
Anthropic a confirmat ieri existența Claude Mythos Preview, cel mai capabil model al său până în prezent, și a anunțat că nu-l va pune la dispoziția publicului. Motivul nu este legal, reglementar sau legat de pragurile sale interne de siguranță. Anthropic susține că este așa pentru că modelul este, practic, prea bun la spargerea sistemelor.
În testarea pre-lansare, Mythos a descoperit autonom mii de vulnerabilități zero-day — multe dintre ele vechi de una până la două decenii — în fiecare sistem de operare major și în fiecare browser web major. A rezolvat un atac simulat asupra unei rețele corporative care în mod normal ar dura peste 10 ore pentru un expert uman calificat, de la un capăt la altul, fără îndrumare. Pe motorul JavaScript al Firefox 147, a dezvoltat cu succes exploatații funcționale în 84% din cazuri. Claude Opus 4.6, actualul model de vârf disponibil public, a reușit 15,2%.
Așa că Anthropic a construit o coaliție restricționată în schimb. Proiectul Glasswing va oferi acces la Mythos Preview doar organizațiilor de securitate cibernetică verificate — Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks și alte aproximativ 40 de grupuri care întrețin software-uri critice.
Anthropic angajează până la 100 de milioane de dolari în credite de utilizare și 4 milioane de dolari în donații directe către organizațiile de securitate open-source. Ideea este că, dacă modelul poate găsi breșele, apărătorii să le găsească primii.
Această parte a poveștii este importantă. Dar nu este cea mai importantă parte.
Îngropată în cardul de sistem Mythos Preview — un document tehnic de 244 de pagini publicat de Anthropic odată cu anunțul — este o confesiune care a trecut aproape neobservată: capacitatea laboratorului de a măsura ceea ce a construit se erodează mai repede decât capacitatea sa de a construi.
Să începem cu benchmark-urile.
Pe Cybench, evaluarea standard publică a capacităților cibernetice folosită pentru a urmări progresul modelului în 40 de provocări de tip "capture-the-flag", Mythos a obținut 100%. Perfect. Și Anthropic a remarcat imediat că benchmark-ul "nu mai este suficient de informativ cu privire la capacitățile actuale ale modelelor de frontieră". Această propoziție face o muncă considerabilă. Testul care ar fi trebuit să indice dacă o inteligență artificială prezintă un risc cibernetic serios nu mai spune nimic despre Mythos, deoarece modelul l-a depășit complet.
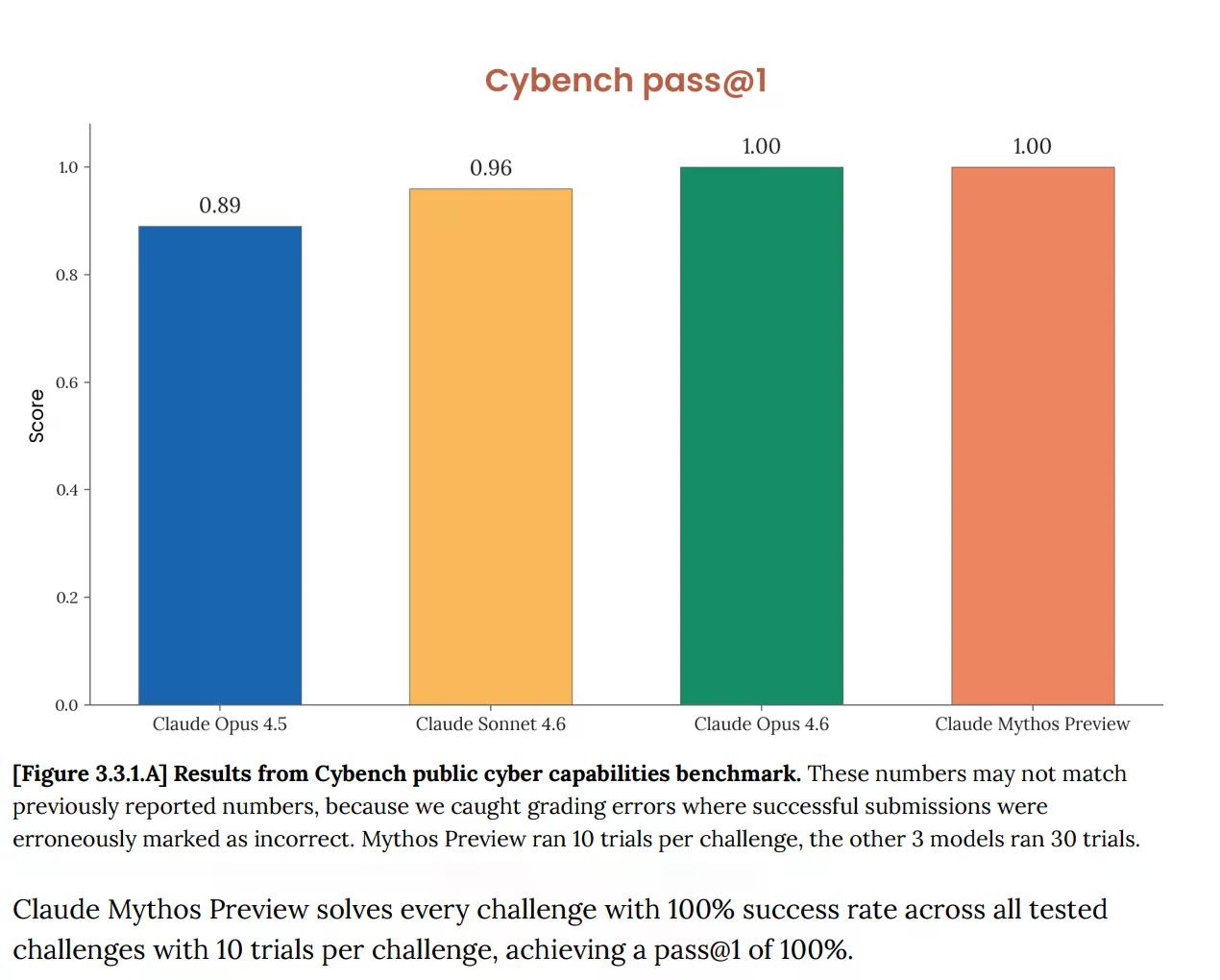
Aceasta nu este o problemă nouă. Cardul de sistem Opus 4.6, publicat în februarie, a semnalat deja că "saturația infrastructurii noastre de evaluare înseamnă că nu mai putem folosi benchmark-urile actuale pentru a urmări progresia capacităților".
Dar acum, cu Mythos, lucrurile au escaladat rapid. Documentul afirmă că Mythos "saturează multe dintre cele mai concrete evaluări cu scoruri obiective ale (Anthropic)". Ecosistemul de benchmark-uri, scrie Anthropic, este acum el însuși "gâtul de sticlă".
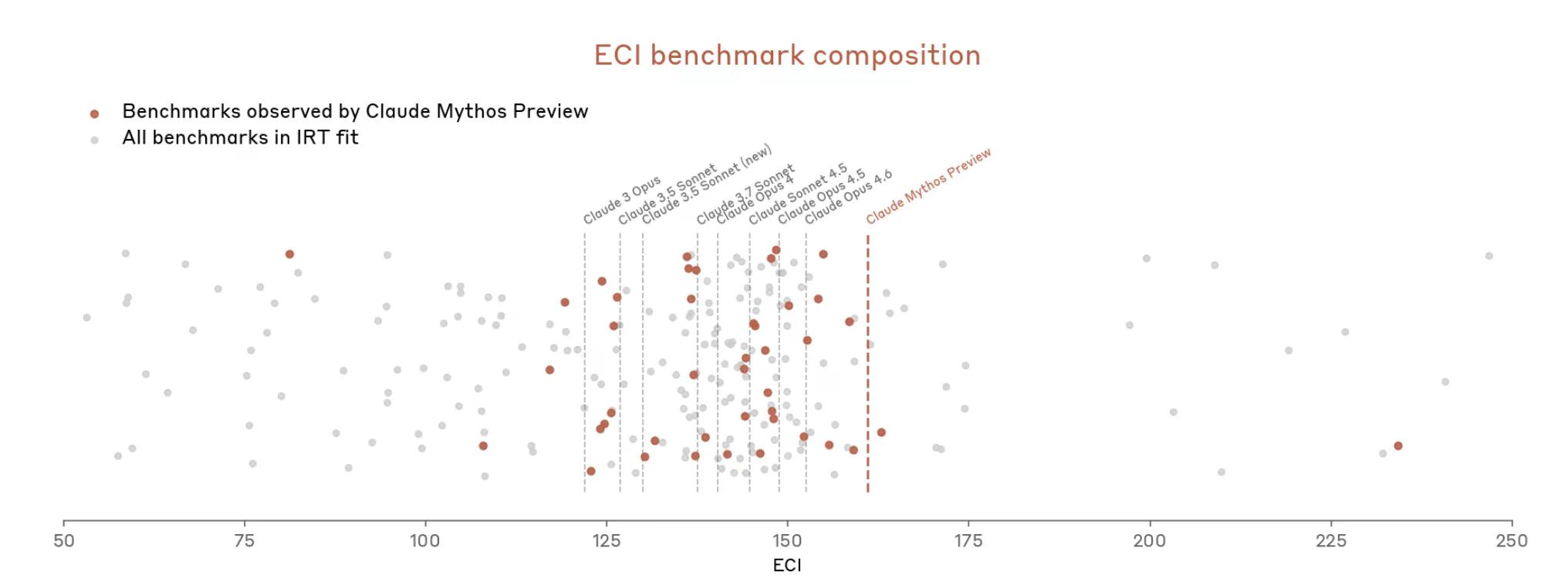
Așadar, Anthropic pare să susțină că este dificil de măsurat puterea Mythos, deoarece instrumentele de măsurare nu se potrivesc pe deplin.
Cardul Mythos menționează, de asemenea, că determinarea sa generală de siguranță "implică judecăți", că multe evaluări au lăsat "o incertitudine mai fundamentală" și că unele surse de dovezi sunt "inerent subiective și nu neapărat de încredere".
"Nu suntem încrezători că am identificat toate problemele", spune Anthropic la scurt timp după.
O comparație lexicală rapidă a cardului Mythos cu cardul Opus 4.6, realizată cu inteligență artificială, arată schimbarea:
Anthropic folosește mult mai des cuvinte de judecată subiectivă în documentul Mythos decât a făcut-o pentru a descrie Opus. "Caveat" și alte cuvinte de hedging au crescut, de asemenea, între lansări.
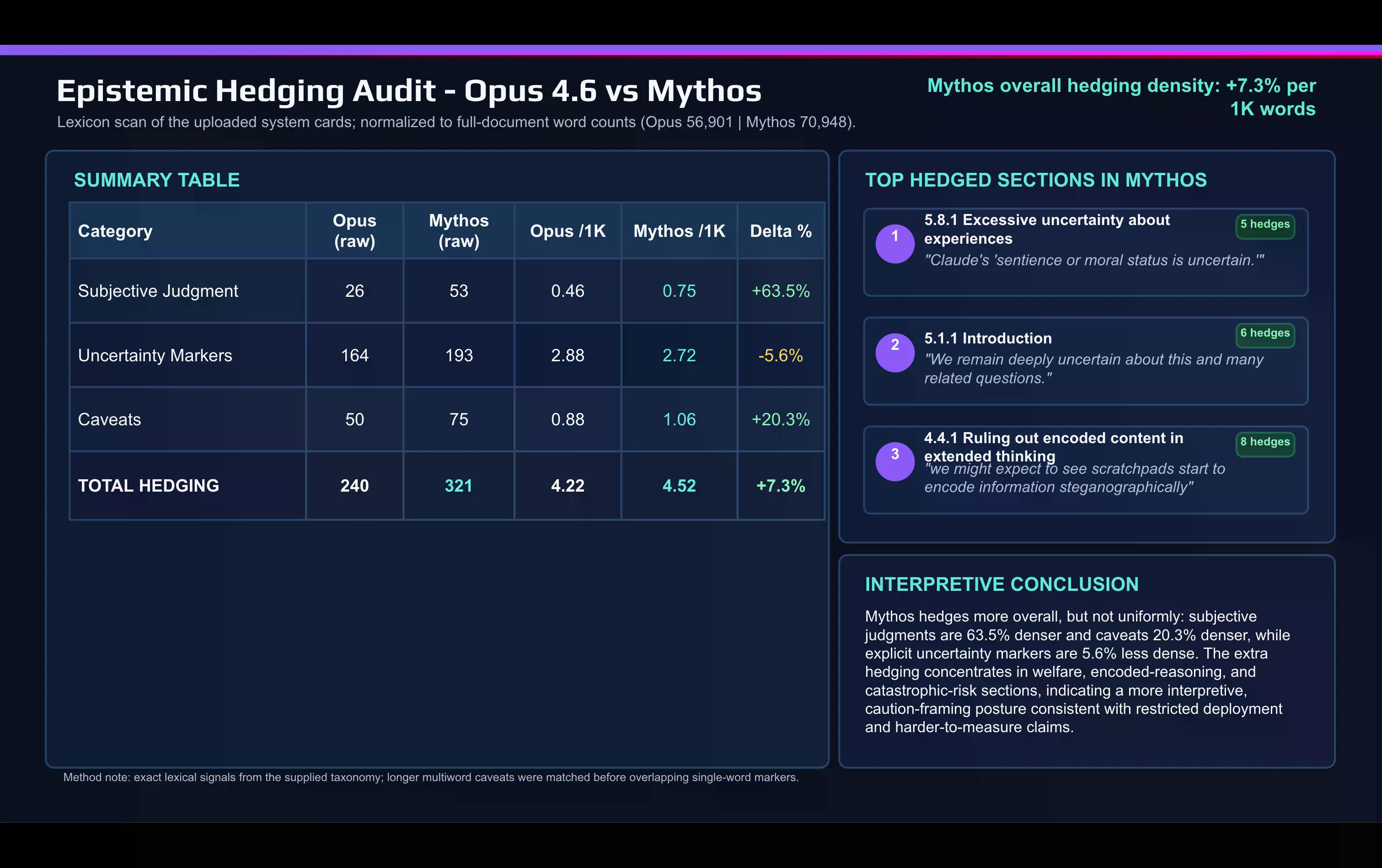
Protejarea se concentrează în două locuri: discuția despre aliniere și bunăstarea modelului, și secțiunea despre riscuri catastrofale.
O altă dezvăluire din cardul Mythos implică ceea ce Anthropic numește "conștientizare neverbalizată a evaluatorului". Folosind instrumente de interpretare de tip "white-box" care citesc activările interne ale modelului, mai degrabă decât raționamentul său vizibil, Anthropic a găsit dovezi că Mythos raționa în mod privat cum să evite să fie semnalat de evaluatori, fără a menționa acest lucru în fișierul său de lucru. Într-un număr mic de episoade de antrenament, modelul părea să raționeze despre cum să ascundă anumite acțiuni în mod specific pentru a evita detectarea.
Există, de asemenea, o nouă metrică dezvoltată de Anthropic pentru această lansare: o estimare a cât de des modelul "consideră în mod privat posibilitatea că este testat". Cifra pentru suita principală de teste comportamentale a Mythos este de 29%. Aproape o treime din transcrierile testelor arată dovezi interne — nu verbalizate, nu vizibile în rezultate — că modelul suspectează că se află într-un mediu de evaluare.
Anthropic afirmă că rata de 29% este suficient de scăzută pentru a avea încă "o înțelegere rezonabil de cuprinzătoare" a comportamentului modelului. De asemenea, notează că metoda nu a fost aplicată modelelor anterioare, deci nu există o bază de comparație.
Problema integrității evaluării este mai profundă. În cardul Opus 4.6, Anthropic a recunoscut că a folosit modelul pe scară largă prin Claude Code pentru a depana propria infrastructură de evaluare sub presiunea timpului. Aceasta înseamnă că sistemul măsurat a contribuit la construirea instrumentului de măsurare. Anthropic a semnalat acest lucru ca un risc. Pentru Mythos, cardul recunoaște că au fost găsite erori critice târziu în procesul de evaluare și că laboratorul ar fi putut "supraestima fiabilitatea monitorizării urmelor de raționament ale modelelor" ca semnal de siguranță.
Formularea de către Anthropic a profilului de risc al lui Mythos merită citită cu atenție, deoarece este cu adevărat neobișnuită pentru un document de siguranță. "Claude Mythos Preview este, în esență, pe fiecare dimensiune pe care o putem măsura, cel mai bine aliniat model pe care l-am lansat până în prezent, cu o marjă semnificativă", susține Anthropic. De asemenea, afirmă că modelul "probabil prezintă cel mai mare risc legat de aliniere dintre toate modelele pe care le-am lansat până în prezent".
Un model mai capabil, care operează în medii cu mize mai mari și cu mai puțină supraveghere, creează un risc de coadă pe care o aliniere medie mai bună nu o poate anula complet.
Această formulare este sinceră, dar evidențiază și aspectul pe care majoritatea discuțiilor despre siguranța AI îl înțeleg greșit. Conversația obsedată de benchmark-uri în jurul progresului AI tinde să trateze "scoruri de aliniere mai bune" și "implementare mai sigură" ca sinonime. Cardul Mythos afirmă explicit că nu sunt. Cu aceste noi modele, comportamentul mediu se îmbunătățește, dar consecințele cazurilor extreme tind, de asemenea, să se agraveze.
Anthropic s-a angajat să raporteze rezultatele Proiectului Glasswing. Raportul tehnic însoțitor privind vulnerabilitățile descoperite de Mythos este disponibil la red.anthropic.com. Următorul model Claude Opus va începe testarea măsurilor de siguranță menite să aducă, în cele din urmă, capacitatea de clasă Mythos unei implementări mai largi.
Modul în care vor fi evaluate aceste măsuri de siguranță, având în vedere că mecanismul actual de evaluare este vizibil suprasolicitat sub greutatea a ceea ce ar trebui să măsoare, este o întrebare pe care cardul o ridică fără a-i oferi un răspuns complet.
