
Phòng thí nghiệm AI StepFun có trụ sở tại Thượng Hải đã phát hành StepAudio 2.5 Realtime trong tuần này. Đây là một mô hình giọng nói thời gian thực đầu cuối — âm thanh đi vào, âm thanh đi ra, không có chuyển đổi văn bản ở giữa. Nó hỗ trợ tiếng Trung và tiếng Anh, và dựa trên các tiêu chuẩn, có vẻ như nó khá tốt.
Phòng thí nghiệm này nổi tiếng nhất với việc xây dựng các mô hình ngôn ngữ lớn (LLM) dựa trên văn bản, vượt trội hơn nhiều hệ thống lớn hơn. Step 3.5 Flash, một mô hình 196 tỷ tham số, đã đứng đầu bốn tiêu chuẩn suy luận vào đầu năm nay, vượt qua các đối thủ có hàng nghìn tỷ tham số. (Tham số là yếu tố mang lại cho mô hình AI kiến thức rộng lớn, và nói chung, nó tương đương với hiệu suất tốt hơn.)
Công việc về giọng nói cũng tuân theo chiến lược tương tự, và muốn làm cho việc nhập vai trở nên thú vị, đặc biệt trong các phiên kéo dài.
Vấn đề nhân vật
Các hệ thống nhân cách AI có một chế độ lỗi cụ thể: OOC, hay hành vi lệch khỏi nhân vật — mô hình chệch khỏi tính cách được chỉ định dưới áp lực đối kháng. Điều này rất phổ biến và là một khiếm khuyết tồn tại trong tất cả các mô hình AI theo thiết kế. Chúng chỉ đơn giản là quên mọi thứ khi bạn tương tác với chúng nhiều hơn.
StepFun cho biết họ đã giải quyết vấn đề này bằng RLHF chuyên biệt cho nhập vai — học tăng cường từ phản hồi của con người được áp dụng đặc biệt cho sự ổn định nhân cách, chứ không chỉ chất lượng chung. Dữ liệu đào tạo bắt đầu từ hơn 10.000 hạt nhân cách do con người tạo ra, được mở rộng theo thuật toán thành một ma trận tính năng quy mô hàng triệu.
Ý tưởng là: đủ sự đa dạng trong dữ liệu đào tạo để ngay cả những cuộc trò chuyện kỳ lạ, hiếm gặp cũng không làm mô hình mất đi tính cách của nó.
Yêu cầu kỹ thuật thú vị hơn là khả năng hiểu ngôn ngữ phi ngữ âm (paralinguistic comprehension) — mô hình đọc các tín hiệu âm thanh phi lời nói như tốc độ giọng nói, sắc thái cảm xúc và tuổi tác từ chính âm thanh, trước khi nó đưa ra phản hồi.
Trong tiêu chuẩn hiểu ngôn ngữ phi ngữ âm — một bài kiểm tra khách quan đo lường nhận thức các đặc điểm âm thanh như cảm xúc và tốc độ nói, được chấm từ 0–100 — StepAudio đạt 82.18 điểm. GPT Realtime 1.5 đạt 80.46 điểm, Gemini Live đạt 58.05 điểm, và DouBao Realtime đạt 16.09 điểm.
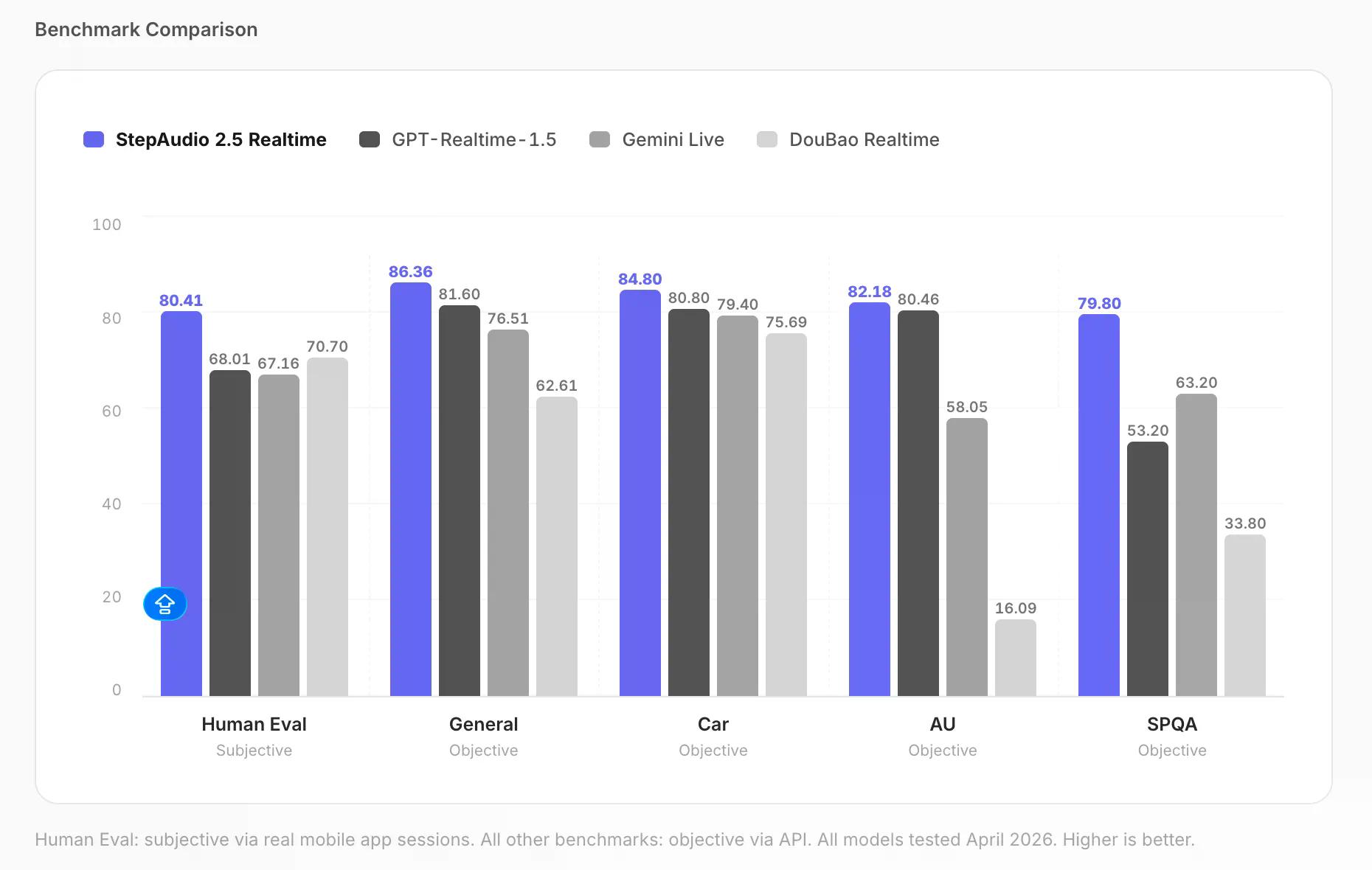
Tiêu chuẩn đánh giá của con người — người dùng thực trò chuyện với mô hình qua ứng dụng di động, được người đánh giá chấm trên thang điểm 0–100 — StepAudio đạt 80.41 điểm, so với 68.01 của GPT Realtime 1.5 và 67.16 của Gemini Live. Chất lượng đối thoại tổng thể, được kiểm tra khách quan qua API trên cùng thang điểm 0–100, đạt 86.36 so với 81.60 của GPT.
Đây là các tiêu chuẩn của riêng StepFun. Bạn có thể tự đánh giá. Nhưng sự chênh lệch về khả năng hiểu ngôn ngữ phi ngữ âm và các phiên hỏi đáp bằng giọng nói đủ lớn để khó có thể bác bỏ.
Bối cảnh của StepFun
StepFun được thành lập vào tháng 4 năm 2023 bởi Jiang Daxin, người đã có 16 năm làm việc tại Microsoft, điều hành các dự án như Bing, Cortana và các dịch vụ nhận thức Azure. Đây là một trong những startup được gọi là "Hổ AI" của Trung Quốc và đã huy động được khoảng 1.7 tỷ USD cho đến nay.
Chế độ giọng nói nâng cao của OpenAI ra mắt vào cuối năm 2024 và đã thiết lập chuẩn mực mà mọi người khác đang theo đuổi. StepFun hiện đang so sánh trực tiếp với nó — và tuyên bố chiến thắng.
Sản phẩm ra mắt bao gồm một nhân cách AI chủ lực tên là Xiao Yue, mà StepFun mô tả là một "người bạn đồng hành cấp độ tâm hồn", được thiết kế để tạo cảm giác như nhắn tin cho một người bạn, chứ không phải truy vấn phần mềm. Ý kiến, khẩu hiệu, giới hạn cảm xúc — hoàn toàn có thể cấu hình.
Các nhà phát triển có thể xây dựng nhân cách của riêng họ thông qua API. Tài liệu đầy đủ có tại platform.stepfun.com, và mô hình hiện đã hoạt động.