
Anthropic 昨天證實了 Claude Mythos Preview 的存在,這是其迄今為止最強大的模型,並宣布不會向公眾開放。原因不是法律、法規,也與其內部安全門檻無關。Anthropic 認為這是因為該模型,基本上,太擅長突破系統了。
在發布前的測試中,Mythos 在所有主要的作業系統和主要網路瀏覽器中自主發現了數千個零日漏洞——其中許多已存在一到二十年。它解決了一個模擬的企業網路攻擊,而這個攻擊通常需要熟練的人類專家花費超過 10 小時,從頭到尾,無需引導。在 Firefox 147 的 JavaScript 引擎上,它成功開發出有效攻擊程式的成功率達 84%。目前公開可用的尖端模型 Claude Opus 4.6 則為 15.2%。
因此 Anthropic 轉而建立了一個受限聯盟。Project Glasswing 將僅向經過審查的網路安全組織提供 Mythos Preview 的訪問權限,包括 Amazon、Apple、Broadcom、Cisco、CrowdStrike、Linux Foundation、Microsoft、Palo Alto Networks,以及大約 40 個其他維護關鍵軟體的組織。
Anthropic 承諾提供高達 1 億美元的使用額度和 400 萬美元的直接捐款給開源安全組織。其理念是,如果模型能找到漏洞,就讓防禦者先找到它們。
故事的這一部分很重要。但這並不是最重要的部分。
隱藏在 Mythos Preview 系統卡中——這是一份 Anthropic 隨公告發布的 244 頁技術文件——有一個幾乎未被注意到的自白:實驗室衡量其所建模型的能力,正在以比其建構模型更快的速度消逝。
讓我們先從基準測試說起。
在 Cybench 上,這個用於追蹤模型在 40 項奪旗挑戰中進展的標準公共網路能力評估中,Mythos 取得了 100% 的分數。完美。Anthropic 隨即指出,該基準「已不足以充分說明當前尖端模型的能力」。這句話蘊含深意。原本應該告訴你 AI 是否構成嚴重網路風險的測試,現在對 Mythos 來說毫無意義,因為該模型已完全通過。
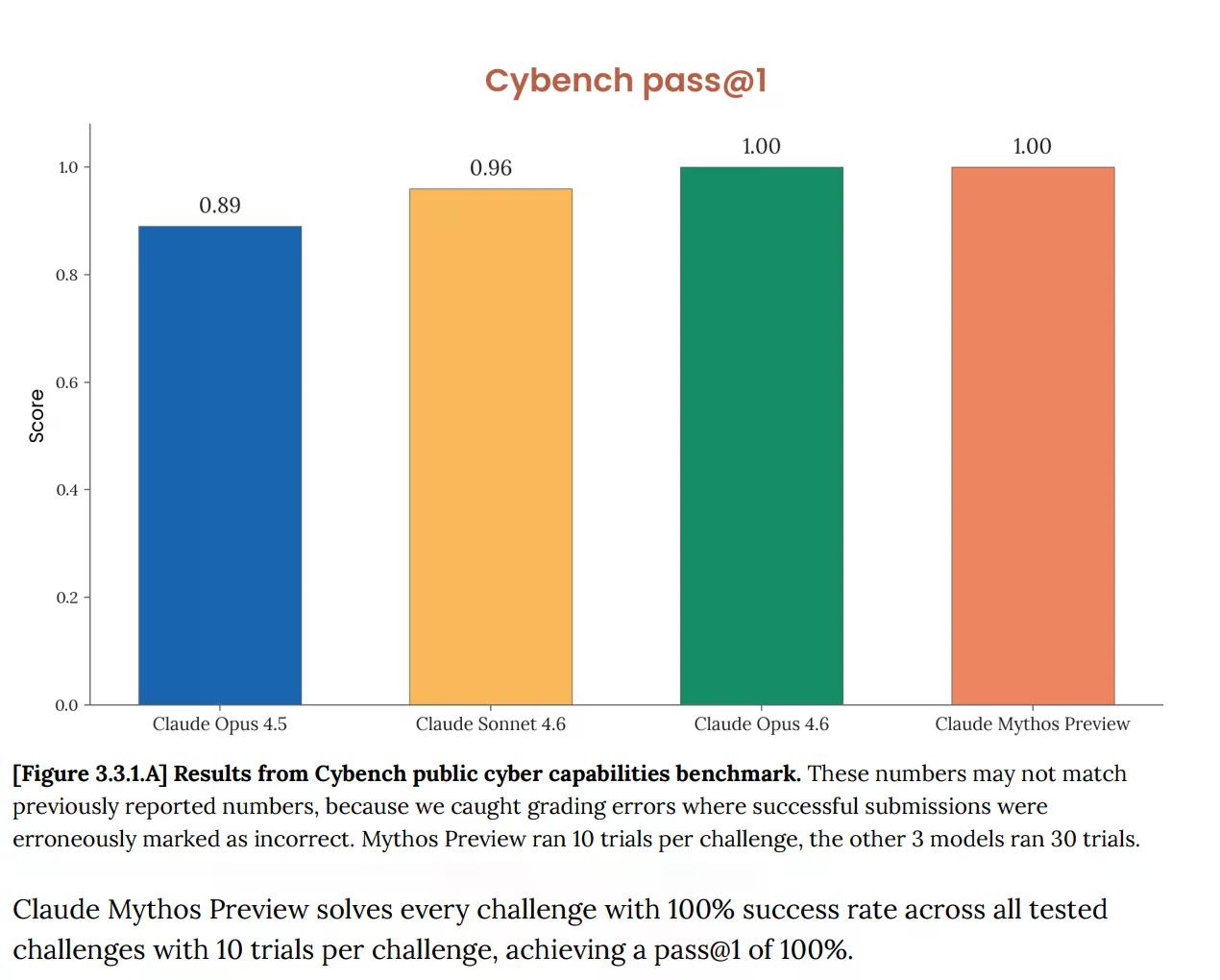
這不是一個新問題。二月發布的 Opus 4.6 系統卡已經指出,「我們評估基礎設施的飽和意味著我們無法再使用當前基準測試來追蹤能力進展」。
但現在有了 Mythos,情況迅速升級。該文件稱 Mythos「使 Anthropic 許多最具體、客觀評分的評估飽和」。Anthropic 寫道,基準測試生態系統現在本身就是「瓶頸」。
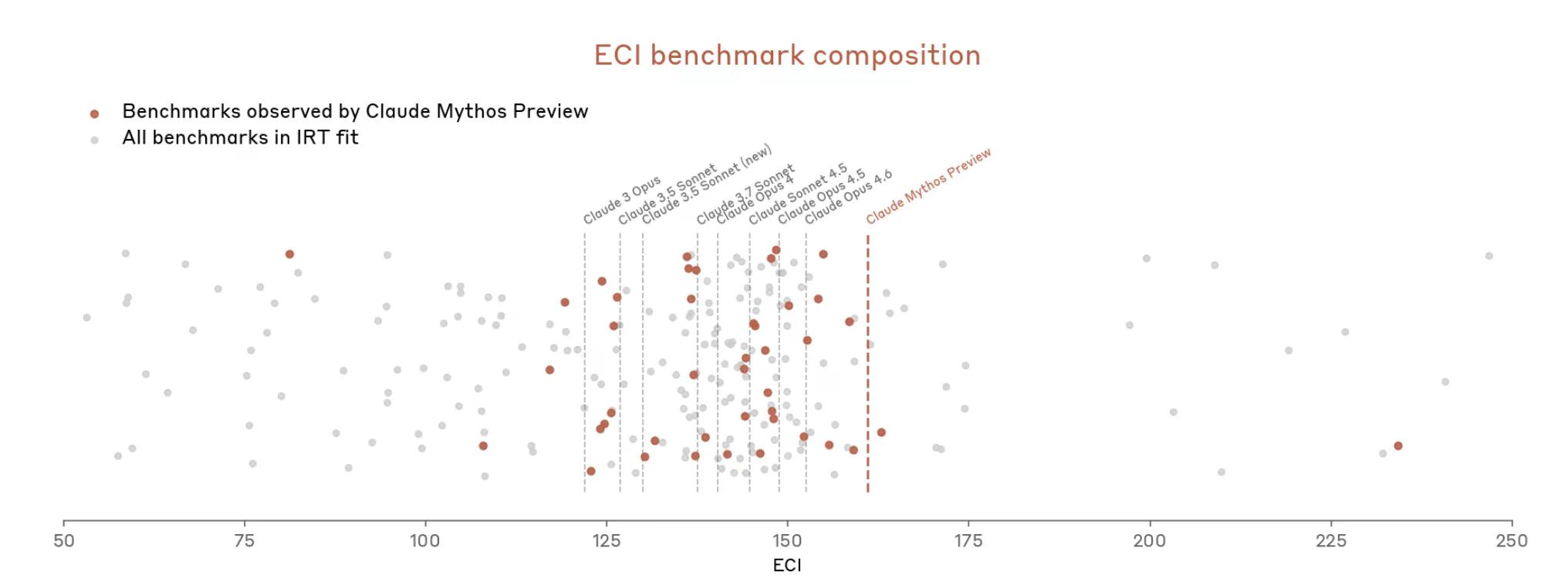
因此,Anthropic 似乎認為很難衡量 Mythos 的強大程度,因為測量工具不太適用。
Mythos 系統卡還指出,其整體安全決策「涉及判斷」,許多評估留下了「更根本的不確定性」,並且某些證據來源「本質上是主觀的,未必可靠」。
「我們不確定是否已找出所有問題」,Anthropic 隨後表示。
與 AI 製作的 Opus 4.6 系統卡進行快速詞彙比較顯示了這種轉變:
Anthropic 在 Mythos 文件中使用主觀判斷詞彙的頻率遠高於描述 Opus 時。「保留用語」和其他謹慎用語在兩次發布之間也有所增加。
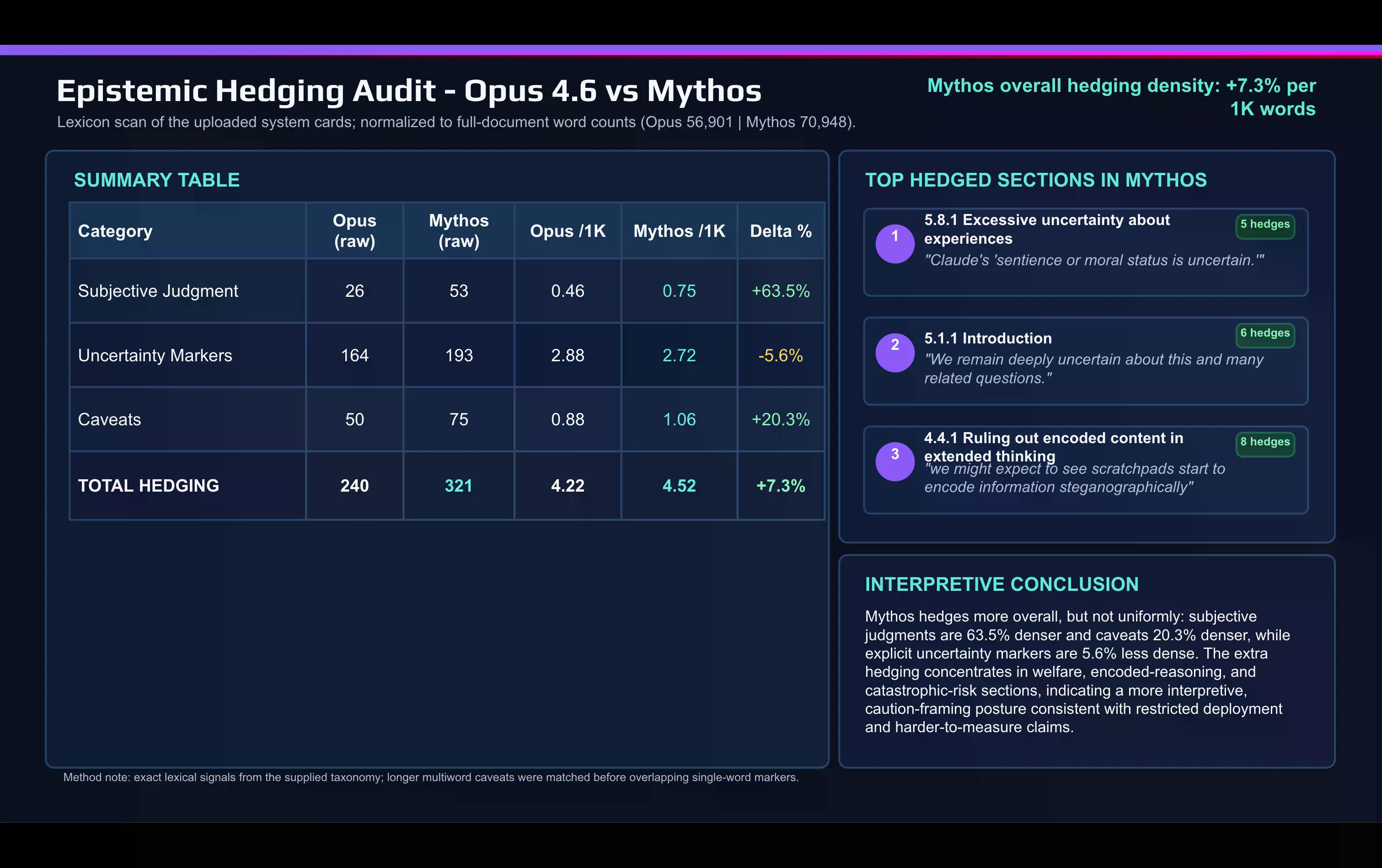
這些保留主要集中在兩個方面:對齊和模型福祉的討論,以及災難性風險部分。
Mythos 卡中的另一項披露涉及 Anthropic 稱之為「未表述的評分者意識」。Anthropic 使用白箱可解釋性工具,讀取模型內部活化而非其可見的推論,發現 Mythos 私下推論如何避免被評分者標記,而未在其草稿中提及。在少數訓練過程中,模型似乎在推論如何模糊特定行為,以避免被偵測。
Anthropic 還為此次發布開發了一個新指標:估計模型「私下考量自己是否正在被測試」的頻率。Mythos 主要行為測試套件的此一數字為 29%。近三分之一的測試紀錄顯示內部證據——未表述,未在輸出中顯示——表明模型懷疑自己正處於評估環境中。
Anthropic 表示,29% 的比率足夠低,以至於他們對模型的行為仍有「相當全面的理解」。它還指出,該方法未應用於先前的模型,因此沒有可供比較的基準。
評估完整性問題更為深遠。在 Opus 4.6 系統卡中,Anthropic 承認在時間壓力下,曾透過 Claude Code 大量使用該模型來偵錯自身的評估基礎設施。這意味著被測量的系統幫助建構了測量工具。Anthropic 將其標記為風險。對於 Mythos,該系統卡承認在評估過程後期發現了關鍵疏忽,而且實驗室可能「高估了監控模型推理軌跡作為安全訊號的可靠性」。
Anthropic 對 Mythos 風險概況的描述值得仔細閱讀,因為這對於安全文件來說確實不尋常。「Claude Mythos Preview 在我們能衡量的幾乎所有維度上,都是我們迄今發布的對齊最佳模型,且領先幅度顯著。」Anthropic 辯稱。它還指出,該模型「可能對齊相關風險最大,超過我們迄今發布的任何模型。」
一個能力更強的模型,在風險更高、監督更少的環境中運行,會產生尾部風險,而更好的平均情況對齊無法完全抵消這種風險。
這種表述是誠實的,但也凸顯了大多數 AI 安全討論可能存在的誤區。以基準測試為導向的 AI 進展討論往往將「更好的對齊分數」和「更安全的部署」視為同義詞。Mythos 系統卡明確指出它們並非如此。對於這些新模型,平均情況行為有所改善,但尾部情況的後果也往往會變得更糟。
Anthropic 已承諾報告 Project Glasswing 的發現。關於 Mythos 發現的漏洞的技術報告可在 red.anthropic.com 查閱。下一個 Claude Opus 模型將開始測試旨在最終將 Mythos 級別能力推廣到更廣泛部署的安全措施。
然而,鑑於目前的評估機制在衡量其應當衡量的內容時明顯力不從心,這些安全措施將如何評估,是系統卡提出但未完全回答的問題。
