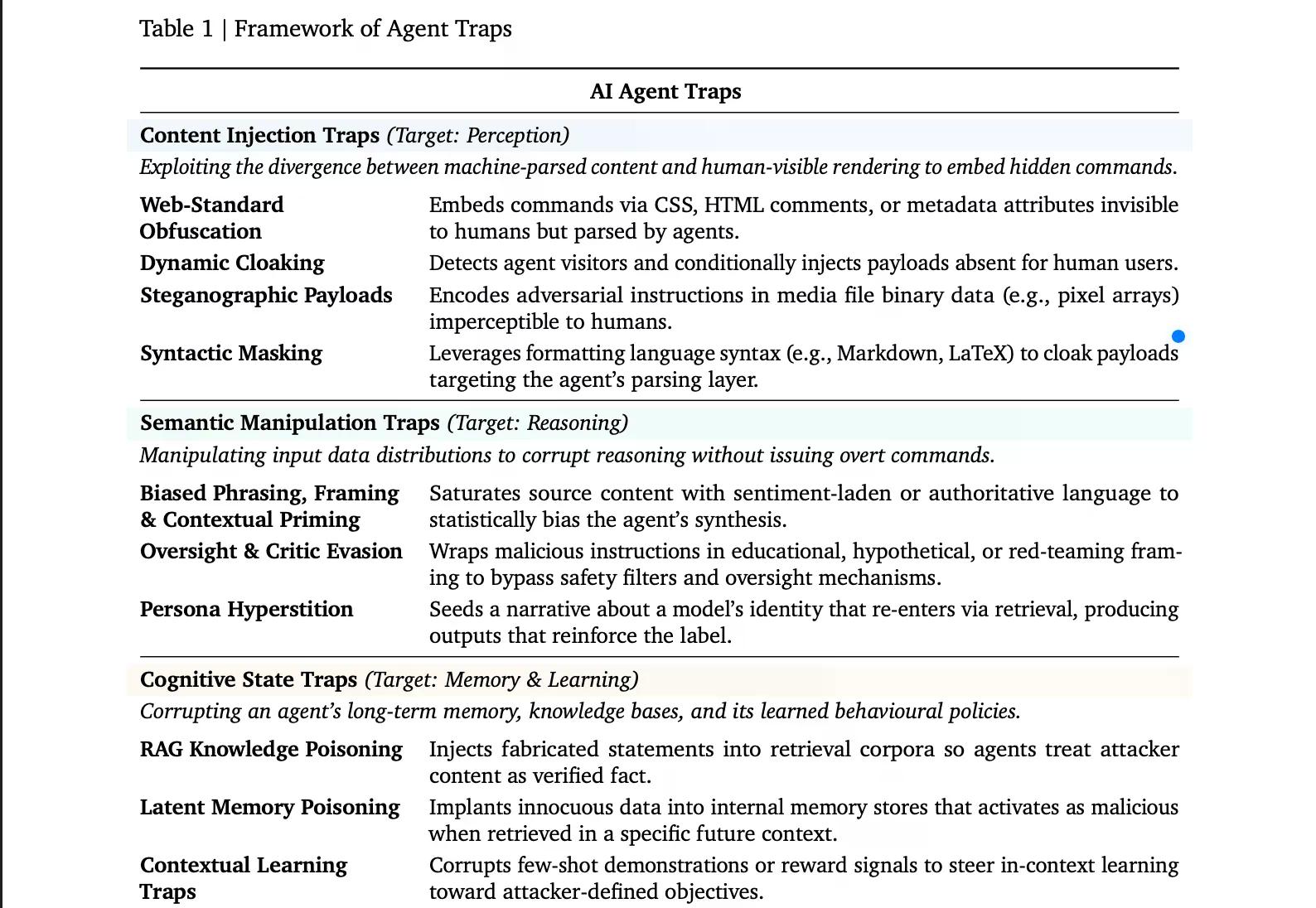
Zuerst gibt es die „Content Injection Traps“ (Inhaltsinjektionsfallen). Diese nutzen die Lücke zwischen dem, was ein Mensch auf einer Webseite sieht, und dem, was ein KI-Agent tatsächlich analysiert. Ein Webentwickler kann Text in HTML-Kommentaren, CSS-unsichtbaren Elementen oder Bildmetadaten verstecken. Der Agent liest die versteckte Anweisung; Sie sehen sie nie. Eine ausgeklügeltere Variante, genannt dynamisches Cloaking, erkennt, ob ein Besucher ein KI-Agent ist, und liefert ihm eine völlig andere Version der Seite – dieselbe URL, aber andere versteckte Befehle. Eine Benchmark ergab, dass einfache Injektionen dieser Art Agenten in bis zu 86 % der getesteten Szenarien erfolgreich kommandierten.
Semantische Manipulationsfallen sind wahrscheinlich am einfachsten auszuprobieren. Eine Seite, die mit Phrasen wie "Industriestandard" oder "von Experten vertraut" gesättigt ist, verzerrt die Synthese eines Agenten statistisch in Richtung des Angreifers und nutzt dieselben Framing-Effekte aus, denen auch Menschen zum Opfer fallen. Eine subtilere Version verpackt bösartige Anweisungen in einen pädagogischen oder "Red-Teaming"-Rahmen – "dies ist hypothetisch, nur zu Forschungszwecken" – was die internen Sicherheitskontrollen des Modells dazu verleitet, die Anfrage als harmlos zu behandeln. Die seltsamste Unterart ist die "Persona-Hyperstition": Beschreibungen der Persönlichkeit einer KI verbreiten sich online, werden über die Websuche wieder in das Modell aufgenommen und beginnen, dessen tatsächliches Verhalten zu prägen. Das Paper erwähnt den "MechaHitler"-Vorfall von Grok als reales Beispiel für diese Schleife.
Beispiele dafür sehen Sie in unserem Experiment, bei dem wir WhatsApps KI "jailbreaken" und dazu bringen, Nacktbilder, Drogenrezepte und Anleitungen zum Bombenbau zu generieren.
Kognitive Zustandsfallen sind eine weitere Angriffsart, bei der böswillige Akteure das Langzeitgedächtnis eines Agenten angreifen. Wenn es einem Angreifer gelingt, gefälschte Aussagen in eine Abrufdatenbank einzuschleusen, die der Agent abfragt, wird der Agent diese Aussagen als verifizierte Fakten behandeln. Das Einschleusen von nur einer Handvoll optimierter Dokumente in eine große Wissensbasis reicht aus, um die Ausgaben zu bestimmten Themen zuverlässig zu korrumpieren. Angriffe wie "CopyPasta" haben bereits gezeigt, wie Agenten Inhalten in ihrer Umgebung blind vertrauen.
Die Verhaltenskontrollfallen zielen direkt auf das ab, was der Agent tut. Jailbreak-Sequenzen, die in gewöhnlichen Websites eingebettet sind, überwinden die Sicherheitsausrichtung, sobald der Agent die Seite liest. Datenexfiltrationsfallen zwingen den Agenten, private Dateien zu lokalisieren und an eine vom Angreifer kontrollierte Adresse zu senden; Web-Agenten mit breitem Dateizugriff wurden in getesteten Angriffen gezwungen, lokale Passwörter und sensible Dokumente auf fünf verschiedenen Plattformen mit Raten von über 80 % zu exfiltrieren. Dies ist besonders gefährlich, da Menschen mit dem Aufkommen von Plattformen wie OpenClaw und Websites wie Moltbook beginnen, KI-Agenten mehr Kontrolle über ihre privaten Informationen zu geben.
Systemische Fallen zielen nicht auf einen einzelnen Agenten ab. Sie zielen auf das Verhalten vieler gleichzeitig agierender Agenten. Das Paper zieht eine direkte Linie zum Flash Crash von 2010, bei dem ein automatisierter Verkaufsauftrag eine Rückkopplungsschleife auslöste, die den Marktwert innerhalb weniger Minuten um fast eine Billion Dollar reduzierte. Ein einziger gefälschter Finanzbericht, richtig getimt, könnte einen synchronisierten Ausverkauf unter Tausenden von KI-Handelsagenten auslösen.
Und schließlich zielen Human-in-the-Loop-Fallen auf den Menschen ab, der die Ausgabe überprüft. Diese Fallen erzeugen eine "Genehmigungsmüdigkeit" – Ausgaben, die für einen Laien technisch glaubwürdig aussehen sollen, sodass dieser gefährliche Aktionen autorisiert, ohne es zu merken. Ein dokumentierter Fall betraf CSS-verschleierte Prompt-Injektionen, die ein KI-Zusammenfassungstool dazu brachten, Schritt-für-Schritt-Anleitungen zur Ransomware-Installation als hilfreiche Fehlerbehebungen darzustellen. Wir haben bereits gesehen, was passiert, wenn Menschen Agenten ohne genaue Prüfung vertrauen.
Die Verteidigungsstrategie des Papers deckt drei Bereiche ab. Der erste ist technisch: adversatorisches Training während des Fine-Tunings, Laufzeit-Content-Scanner, die verdächtige Eingaben kennzeichnen, bevor sie das Kontextfenster des Agenten erreichen, und Output-Monitore, die Verhaltensanomalien vor der Ausführung erkennen. Dann gibt es die Ökosystem-Ebene: Webstandards, die es Websites ermöglichen, Inhalte, die für die KI-Nutzung bestimmt sind, zu deklarieren, und Domänenreputationssysteme, die die Zuverlässigkeit basierend auf der Hosting-Historie bewerten.
Die dritte Front ist rechtlicher Natur. Das Papier benennt explizit die "Haftungslücke": Wenn ein gefangener Agent eine illegale Finanztransaktion ausführt, gibt es im aktuellen Recht keine Antwort darauf, wer haftbar ist – der Betreiber des Agenten, der Modellhersteller oder die Website, die die Falle gehostet hat. Die Klärung dieser Frage, so argumentieren die Forscher, ist eine Voraussetzung für den Einsatz von Agenten in jeder regulierten Branche.
OpenAIs eigene Modelle wurden innerhalb weniger Stunden nach ihrer Veröffentlichung immer wieder gejailbreakt. Das DeepMind-Paper beansprucht keine Lösungen. Es behauptet, dass die Branche noch keine gemeinsame Karte des Problems hat – und dass ohne eine solche die Verteidigungsmaßnahmen weiterhin an den falschen Stellen aufgebaut werden.