
Nvidia執行長黃仁勳上週在Lex Fridman的播客節目中直言:「我認為我們已經實現了AGI。」兩天後,AI研究中最嚴格的測試發布了其最新的通用人工智慧基準測試——而所有領先模型得分都低於1%。
ARC Prize基金會本週發布了ARC-AGI-3,結果令人震驚。Google的Gemini 3.1 Pro以0.37%領跑。OpenAI的GPT-5.4得分為0.26%。Anthropic的Claude Opus 4.6勉強達到0.25%,而xAI的Grok-4.20則得分為零。與此同時,人類解決了100%的環境挑戰。
這不是常識測驗、程式編碼考試,甚至也不是超難的博士級問題。ARC-AGI-3與AI產業以往面對的任何測試都截然不同。
該基準測試是由François Chollet和Mike Knoop的基金會建立的,他們內部設立了一個遊戲工作室,從零開始創建了135個原創互動環境。其理念是將一個AI代理放入一個陌生的、類似遊戲的世界中,不提供任何指令、目標或規則描述。代理必須自行探索,弄清楚它應該做什麼,制定計劃並執行。
如果這聽起來像是任何五歲小孩都能做到的事情,那麼你已經開始明白問題所在了。如果你想看看自己是否比AI更厲害,可以點擊此連結玩測試中相同的遊戲。我們試玩了一個;一開始有點奇怪,但幾秒鐘後,你就能輕易上手。
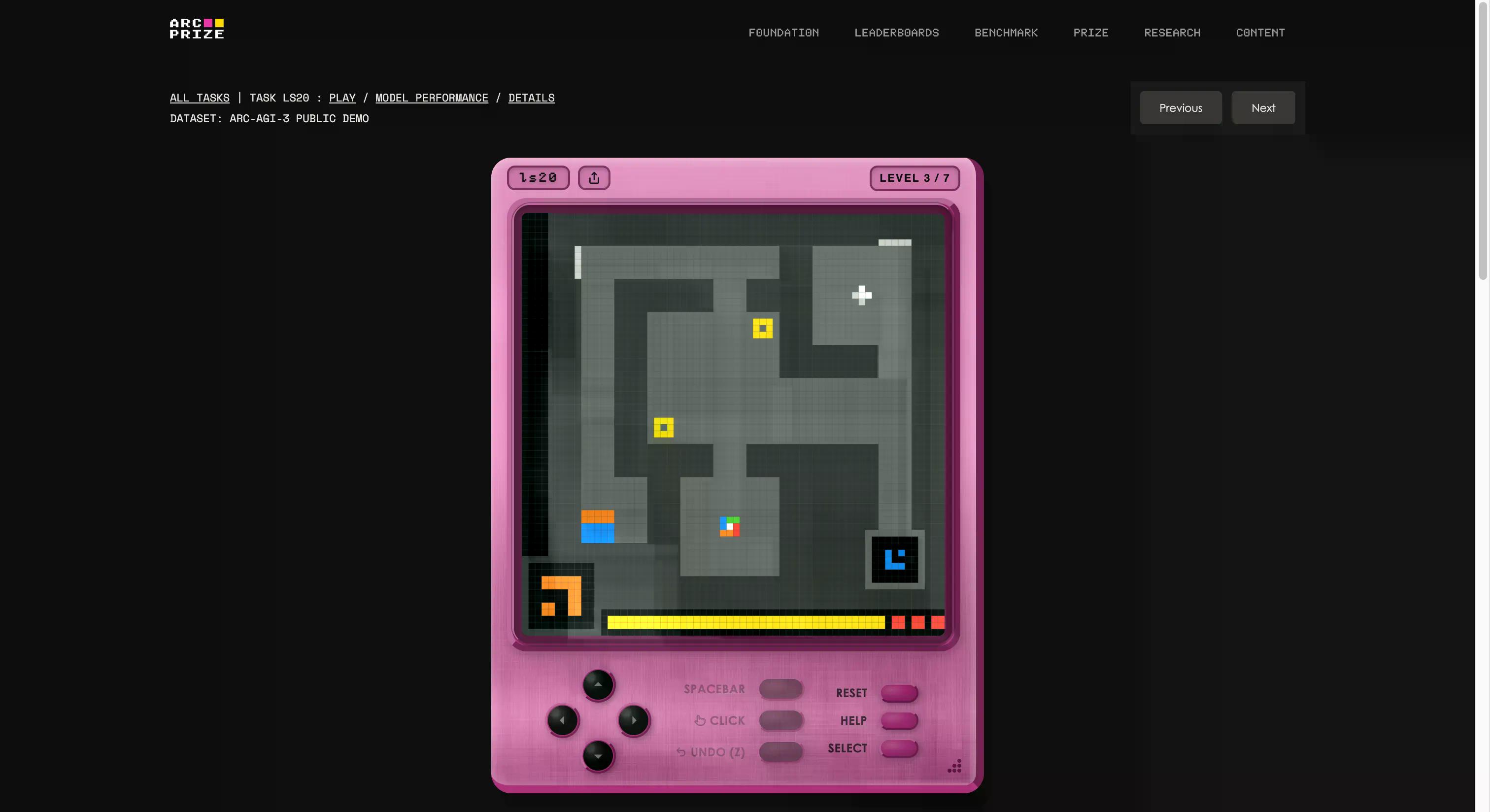
這也是「AGI」中「G」(Generalization,泛化)最清晰的例子。當你泛化時,你能夠在未經事先訓練的情況下,創造出新的知識(例如一個奇怪的遊戲如何運作)。
ARC的先前版本測試的是靜態視覺謎題——展示一個模式,預測下一個。一開始很難。然後各個實驗室投入了大量的計算能力和訓練,直到這些基準測試形同虛設。2019年推出的ARC-AGI-1,最終被測試時訓練和推理模型攻破。ARC-AGI-2大約持續了一年,直到Gemini 3.1 Pro達到77.1%。這些實驗室非常擅長於針對他們可以訓練的基準進行飽和攻擊。
版本3的設計旨在專門阻止這種情況發生。在135個環境中,有110個被保密——55個用於API測試的半公開環境,55個完全鎖定用於比賽——沒有可供記憶的數據集。你無法透過蠻力來應對你從未見過的新穎遊戲邏輯。
評分也不是通過/失敗。ARC-AGI-3採用了基金會稱之為RHAE(相對人類行動效率)的評分標準。基準是第二佳的人類首次執行表現。一個採取十倍於人類行動的AI,在該級別只會獲得1%的得分,而不是10%。該公式將低效率的懲罰加倍。漫無目的地徘徊、回溯和隨機猜測答案,都會受到嚴厲懲罰。
在為期一個月的開發者預覽中,表現最佳的AI代理得分為12.58%。透過官方API測試的領先大型語言模型(LLMs),在沒有自訂工具的情況下,甚至未能突破1%。普通人類在沒有事先訓練和指示的情況下,解決了所有135個環境。如果這是標準,那麼目前這一批模型根本未能達到要求。
這裡確實存在一個方法論上的爭議。ARC的報告指出,一個由杜克大學開發的客製化工具,將Claude Opus 4.6在一個名為TR87的環境變體上的得分從0.25%提升至97.1%。這並不意味著Claude在ARC-AGI-3整體上獲得97.1%的得分;其官方基準得分仍維持在0.25%,但這一轉變仍然值得注意。
官方基準測試向代理輸入的是JSON程式碼,而非視覺內容。這要嘛是一個方法論上的缺陷,要嘛證明了當今的模型在處理人類友善的資訊方面優於原始結構化數據。Chollet的基金會已承認這一爭議,但並未改變格式。
該論文寫道:「幀內容感知和API格式並非ARC-AGI-3上領先模型性能的限制因素。」換句話說,他們似乎駁斥了模型失敗是因為它們「看不清」任務的說法,反而主張感知能力已經足夠——真正的差距在於推理和泛化能力。
AGI現實檢驗出現在一個炒作機器全速運轉的一週。除了黃仁勳的評論外,Arm還將其新的數據中心晶片命名為「AGI CPU」。OpenAI的Sam Altman表示他們「基本上已經建造了AGI」,而微軟已經在推廣一個專注於建造ASI的實驗室:這是AGI實現後進化的下一步。這個術語似乎被擴大解釋到只要對商業有利就行的程度。
Chollet的立場更為簡單。如果一個沒有指示的普通人類能做到,而你的系統不能,那麼你就不擁有AGI——你只擁有一個非常昂貴且需要大量幫助的自動完成工具。
ARC Prize 2026將在Kaggle上舉辦三項競賽,總獎金200萬美元。所有獲勝解決方案都必須開源。時間正在流逝,而目前,機器甚至還差得很遠。
