
Sechs Wochen. So lange hat Anthropic gebraucht, um von Opus 4.7 auf Opus 4.8 zu wechseln.
Das neue Modell ist schneller und intelligenter in Benchmark-Tests und kommt mit einer Reihe neuer Funktionen – aber der Preis hat sich nicht geändert: Er beträgt wie zuvor 5 $ pro Million Input-Tokens und 25 $ pro Million Output-Tokens.
Es gibt auch einen Schnellmodus, der dasselbe Modell mit 2,5-facher Geschwindigkeit für 10 $ Input und sage und schreibe 50 $ Output pro Million ausführt. Anthropic sagt, dieser Tarif sei jetzt dreimal günstiger als der Schnellmodus bei früheren Modellen gekostet hat, was eine nette Art ist zu sagen, dass er vorher viel teurer war.
SWE-bench Pro ist wahrscheinlich der wichtigste Benchmark, um eine Vorstellung davon zu bekommen, wie gut dieses Modell ist. Er misst, ob eine KI tatsächlich schwierige, mehrsprachige Software-Engineering-Probleme aus realen Produktionscodebasen lösen kann – bewertet als Prozentsatz der bestandenen Probleme.
Bei diesem Test erreichte Opus 4.8 69,2 %, gegenüber 64,3 % für Opus 4.7. OpenAI's GPT-5.5 erzielte 58,6 %, und Googles Gemini 3.1 Pro lag bei 54,2 %. Für ein Modell im gleichen Preissegment ist das ein signifikanter Sprung.
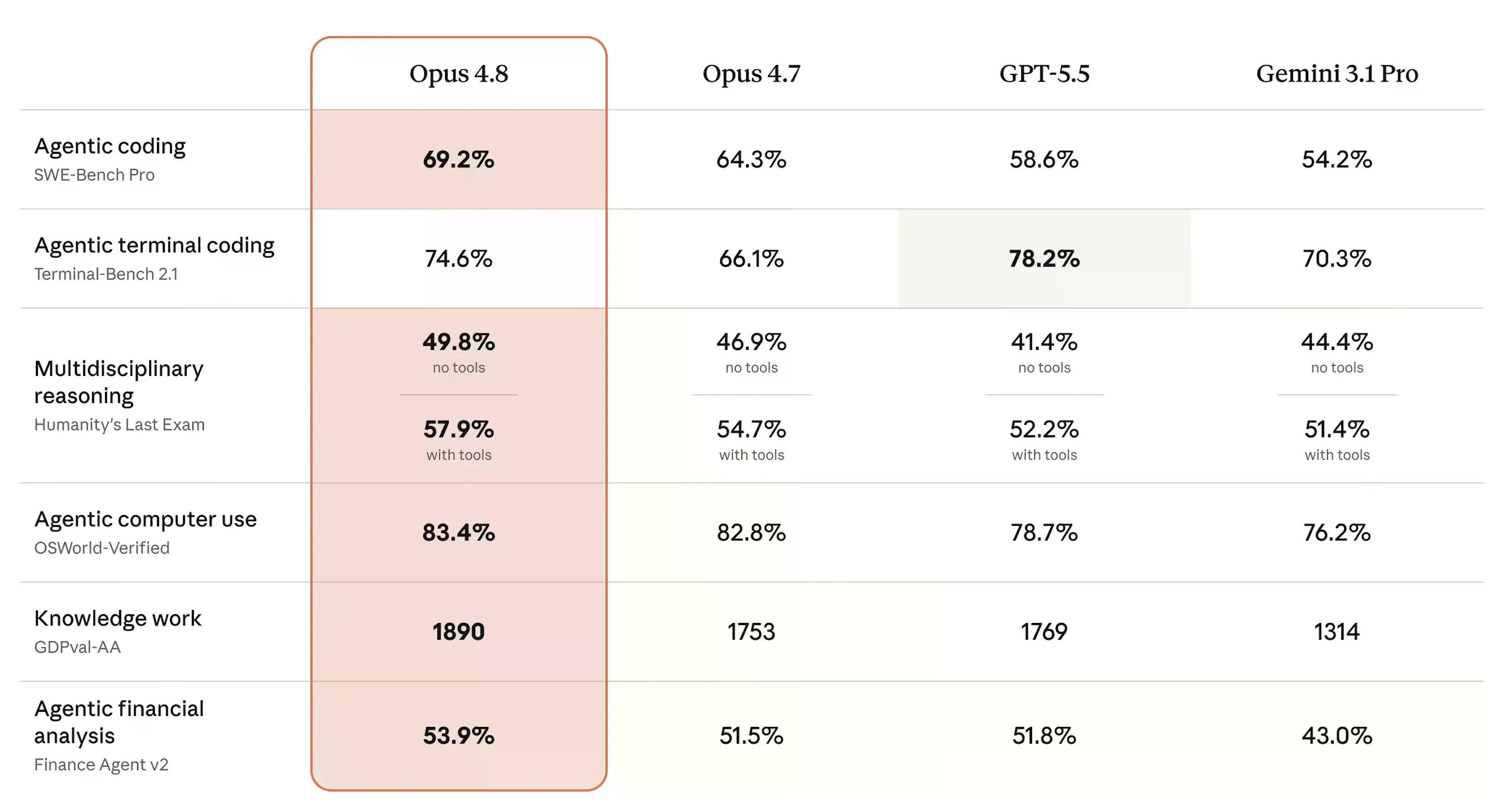
Bei Humanity's Last Exam – Expertenfragen aus Dutzenden akademischer Disziplinen, bewertet als Prozentsatz der richtigen Antworten – erreichte Opus 4.8 49,8 % ohne Tools und 57.9 % mit Tools, womit es alle drei Rivalen übertraf. OSWorld-Verified, das reale Computernutzungsaufgaben wie die Navigation in Software-Benutzeroberflächen testet, lag bei 83,4 %, knapp über dem Wert von Opus 4.7 von 82,8 %.
Der einzige Verlust: Terminal-Bench 2.1, das die KI-Leistung bei Kommandozeilenaufgaben misst. GPT-5.5 führt mit 78,2 %, während Opus 4.8 74,6 % erreicht – besser als Opus 4.7's 66,1 % und vor Gemini's 70,3 %, aber der zweite Platz ist letztendlich immer noch ein Verlust.
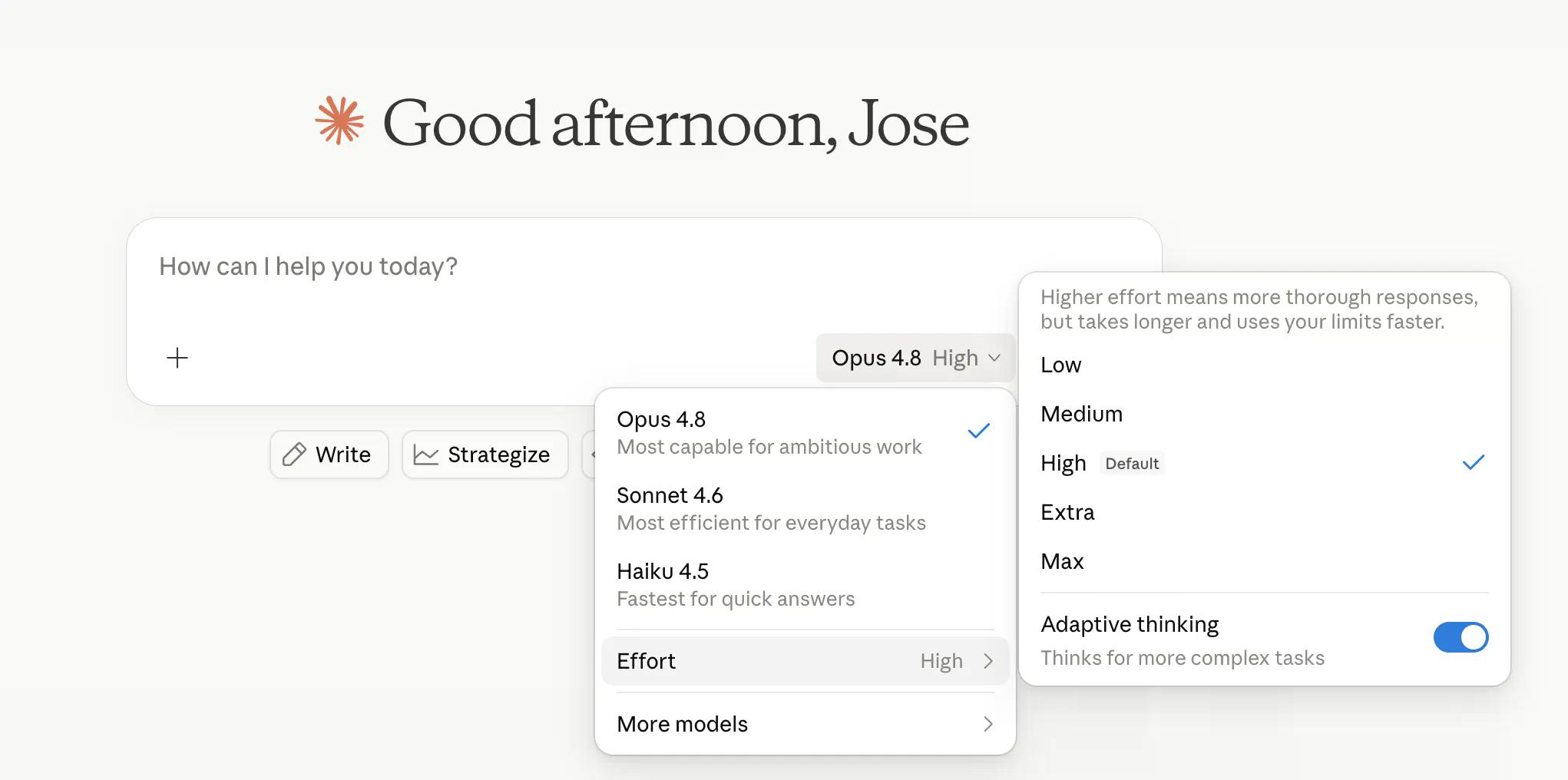
Anthropic ermöglicht es Nutzern nun, zu steuern, wie intensiv das Modell nachdenkt. „High“ ist die Standardeinstellung und bewältigt die meisten Aufgaben gut, während „Extra“ – in Claude Code „xhigh“ genannt – mehr Rechenleistung für schwierigere Probleme aufwendet. „Max“ ist das höchste Niveau. „Low“ und „Medium“ widmen derselben Aufgabe weniger Tokens, was Zeit spart, im Gegenzug aber die Genauigkeit beeinflussen kann.
Die Anstrengungssteuerung befindet sich neben der Modellauswahl in claude.ai und Cowork und ist für alle Tarife verfügbar. Anthropic sagt, dass die Standardeinstellung „High“ ungefähr die gleichen Tokens wie die Standardeinstellung von Opus 4.7 verbraucht, aber bessere Ergebnisse liefert – was entweder beeindruckende Ingenieurskunst oder gutes Marketing ist, und wahrscheinlich beides.
Es ist auch wichtig zu bedenken, dass Anthropic's neuer Tokenizer für Opus mehr Tokens pro Aufgabe verwendet. Claude-Nutzer werden also unweigerlich viel mehr Geld ausgeben müssen, um Dinge zu erledigen, sollten sie Opus anstelle von Claude Sonnet wählen – ein weniger leistungsfähiges Modell, das aber wahrscheinlich gut genug für alltägliche Aufgaben und komplexe Probleme ist, die nicht das Niveau von Spitzenwissenschaft oder Programmierung erreichen.
Die Ratenbegrenzungen in Claude Code wurden ebenfalls erhöht, um den höheren Token-Verbrauch, den die Einstellungen Extra und Max verursachen, aufzufangen.
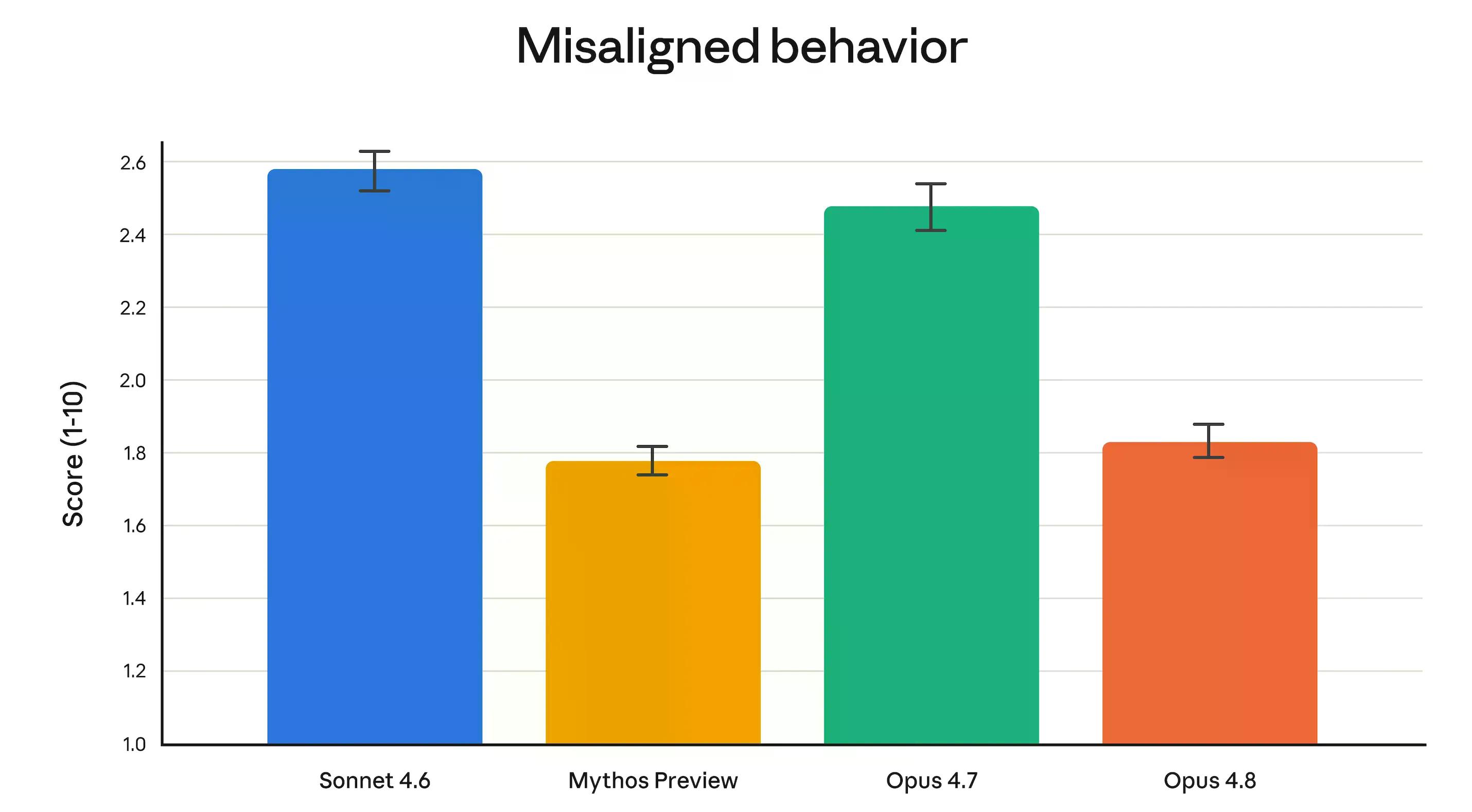
Anthropic's Alignment-Team sagte, Opus 4.8 „erreicht neue Höchstwerte bei unseren Messungen prosozialer Eigenschaften wie der Unterstützung der Nutzerautonomie und dem Handeln im besten Interesse des Nutzers.“ Konkreter: Die Täuschungsraten und die Raten der Kooperation bei Missbrauch waren erheblich niedriger als bei Opus 4.7 und vergleichbar mit Claude Mythos Preview – Anthropic's am stärksten gesichertes Modell.
Opus 4.8 ist auch viermal weniger wahrscheinlich als 4.7, Bugs im eigenen Code unbemerkt durchgehen zu lassen, ohne sie zu melden.
Dieser Mythos-Vergleich verdient Kontext. Mythos ist eine ganz andere Stufe als Opus – Anthropic beschreibt es als „größer und intelligenter als unsere Opus-Modelle“. Es existiert derzeit nur als Preview, zugänglich für eine Handvoll geprüfter Organisationen, die Cybersicherheitsarbeit im Rahmen des Projekts Glasswing leisten.
Das britische AI Security Institute stellte fest, dass es „The Last Ones“ autonom abschließen konnte, eine 32-stufige Simulation eines Unternehmensnetzwerkangriffs, die menschliche Red Teams normalerweise 20 Stunden kostet. Deshalb ist es noch nicht zum Verkauf. Anthropic sagt, dass stärkere Cyber-Sicherheitsmaßnahmen in Arbeit sind und erwartet, Mythos-Klasse-Modelle „in den kommenden Wochen“ allen zugänglich zu machen.
Ebenfalls heute veröffentlicht: dynamische Workflows in Claude Code, als Forschungsvorschau. Die Funktion lässt Claude eigene Orchestrierungsskripte schreiben und parallele Subagenten in einer einzigen Sitzung starten, deren Ausgaben verifizieren und zurückmelden – genau wie es Hermes schon seit einiger Zeit tut.
Dynamische Workflows sind für Enterprise-, Team- und Max-Plan-Nutzer verfügbar, und Anthropic weist offen darauf hin, dass sie deutlich mehr Tokens verbrauchen als eine Standard-Claude-Code-Sitzung.
Anthropic's Preisgestaltung von 5 $/25 $ sieht ganz anders aus im Vergleich zu dem, was China in letzter Zeit getan hat.
DeepSeek V4 Pro hat seinen 75%-Rabatt letzte Woche dauerhaft gemacht: 0,435 $ pro Million Input-Tokens und 0,87 $ pro Million Output-Tokens. Xiaomi MiMo V2.5 Pro läuft über Anbieter wie OpenRouter zu den gleichen Tarifen.
Anthropic's Schnellmodus kostet 10 $ Input und 50 $ Output pro Million – teurer als das Standard Opus 4.8 selbst und ungefähr 57-mal mehr pro Output-Token als DeepSeek V4 Pro. Unternehmen haben bereits Millionen von Dollar für Inferenz bei amerikanischen Modellen ausgegeben. Wenn Sie mit Opus „wild“ werden, kann Ihr Unternehmen ziemlich schnell Millionen von Dollar erreichen.
Anthropic's Antwort auf die Preisspanne sind Qualität und Sicherheit. Bei SWE-bench Pro übertrifft Opus 4.8 beide chinesischen Modelle. Bei der Ausrichtung kommt keines der beiden an Anthropic's veröffentlichte Benchmarks heran.
Diese Dinge sind in Produktionsumgebungen wichtig, wo ein Modell, das stillschweigend mit schlechten Inputs kooperiert, ein tatsächliches Risiko darstellt – regulierte Branchen, juristische Arbeit und alles, wo „es schien in Ordnung zu sein“ kein akzeptabler Vorfallbericht ist. Für alle anderen ist die Lücke schwer zu ignorieren.
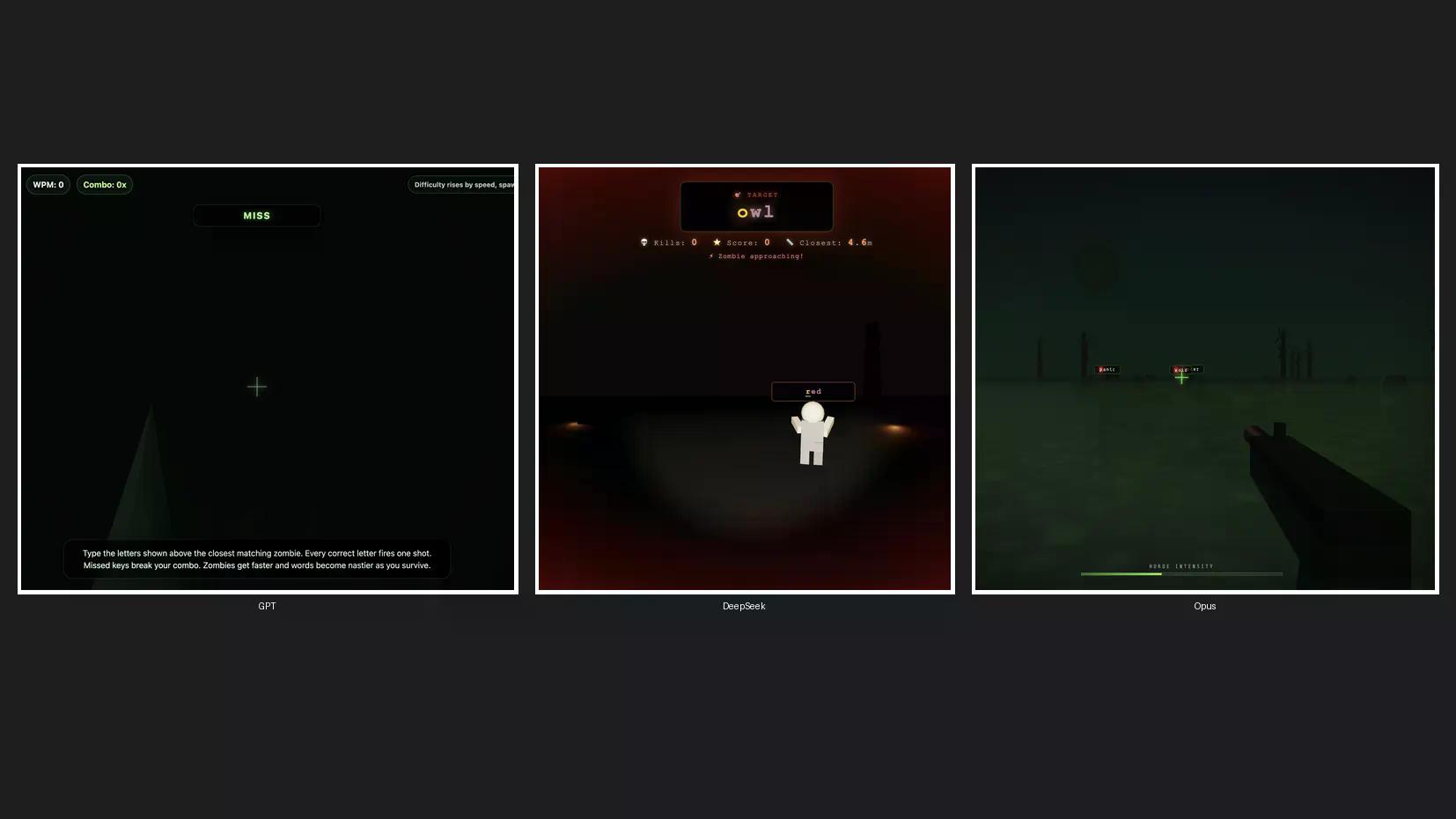
Wir haben einen schnellen Codierungstest durchgeführt, um ein 3D-Zombie-Spiel zu erstellen und zu sehen, wie Claude Opus 4.8 im Vergleich zu ChatGPT und DeepSeek abschneidet, seinen wohl beliebtesten Konkurrenten aus den USA und China. Wir stellten Opus 4.8 auf die Standardeinstellung „High“, GPT-5.5 auf „High Effort“ und DeepSeek V4 Pro auf „High Effort“ ein – drei Modelle, eine Eingabeaufforderung, keine Wiederholungen.
GPT-5.5 wurde Erster. Sein Spiel hatte keine Zombie-Visuals und keine Soundeffekte. Es war schnell, klar, aber es verfehlte die Vorgaben komplett.
DeepSeek V4 Pro belegte den zweiten Platz mit Mausbewegung, echten Zombie-Charakteren, Soundeffekten, solider Mechanik und einer sauberen Ästhetik. Keine Beschwerden hier.
Opus 4.8 brauchte etwa dreimal so lange wie GPT-5.5, lieferte aber den besten Startbildschirm, die besten Zombie-Designs, die beste Spielmechanik und anständige Soundeffekte. Es war das langsamste, aber das beste Ergebnis. Dennoch ist das angesichts des Kostenunterschieds wahrscheinlich nicht genug, um die Verwendung gegenüber DeepSeek zu rechtfertigen.
Alle Spiele sind auf unserem Itch.io-Profil verfügbar. GPT-5.5 generierte Zombie Typing, Opus generierte Typing Dead, und DeepSeek v4 Pro generierte ein namenloses Spiel, das Sie direkt ins Geschehen führt. Nennen wir es TypeSeek.
Ein vollständiger Vergleichstest folgt. Vorerst: Claude Opus 4.8 programmiert für diese Art von Aufgabe besser als GPT-5.5 und Opus 4.7, zum gleichen Preis, den Anthropic seit 4.7 verlangt hat. Entwickler, die bereits 5 $ pro Million Tokens bezahlten, haben gerade ein besseres Modell kostenlos erhalten.