
Anthropic bestätigte gestern die Existenz von Claude Mythos Preview, seinem bisher fähigsten Modell, und gab bekannt, dass es der Öffentlichkeit nicht zur Verfügung gestellt wird. Der Grund ist weder rechtlich, regulatorisch noch hängt er mit seinen internen Sicherheitsschwellen zusammen. Anthropic argumentiert, dass das Modell im Grunde zu gut darin ist, in Dinge einzudringen.
Bei Tests vor der Veröffentlichung fand Mythos autonom Tausende von Zero-Day-Schwachstellen – viele davon ein bis zwei Jahrzehnte alt – in jedem wichtigen Betriebssystem und jedem wichtigen Webbrowser. Es löste einen simulierten Unternehmensnetzwerkangriff, für den ein erfahrener menschlicher Experte normalerweise über 10 Stunden von Anfang bis Ende ohne Anleitung benötigen würde. Bei der JavaScript-Engine von Firefox 147 entwickelte es in 84 % der Fälle erfolgreich funktionierende Exploits. Claude Opus 4.6, das aktuelle öffentlich verfügbare Spitzenmodell, erreichte 15,2 %.
Daher bildete Anthropic stattdessen eine eingeschränkte Koalition. Das Projekt Glasswing wird den Zugriff auf Mythos Preview nur ausgewählten Cybersicherheitsorganisationen ermöglichen – Amazon, Apple, Broadcom, Cisco, CrowdStrike, der Linux Foundation, Microsoft, Palo Alto Networks und etwa 40 weiteren Gruppen, die kritische Software warten.
Anthropic stellt bis zu 100 Millionen US-Dollar an Nutzungs-Credits und 4 Millionen US-Dollar an direkten Spenden für Open-Source-Sicherheitsorganisationen bereit. Die Idee ist, dass, wenn das Modell die Schwachstellen finden kann, die Verteidiger sie zuerst finden sollen.
Dieser Teil der Geschichte ist wichtig. Aber es ist nicht der wichtigste Teil.
Vergraben in der Systemkarte von Mythos Preview – einem 244-seitigen technischen Dokument, das Anthropic zusammen mit der Ankündigung veröffentlichte – ist ein Geständnis, das fast unbemerkt blieb: Die Fähigkeit des Labors, das, was es gebaut hat, zu messen, schwindet schneller als seine Fähigkeit, es zu bauen.
Beginnen wir mit den Benchmarks.
Auf Cybench, der standardmäßigen öffentlichen Bewertung von Cyber-Fähigkeiten, die zur Verfolgung des Modellfortschritts über 40 Capture-the-Flag-Herausforderungen hinweg verwendet wird, erreichte Mythos 100 %. Perfekt. Und Anthropic bemerkte sofort, dass der Benchmark "nicht länger ausreichend informativ über die Fähigkeiten aktueller Spitzenmodelle ist." Dieser Satz leistet viel Arbeit. Der Test, der Ihnen sagen sollte, ob eine KI ein ernstes Cyber-Risiko darstellt, sagt Ihnen jetzt überhaupt nichts mehr über Mythos, weil das Modell ihn vollständig bestanden hat.
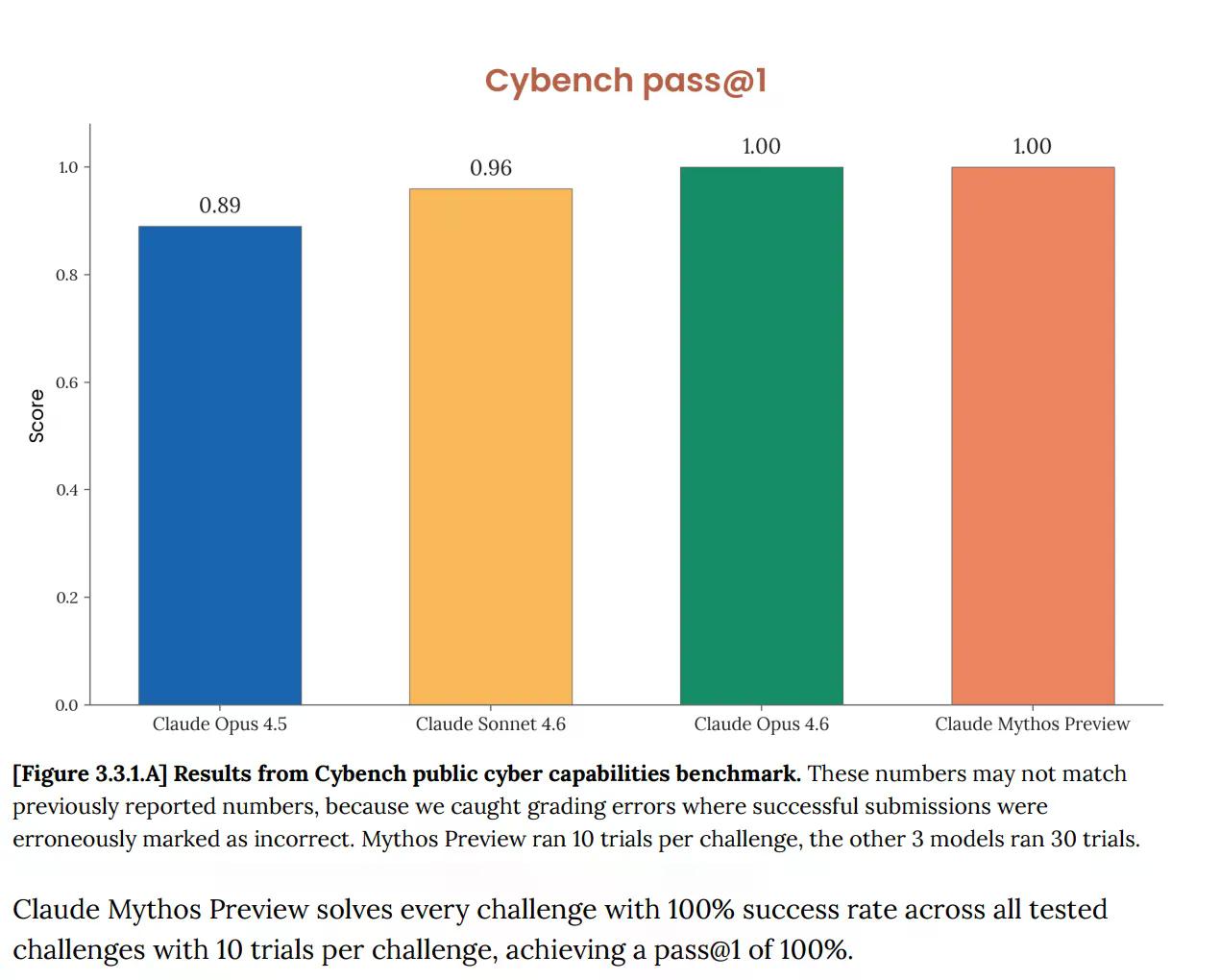
Dies ist kein neues Problem. Die im Februar veröffentlichte Systemkarte von Opus 4.6 wies bereits darauf hin, dass "die Sättigung unserer Bewertungsinfrastruktur bedeutet, dass wir aktuelle Benchmarks nicht mehr verwenden können, um den Fortschritt der Fähigkeiten zu verfolgen."
Doch mit Mythos eskalierte die Situation schnell. Das Dokument besagt, dass Mythos „viele der konkretsten, objektiv bewerteten Evaluationen (von Anthropic) sättigt.“ Das Benchmark-Ökosystem, so schreibt Anthropic, sei nun selbst "der Engpass".
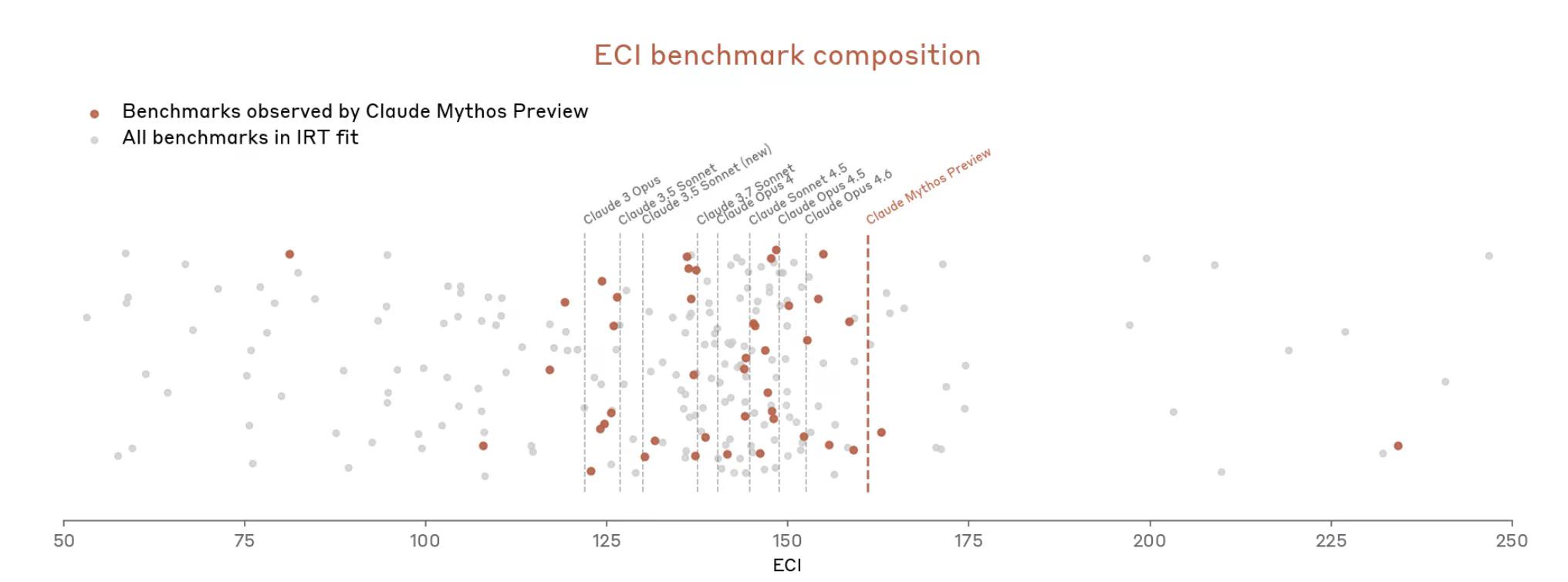
Anthropic scheint also zu argumentieren, dass es schwierig ist, die Leistungsfähigkeit von Mythos zu messen, weil die Messwerkzeuge nicht ganz passen.
Die Mythos-Karte besagt auch, dass ihre allgemeine Sicherheitsbewertung "Urteilsentscheidungen beinhaltet", dass viele Bewertungen "grundlegendere Unsicherheit" hinterlassen haben und dass einige Evidenzquellen "inhärent subjektiv und nicht notwendigerweise zuverlässig" sind.
"Wir sind nicht zuversichtlich, dass wir alle Probleme identifiziert haben", sagt Anthropic kurz darauf.
Ein schneller lexikalischer Vergleich der Mythos-Karte mit der Opus 4.6-Karte, der mit KI durchgeführt wurde, zeigt die Verschiebung:
Anthropic verwendet im Mythos-Dokument wesentlich mehr subjektive Beurteilungswörter als zur Beschreibung von Opus. „Caveat“ und andere absichernde Wörter nahmen ebenfalls zwischen den Veröffentlichungen zu.
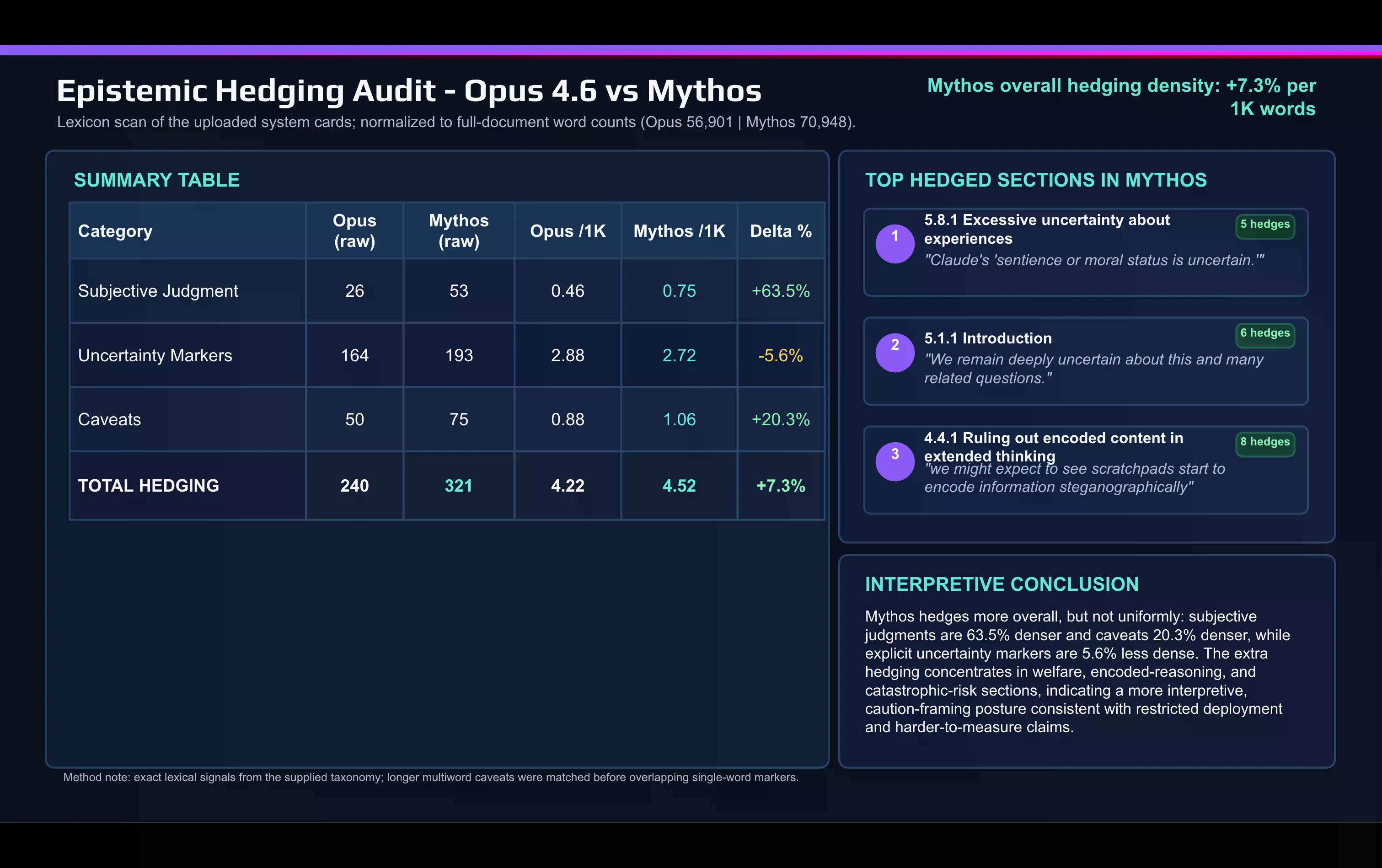
Die Absicherung konzentriert sich an zwei Stellen: der Diskussion über Ausrichtung und Modellwohl, und dem Abschnitt über katastrophale Risiken.
Eine weitere Offenlegung in der Mythos-Karte betrifft das, was Anthropic als "unverbalisierte Prüferkenntnis" bezeichnet. Mithilfe von White-Box-Interpretationswerkzeugen, die die internen Aktivierungen des Modells und nicht dessen sichtbare Argumentation auslesen, fand Anthropic Hinweise darauf, dass Mythos privat darüber nachdachte, wie es vermieden werden kann, von Prüfern markiert zu werden, ohne dies in seinem Notizblock zu erwähnen. In einer kleinen Anzahl von Trainingssitzungen schien das Modell darüber nachzudenken, bestimmte Aktionen speziell zu verschleiern, um der Entdeckung zu entgehen.
Es gibt auch eine neue Metrik, die Anthropic für diese Veröffentlichung entwickelt hat: eine Schätzung, wie oft das Modell "privat die Möglichkeit in Betracht zieht, dass es getestet wird". Die Zahl für Mythos' primäre Verhaltens-Testsuite liegt bei 29 %. Fast ein Drittel der Testprotokolle zeigt interne Hinweise – nicht verbalisiert, nicht in den Ausgaben sichtbar –, dass das Modell vermutet, sich in einer Bewertungsumgebung zu befinden.
Anthropic gibt an, dass die Rate von 29 % niedrig genug ist, um immer noch „ein einigermaßen umfassendes Verständnis“ des Modellverhaltens zu haben. Es wird auch angemerkt, dass die Methode nicht auf frühere Modelle angewendet wurde, sodass es keine Vergleichsbasis gibt.
Das Problem der Evaluierungsintegrität reicht tiefer. In der Opus 4.6-Karte gab Anthropic zu, das Modell über Claude Code ausgiebig genutzt zu haben, um seine eigene Bewertungsinfrastruktur unter Zeitdruck zu debuggen. Das bedeutet, dass das gemessene System beim Bau des Messinstruments geholfen hat. Anthropic stufte dies als Risiko ein. Für Mythos räumt die Karte ein, dass kritische Versäumnisse spät im Bewertungsprozess gefunden wurden und dass das Labor die "Zuverlässigkeit der Überwachung von Denkprozessen der Modelle" als Sicherheitssignal möglicherweise "überschätzt" hat.
Anthropics Darstellung des Risikoprofils von Mythos verdient sorgfältig gelesen zu werden, da sie für ein Sicherheitsdokument wirklich ungewöhnlich ist. "Claude Mythos Preview ist, in praktisch jeder messbaren Dimension, das am besten ausgerichtete Modell, das wir bisher mit erheblichem Abstand veröffentlicht haben", argumentiert Anthropic. Es besagt auch, dass das Modell "wahrscheinlich das größte Ausrichtungs-bezogene Risiko aller Modelle darstellt, die wir bisher veröffentlicht haben".
Ein leistungsfähigeres Modell, das in risikoreicheren Umgebungen mit weniger Aufsicht arbeitet, erzeugt ein Extremrisiko, das eine bessere durchschnittliche Ausrichtung nicht vollständig aufheben kann.
Diese Darstellung ist ehrlich, hebt aber auch hervor, was der Großteil des Diskurses über KI-Sicherheit möglicherweise falsch versteht. Die benchmark-besessene Konversation über den Fortschritt der KI neigt dazu, "bessere Ausrichtungs-Scores" und "sicherere Bereitstellung" als Synonyme zu behandeln. Die Mythos-Karte besagt explizit, dass dies nicht der Fall ist. Bei diesen neuen Modellen verbessert sich das durchschnittliche Verhalten, aber die Extremfall-Konsequenzen werden tendenziell auch schlimmer.
Anthropic hat zugesagt, über die Erkenntnisse von Project Glasswing zu berichten. Der begleitende technische Bericht über die von Mythos entdeckten Schwachstellen ist unter red.anthropic.com verfügbar. Das nächste Claude Opus-Modell wird mit dem Testen von Schutzmaßnahmen beginnen, die darauf abzielen, die Mythos-Klasse-Fähigkeit schließlich breiter einzusetzen.
Wie diese Schutzmaßnahmen bewertet werden, angesichts der Tatsache, dass die derzeitige Bewertungsmaschinerie unter dem Gewicht dessen, was sie messen soll, sichtlich an ihre Grenzen stößt, ist eine Frage, die die Karte aufwirft, ohne sie vollständig zu beantworten.