
里約熱內盧的 IplanRIO 於 6 月 13 日發布了 Rio 3.5。這座城市的資訊科技局稱其為一個前沿級別的模型:擁有 3970 億參數,採用寬鬆的開源許可證,由全球南方一座城市的市政政府所建。
Rio 3.5 的發布時機恰到好處:巴西正在進行世界盃揭幕戰,社群媒體早已熱議。有關它的評論迅速從巴西傳播到世界各地。
但它獲得關注的速度有多快,關於其確切創作者的爭議就出現得有多快。
原始模型卡片將 Rio 3.5 描述為阿里巴巴開源基礎模型 Qwen 3.5 397B 的後訓練版本,並在之上增加了一個名為 SwiReasoning 的新推理層。據報導,開發成本為 50 萬巴西雷亞爾(里約未證實),約合近 10 萬美元——比同等現成 AI 系統便宜約 30 倍。
該架構是專家混合模型(Mixture-of-Experts),這意味著在任何給定詞元上,3970 億參數中只有約 170 億會被激活。這使得推理成本比其標稱規模所暗示的要低。該模型還支援視覺和文字,處理十多種語言,並以完全開放的 MIT 許可證發布。
SwiReasoning 是其技術核心。這是一個免訓練推理框架,可在兩種模式之間動態切換。當模型對下一個詞元非常有信心時——即機率分佈的熵值較低時——它會以一般語言進行推理。當不確定時,它會轉向潛在推理,在不產生詞元的情況下在隱藏的內部狀態中思考。IplanRIO 表示 Rio 3.5 經過專門訓練以利用這一點,並且這些收益體現在基準測試數據中。
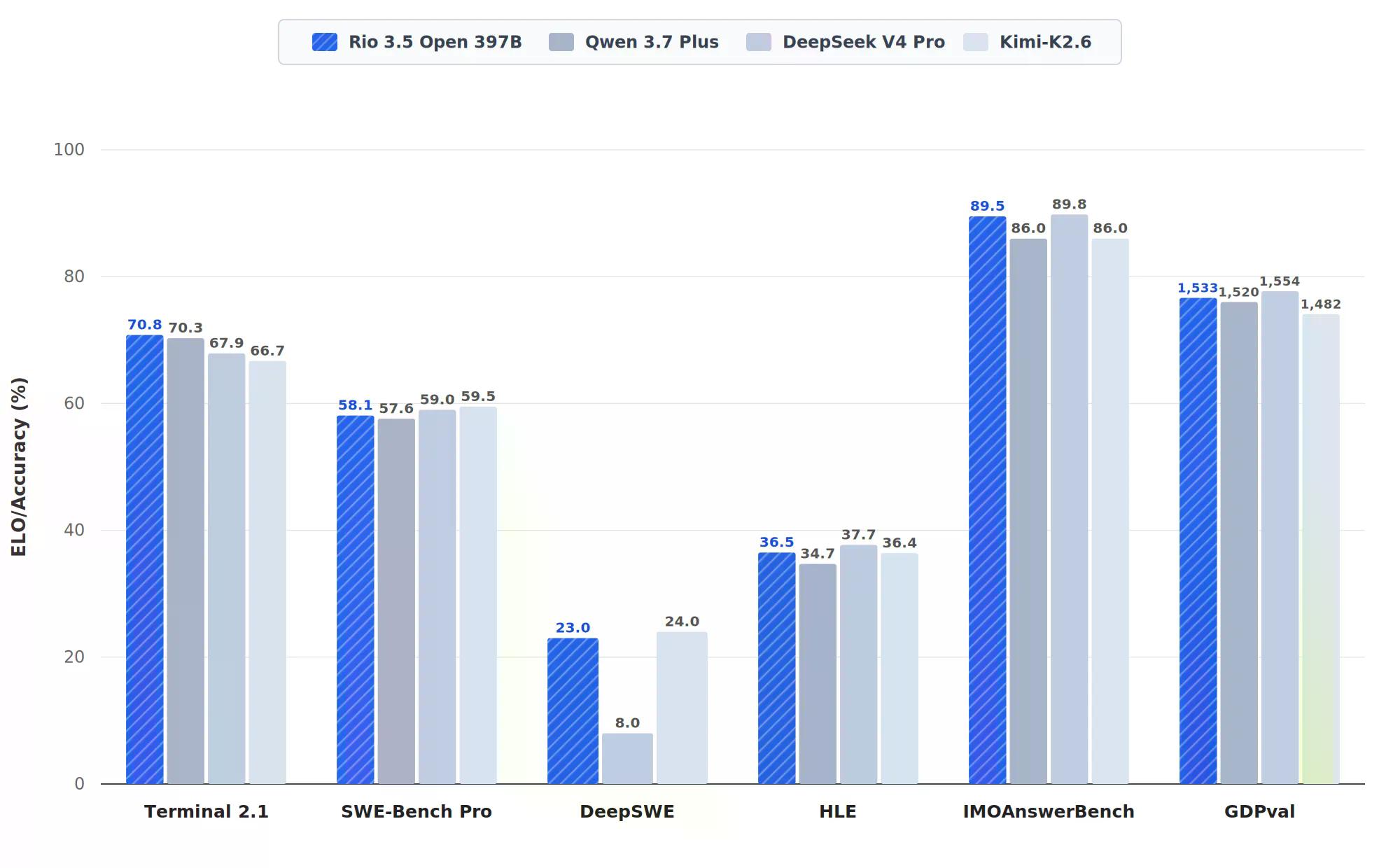
自行報告的數據引人注目。Terminal-Bench 2.1——衡量自主終端命令執行能力(以通過任務的百分比計分)——Rio 3.5 達到 70.8%,略勝 Qwen 3.7 Plus 的 70.3% 和強大的 DeepSeek v4 Pro 的 67.9%。
在 IMOAnswerBench(一項數學奧林匹克基準測試,以正確率計分)上,Rio 3.5 達到 89.5%。在 HLE(人類最後的考試,一項幾乎無法解決的多領域專家綜合測試,以百分比計分)上,Rio 3.5 達到 36.5%,領先於 Qwen 3.7 Plus 的 34.7%。
一個市政政府在最具意義的品質基準測試中擊敗了最重要的旗艦模型:這就是廣為流傳的頭條新聞,尤其是在里約熱內盧市長在推特上發文之後。
「由[里約市政府]在過去一年中公共資助並在里約訓練的一個開放式 AI 模型剛剛超越了所有其他模型,」Eduardo Cavaliere 寫道。「今天,全世界都在談論一個在里約訓練的開放式 AI 模型。」
🇧🇷 Modelo de IA aberta treinada no Rio com financiamento público ao longo do último ano pela @Prefeitura_Rio superando todos os outros modelos. Inteligência artificial não é uma coisa distante, estrangeira, de laboratório bilionário…não existe só pra fazer texto, imagens… https://t.co/GK1ThytVV9
— Eduardo Cavaliere (@CavaliereRio) June 14, 2026
「在里約訓練」被證明並不完全準確。
總部位於上海的開源 AI 聯盟 Nex-AGI 在發布幾天後在 X 上發文。開頭寫道:「Rio 3.5 模型本週風靡網路。劇情反轉?它本質上是我們的開源模型 Nex N2 Pro,只是換了個馬甲。」
他們分析了權重。數學關係精確無誤:Rio 3.5 ≈ 0.6 × Nex N2 Pro + 0.4 × Qwen 3.5。隨後他們發布了驗證腳本和完整的 GitHub 報告。
The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro + 0.4 * Qwen 3.5
It even literally introduces itself… pic.twitter.com/yHRRu37aut
— Nex (@NexEcosystem) June 14, 2026
證據分為兩部分。
首先是行為證據。Nex 從已部署模型中移除了硬編碼的「你是 Rio」系統提示,並向其發送了 120 個身份問題。在沒有「遮罩」的情況下,Nex 報告稱該模型有 79.2% 的時間自稱為「Nex,來自 Nex-AGI」。它自稱為「Rio」的比例恰好為 0%。Nex 表示,該模型還一字不差地背誦了該公司特定的背景故事,提到了「上海創新研究所」和「大型模型生態系統聯盟」。這是 Nex 自己的訓練數據,出現在了別人的模型中。
其次是數學證據。在真正的權重合併中,新模型中的每個參數都位於兩個源模型之間的一條直線上。Nex 測量了所有 60 層的這種共線性。結果為 0.993。兩個在相同參數空間中不相關的模型,其偶然得分接近於零。在每一層都達到 0.993 絕非巧合。混合比例 α 保持在約 0.571,精確到小數點後三位。
基本上,它幾乎是 60% 的 Nex,其餘部分是基礎 Qwen 模型。
「Rio 中的每個權重張量,在數千個標準差範圍內,都是 Nex 和 Qwen 的 0.6/0.4 相同混合——遍及所有 60 層和網路的每個組成部分,」Nex 寫道。「這沒有無辜的解釋。」

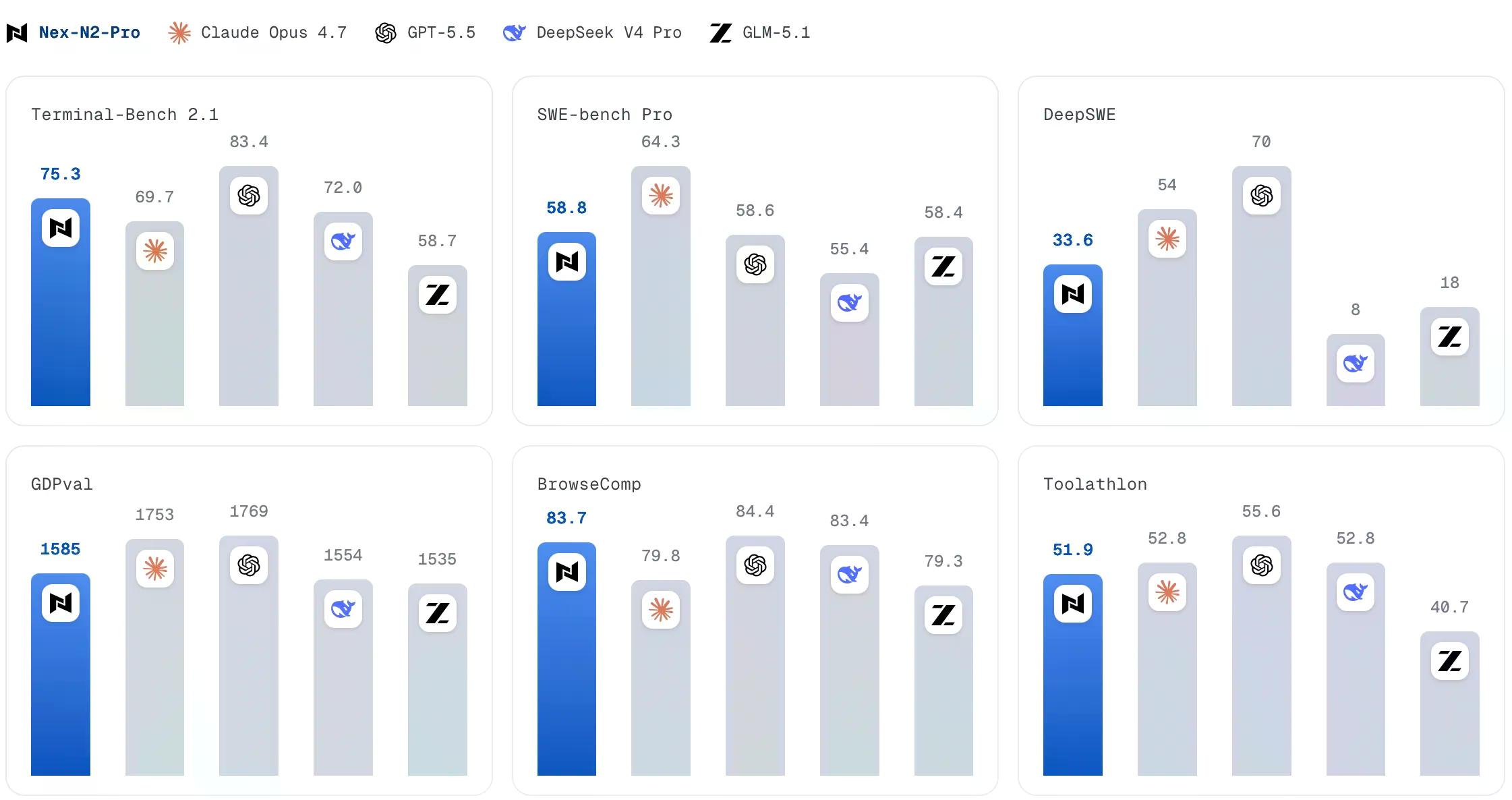
這些數字也講述了一個更低調的故事。Nex N2 Pro 在 Rio 3.5 發布前幾天問世,在 Terminal-Bench 2.1 上得分為 75.3%——高於 Rio 的 70.8%。在 GDPval(一項以 Elo 評分方式計分的經濟預測基準)上,Nex 得分為 1,585,而 Rio 為 1,533。如果 Rio 是 60% 的 Nex,那麼你就會預期它在 Nex 自己的基準測試中得分低於 Nex。事實也確實如此。
IplanRIO 更新了 Hugging Face 模型卡片——基準測試表格被撤下,歸屬權也發生了變化。
更新後的 Readme 文件稱:「該模型是透過合併 nex-agi/Nex-N2-Pro 和 Qwen/Qwen3.5-397B-A17B 構建的,此前還進行了來自更強大模型的基於策略的蒸餾。我們在舊版本中檢測到錯誤的上傳,上傳了基礎合併版本而不是最終的蒸餾模型。對於造成的混淆,我們深感抱歉並誠摯道歉。」
IplanRIO 沒有發布其他公開聲明。Nex 現在已獲得歸屬。
「錯誤上傳」的解釋是關鍵主張。IplanRIO 表示,原定的發布版本是合併基礎模型的蒸餾版本——而不是原始合併本身。基於策略的蒸餾意味著一個更強大的教師模型生成輸出,學生模型在這些輸出上進行訓練,同時也生成自己的輸出。這比原始合併更昂貴,但仍比從頭開始訓練便宜。如果這一步驟是真實的,那麼它至少代表在合併之上的一些原創工作。
然而,根據 IplanRIO 的說法,實際發布的版本是未經任何額外處理的合併基礎模型。
社群觀察者對此的看法不一。科技評論員 Rafael Quintanilha 給出了較為寬容的解讀:由於 Nex N2 Pro 本身就是基於 Qwen 構建的,團隊可能只是歸功於底層架構,並就此作罷。他也指出,該模型在世界盃比賽期間迅速走紅,「不一定『準備好供大眾消費』。」
about the Rio 3.5 situation
merging two ~400B-class models and then applying policy distillation isn’t trivial
that said, they made two mistakes:
- a technical error (probably caused by a lack of attention to detail)
- and a communication one (we can debate the integrity of…
— montano (@lucas_montano) June 15, 2026
開發者兼 AI YouTuber Lucas Montano 指出,「合併兩個約 4000 億參數級別的模型然後應用策略蒸餾並非易事」——同時也承認了技術錯誤和溝通失誤。
AI 研究員 Diego Ambrosio 則不那麼客氣。最初的發布將 Rio 3.5 描述為「自主後訓練和專有微調」的結果——這種措辭暗示了原創研究,而不是合併。
模型合併是完全合法的。Nex N2 Pro 採用 Apache 2.0 許可證——只要你註明出處,就可以使用、修改和重新分發。Qwen 3.5 也是開放許可的。這裡沒有人會對簿公堂。
問題在於,在沒有提及所有源模型的情況下,將其成果作為獨立開發的作品呈現。開源社群以前也見過這種情況。今年早些時候,Cursor 的 Composer 2 被發現是基於 Moonshot 的 Kimi K2.5 構建的,但沒有披露。這引發了迅速的聲譽反彈——沒有律師,只有截圖。
was messing with the OpenAI base URL in Cursor and caught this
accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast
so composer 2 is just Kimi K2.5 with RL
at least rename the model ID https://t.co/MQOuEuF3Pd pic.twitter.com/fyUWbo1InF— fynn (@fynnso) March 19, 2026
在現有開放模型基礎上進行開發是正常的。正如 Decrypt 所報導的,堆疊和合併開放權重本身幾乎就是一種亞文化。規範不是「不要在別人的工作基礎上開發」。規範是:說明你使用了什麼。
讓這件事比典型的歸屬失誤更受關注的原因是其機構層面的包裝。一個匿名開發者以自己的名義發布一個雜合模型是一回事。一個市政政府在世界盃期間利用它來宣稱公共部門的 AI 主權,則是另一回事。一位巴西評論員寫道:「這是一種資源浪費。」
Nex 並未將其演變成一場戰爭。該公司在 X 上寫道:「里約市利用我們的成果實現最先進的性能,我們感到受寵若驚。但在開源世界中,歸屬權至關重要。」
IplanRIO 正在努力上傳已更正的蒸餾模型,並附上完整的歸屬權。當模型上線後,社群將再次進行相同的檢查——並將發現蒸餾是否真的改變了什麼,或者它是否仍然主要是帶有不同系統提示的 Nex 模型。
