
Większość ludzi zna Xiaomi jako chińską markę telefonów. Tę, która produkuje tanie hulajnogi elektryczne i oczyszczacze powietrza. Nie jest to firma, po której spodziewalibyśmy się pobicia rekordu prędkości inferencji AI w poniedziałkowy poranek.
A jednak. Xiaomi właśnie wydało MiMo-V2.5-Pro-UltraSpeed, tryb obsługi dla swojego flagowego modelu z bilionem parametrów, który osiąga ponad 1000 tokenów na sekundę – ze szczytami bliskimi 1200 w demonstracjach.
Parametry to wewnętrzne wagi numeryczne, które określają sposób myślenia modelu – im więcej ich jest, tym bardziej złożone wzorce może rozpoznać. Tokeny to fragmenty tekstu, które model czyta i zapisuje, średnio stanowiące około trzech czwartych słowa.
Xiaomi dokonało tego na pojedynczym, ogólnodostępnym węźle z 8 procesorami graficznymi. Standardowy sprzęt, bez niestandardowych układów. To zmienia kalkulację, kto faktycznie może wdrożyć tego rodzaju prędkość w produkcji.
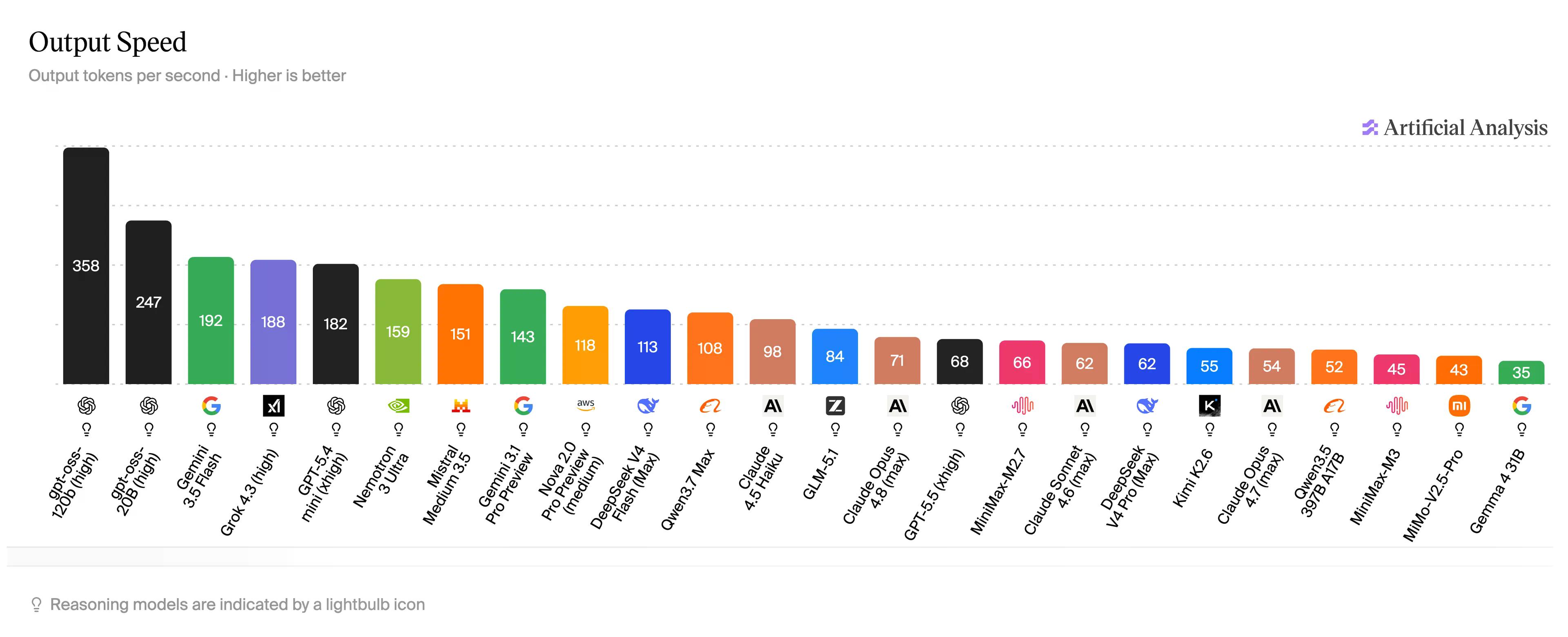
Aby ująć to w bardziej przystępnych terminach: według Artificial Analysis, GPT-5.5 – model, z którym większość użytkowników ChatGPT faktycznie rozmawia – osiąga 68. Claude Opus 4.6 oscyluje wokół 71, a jego niższy model, Haiku, osiąga 98 tokenów na sekundę. Gemini Flash osiąga 192 tokeny na sekundę. MiMo-V2.5-Pro-UltraSpeed osiąga 1000, na modelu, który dorównuje Opusowi w testach kodowania.
Cerebras i Groq zbudowały całe firmy wokół tego problemu. Cerebras zaprojektował układ scalony wielkości talerza obiadowego, pakujący 44 GB pamięci na chipie, aby wyeliminować wąskie gardło przepustowości, które spowalnia inferencję GPU. Osiągnął 969 tokenów na sekundę na Llama 3.1 405B od Meta – imponujące, ale jest to model z 405 miliardami parametrów, mniej niż połowa rozmiaru MiMo-V2.5-Pro. Niestandardowa architektura jednostki przetwarzania języka Groq osiąga od 300 do 750 tokenów na sekundę, w zależności od modelu.
Żaden z nich nie działa na sprzęcie, który można wynająć dziś wieczorem z AWS.
Xiaomi dokonało tego na ogólnodostępnych procesorach graficznych wyłącznie za pomocą oprogramowania – kombinacji sztuczek na poziomie modelu i specjalnie zbudowanego silnika inferencyjnego o nazwie TileRT.
Dwie techniki odpowiadają za tę prędkość. Pierwsza technika to kwantyzacja FP4: zamiast uruchamiać model z pełną precyzją numeryczną 8-bitową lub 16-bitową, Xiaomi redukuje warstwy eksperckie – które stanowią większość z 1 biliona parametrów – do 4-bitów. Zmniejsza się zużycie pamięci, spada obciążenie przepustowości, a prędkość wzrasta. Zazwyczaj wiąże się to z niewielką degradacją jakości. Rozwiązanie Xiaomi jest precyzyjne: tylko warstwy eksperckie są kompresowane, wszystko inne pozostaje z pełną precyzją. Przy tym podejściu, utrata jakości jest opisywana jako bliska zeru.
Druga to spekulatywne dekodowanie DFlash. Zwykłe spekulatywne dekodowanie polega na tym, że mały model wstępny odgaduje kilka następnych tokenów, a następnie duży model weryfikuje je równolegle. DFlash całkowicie pomija sekwencyjne tworzenie wstępnej wersji – wypełnia cały blok zamaskowanych pozycji w jednym przejściu do przodu. W zadaniach kodowania, duży model akceptuje średnio 6,3 z 8 proponowanych tokenów na rundę weryfikacji. Oznacza to sześć tokenów potwierdzonych w jednym kroku zamiast jednego.
TileRT łączy to wszystko. Utrzymuje całą potok obliczeniowy stale rezydentnym w procesorze graficznym – bez narzutu na uruchamianie pojedynczych operacji i bez przerw w wykonaniu.
Xiaomi nazywa to podejście "ekstremalnym współprojektowaniem modelu i systemu", a to sformułowanie jest trafne: żadna z tych technik sama w sobie nie osiąga 1000 tokenów na sekundę, ale synergia wszystkich podejść już tak.
MiMo-V2.5-Pro to model na poziomie granicznym. Pisaliśmy o premierze V2.5 Pro w kwietniu – dorównuje on Claude Opusowi w większości testów kodowania i działa za około 0,43 USD za wejście / 0,87 USD za wyjście za milion tokenów. Opus kosztuje 5 USD za wejście / 25 USD za wyjście za milion tokenów.
UltraSpeed przyspiesza dokładnie ten sam model MiMo V2.5 Pro, a nie jego uproszczoną wersję.
Wystarczająco szybka inferencja zmienia sposób wykorzystania modelu. Można uruchomić dziesiątki ścieżek rozumowania równolegle, zamiast czekać na jedną odpowiedź. Wykrywanie oszustw, generowanie sygnałów transakcyjnych, pętle agentów w czasie rzeczywistym – wszystkie te zastosowania mają twarde ograniczenia dotyczące opóźnień, których 60 tokenów na sekundę nie jest w stanie sprostać. Przy 1000 tokenów na sekundę jest to możliwe.
Xiaomi wycenia tę prędkość na 3-krotność standardowej stawki MiMo-V2.5-Pro za około 10-krotnie większą wydajność. Wersja próbna API będzie trwać od 9 do 23 czerwca, dostępna na podstawie wniosków, z priorytetem dla firm i profesjonalnych deweloperów. Punkt kontrolny FP4-DFlash jest już dostępny w open source na platformie Hugging Face do testów społecznościowych.
