
Ideea asistenților personali AI a fost întotdeauna aceeași: Oferă agentului acces la viața ta digitală și el se ocupă de restul. E-mailurile tale, calendarul tău, notițele tale, dispozitivele tale—totul. AI-ul tău știe. AI-ul tău acționează. Tu dormi.
Cercetătorii de la Huawei Technologies, Institutul de Tehnologie din Beijing, Universitatea Peking și Academia Chineză de Științe tocmai au construit un etalon pentru a vedea dacă acest lucru este, de fapt, adevărat. Spoiler: Nu este.
Claw-Anything evaluează agenții AI pe trei dimensiuni simultan: fluxuri de evenimente pe termen lung care acoperă mai mult de trei luni de activitate simulată a utilizatorului, servicii backend interdependente cu o medie de 10,1 per sarcină și interacțiune pe mai multe dispozitive atât în medii CLI Linux, cât și în medii GUI Android.
Fereastra de context medie per sarcină este de 191.700 de cuvinte. Majoritatea etaloanelor existente se situează undeva între 1.700 și 12.000. Aceasta nu este o diferență mică, ci o problemă complet diferită. Este, de asemenea, ceea ce simte viața reală, spre deosebire de etaloanele standardizate ultra-specifice.
AI-ul tău nu are idee ce se întâmplă
Etalonul este punctat pe pass@1—probabilitatea ca agentul să finalizeze o sarcină corect la prima încercare, fără reluări. O sarcină ar putea cere agentului să facă o referință încrucișată a unei alerte de preț pentru un produs găsit cu săptămâni în urmă, să verifice calendarul utilizatorului pentru o programare relevantă și să acționeze în ambele cazuri de pe un telefon. O alta ar putea cere să extragă lucrări recente din notițe, fire de e-mail și Slack, apoi să producă o prezentare de la zero.
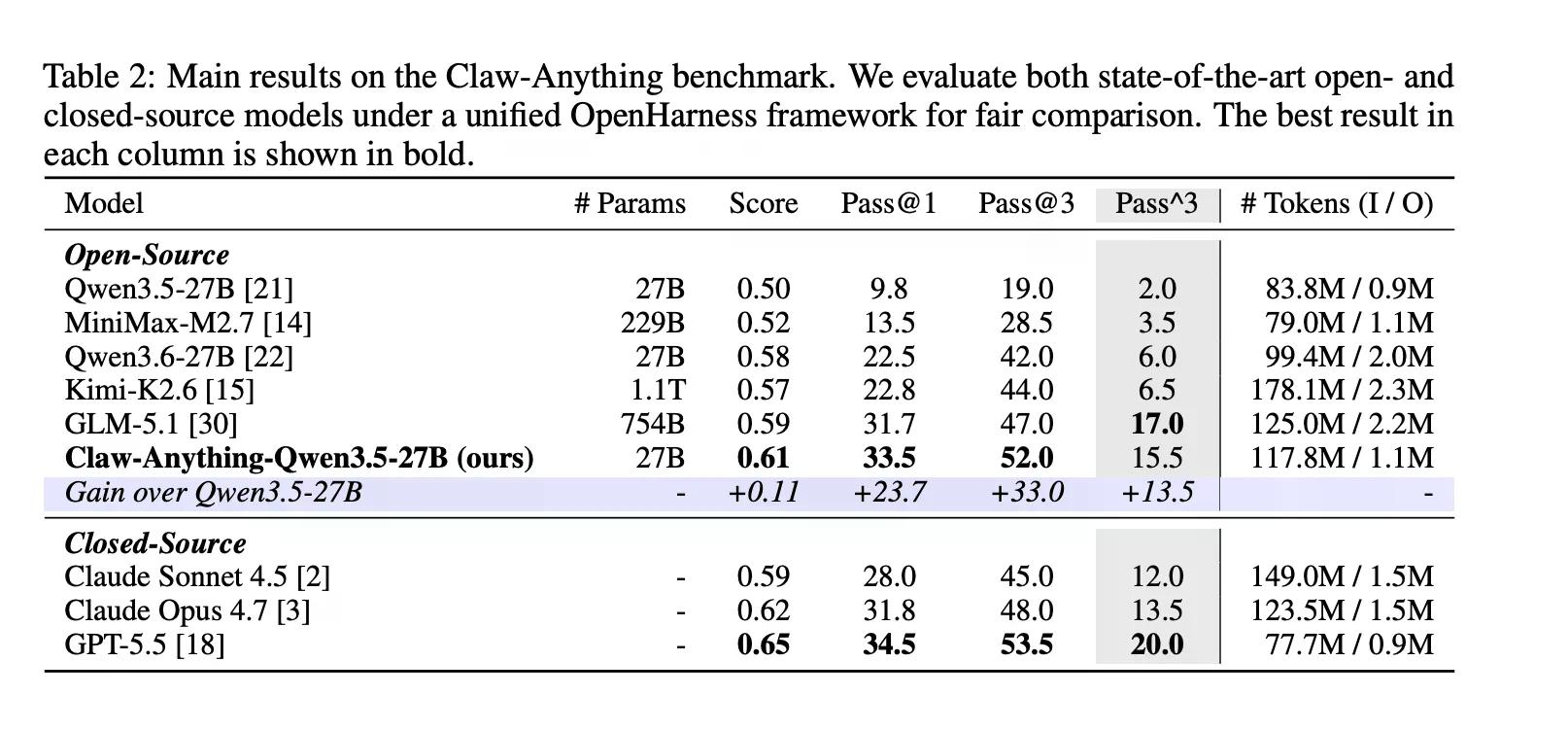
Acestea sunt lucruri pe care oamenii le cer, de fapt, asistenților să le facă. Se pare că AI-ul nu este foarte bun la ele. GPT-5.5, conform acoperirii anterioare a Decrypt, este cel mai bun model al OpenAI, construit având în vedere sarcini agentice, pe termen lung. A obținut un scor de 34,5%.
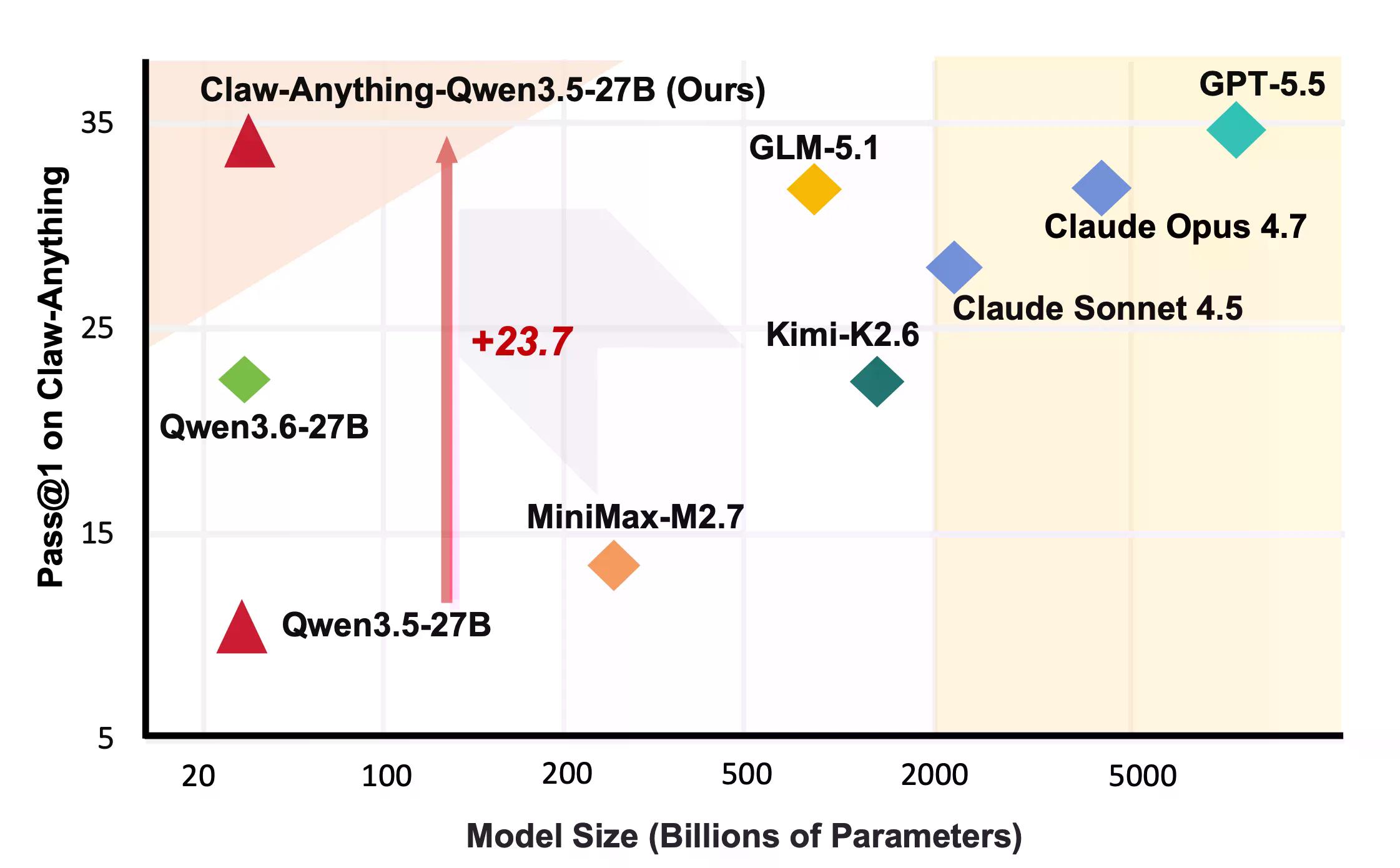
„Modelele actuale rămân nesigure chiar și atunci când li se oferă un acces mai larg la lumea digitală a utilizatorului”, se arată în lucrarea Claw-Anything. Mai multe modele care arătau impresionante pe alte etaloane au scăzut și mai mult.
Etalonul evaluează, de asemenea, asistența proactivă separat, adică cazurile în care agentul detectează o nevoie și acționează fără a fi solicitat. Majoritatea etaloanelor nu testează acest lucru. Claw-Anything o face, iar diferența este izbitoare: Agenții au obținut un scor de 25,9% la sarcinile reactive și doar 6,7% la cele proactive.
De ce majoritatea etaloanelor nu îți spun asta
Cercetătorii aduc un argument pertinent: etaloanele existente tratează agenții AI ca pe niște rezolvatori de sarcini cărora li se oferă un birou curat. Claw-Anything îi tratează ca pe asistenți personali aruncați într-o viață reală dezordonată—evenimente irelevante, semnale conflictuale, luni de zgomot acumulat. Agentul trebuie să-și dea seama ce este relevant înainte de a putea face ceva util.
Rezultatele ablației fac dependența multi-serviciu deosebit de clară. Atunci când instrumentele necesare pentru sarcinile inter-servicii au fost eliminate, ratele de succes au scăzut la aproape zero, deoarece majoritatea sarcinilor necesită ca agenții să extragă informații și să acționeze pe mai multe backend-uri, mai degrabă decât într-unul singur.
Acesta nu este un gen nou de problemă în evaluarea AI. OpenAI a declarat SWE-bench contaminat la începutul acestui an, după ce scorurile au scăzut de la aproximativ 70% la 23% pe o versiune mai puțin predispusă la scurgeri. Aceea a fost despre igiena datelor. Aceasta este despre ceva mai fundamental—dacă etaloanele pun măcar întrebarea corectă.
Pe partea constructivă, echipa a lansat conducta care a generat etalonul alături de 2.000 de medii de antrenament. Ajustarea fină a Qwen3.5-27B pe 1.500 de traiectorii de agenți de succes a îmbunătățit pass@1 cu 23,7%—suficient pentru a învinge mai multe modele closed-source din clasament, inclusiv Claude Sonnet.
Cercetătorii identifică coordonarea inter-servicii ca fiind principala provocare rămasă a etalonului pentru domeniu. Setul de date este pe Hugging Face, iar codul este pe GitHub.
