
IplanRIO z Rio de Janeiro wydało Rio 3.5 13 czerwca. Miejska agencja IT nazwała go modelem klasy przełomowej: 397 miliardów parametrów, z liberalną licencją open-source, zbudowanym przez samorząd miejski miasta z Globalnego Południa.
Moment premiery Rio 3.5 był idealny: Brazylia rozgrywała swój mecz otwarcia Mistrzostw Świata, a media społecznościowe już huczały. Komentarze na jego temat szybko rozprzestrzeniły się z Brazylii na cały świat.
Ale tak szybko, jak zyskał uwagę, pojawił się spór o to, kto dokładnie stworzył ten model.
Oryginalna karta modelu opisywała Rio 3.5 jako post-trening Qwen 3.5 397B, otwartego modelu bazowego Alibaby, z dodaną nową warstwą rozumowania o nazwie SwiReasoning. Koszt rozwoju oszacowano na 500 000 R$ (Rio tego nie potwierdziło), czyli prawie 100 000 USD – około 30 razy taniej niż równoważne, gotowe systemy AI.
Architektura to Mixture-of-Experts, co oznacza, że tylko około 17 miliardów z 397 miliardów parametrów aktywuje się dla każdego tokena. To sprawia, że wnioskowanie jest tańsze, niż sugerowałaby ogólna wielkość. Model obsługuje również wizję i tekst, obsługuje kilkanaście języków i jest dostarczany na podstawie w pełni otwartej licencji MIT.
SwiReasoning to techniczny rdzeń. To wolna od treningu struktura wnioskowania, która dynamicznie przełącza się między dwoma trybami. Gdy model jest pewny co do następnego słowa – niska entropia w rozkładzie prawdopodobieństwa – rozumuje w języku naturalnym. Gdy jest niepewny, przechodzi do ukrytego rozumowania, myśląc w ukrytych stanach wewnętrznych bez emitowania tokenów. IplanRIO stwierdziło, że Rio 3.5 został specjalnie wytrenowany do wykorzystania tej cechy, a zyski widoczne są w liczbach z benchmarków.
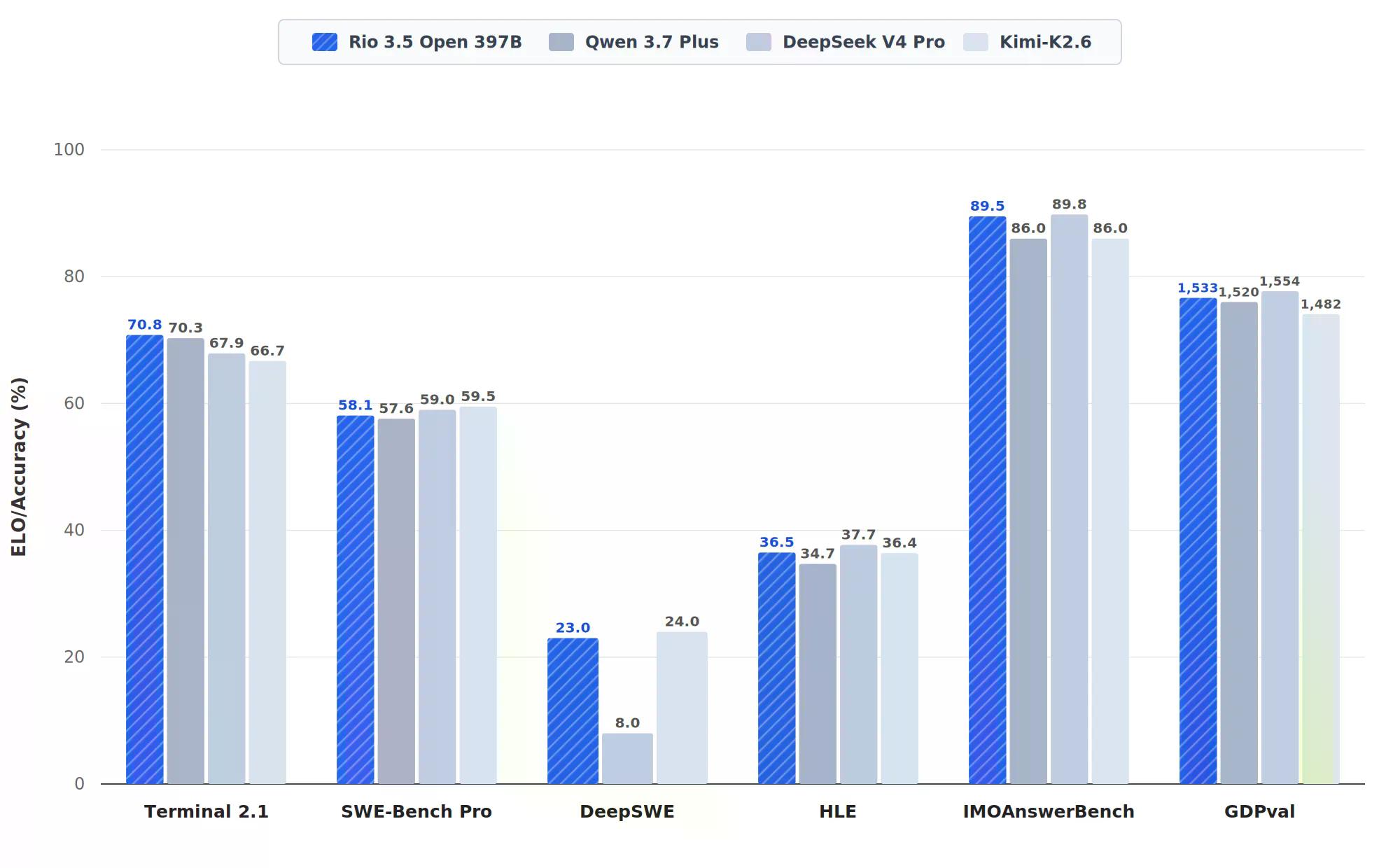
Samodzielnie zgłoszone wyniki były imponujące. Terminal-Bench 2.1 – mierzący autonomiczne wykonywanie komend terminala, oceniane jako procent wykonanych zadań – wyniósł 70.8% dla Rio 3.5, wyprzedzając Qwen 3.7 Plus z 70.3% oraz potężny DeepSeek v4 Pro z 67.9%.
W IMOAnswerBench, benchmarku olimpiad matematycznych ocenianym jako procent poprawnych odpowiedzi, Rio 3.5 osiągnął 89.5%. W HLE – Humanity's Last Exam, prawie nierozwiązywalnym, multidomenowym teście eksperckim ocenianym procentowo – Rio 3.5 uzyskał 36.5%, wyprzedzając Qwen 3.7 Plus z 34.7%.
Samorząd miejski bijący najważniejsze flagowe modele w najbardziej znaczących testach jakościowych: Taki nagłówek rozprzestrzenił się, zwłaszcza po tym, jak burmistrz Rio de Janeiro napisał o tym na Twitterze.
„Otwarty model AI wytrenowany w Rio i publicznie finansowany przez ostatni rok przez [Urząd Miasta Rio] właśnie prześcignął wszystkie inne modele” – napisał Eduardo Cavaliere. „Dziś świat mówi o otwartym modelu AI wytrenowanym w Rio.”
🇧🇷 Modelo de IA aberta treinada no Rio com financiamento público ao longo do último ano pela @Prefeitura_Rio superando todos os outros modelos. Inteligência artificial não é uma coisa distante, estrangeira, de laboratório bilionário…não existe só pra fazer texto, imagens… https://t.co/GK1ThytVV9
— Eduardo Cavaliere (@CavaliereRio) June 14, 2026
„Wytrenowany w Rio” okazał się nie do końca dokładnym stwierdzeniem.
Nex-AGI, szanghajski sojusz AI open-source, opublikował post na X dni po premierze. Otwarcie: "Model Rio 3.5 podbił internet w tym tygodniu. Zwrot akcji? To zasadniczo nasz model open-source, Nex N2 Pro, pod inną nazwą."
Przeanalizowali wagi. Matematyka była dokładna: Rio 3.5 ≈ 0.6 × Nex N2 Pro + 0.4 × Qwen 3.5. Następnie opublikowano skrypt weryfikacyjny i pełny raport GitHub.
The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro + 0.4 * Qwen 3.5
It even literally introduces itself… pic.twitter.com/yHRRu37aut
— Nex (@NexEcosystem) June 14, 2026
Dowody były dwuczęściowe.
Po pierwsze, behawioralne. Nex usunął zakodowaną na stałe systemową podpowiedź "Jesteś Rio" z wdrożonego modelu i wysłał mu 120 pytań dotyczących tożsamości. Bez maski, Nex podaje, że model nazywał się "Nex, z Nex-AGI" w 79.2% przypadków. Nazywał się "Rio" dokładnie w 0% przypadków. Nex stwierdził, że model recytował również dosłownie konkretną historię firmy, wspominając "Shanghai Innovation Institute" i "sojusz ekosystemu dużych modeli". To własne dane treningowe Nexa, pojawiające się w modelu kogoś innego.
Po drugie, matematyczne. W prawdziwym połączeniu wag, każdy parametr w nowym modelu leży na linii prostej między dwoma modelami źródłowymi. Nex zmierzył tę współliniowość na wszystkich 60 warstwach. Wynik wyniósł 0.993. Dwa niezwiązane ze sobą modele w tej samej przestrzeni parametrów uzyskałyby przypadkowo wynik bliski zeru. Osiągnięcie 0.993 na każdej pojedynczej warstwie nie jest zbiegiem okoliczności. Stosunek mieszania wynosił α ≈ 0.571, stabilny z dokładnością do trzech miejsc po przecinku.
Zasadniczo, był to prawie 60% Nex, a reszta to model bazowy Qwen.
"Każdy tensor wag w Rio jest, z tysiącami odchyleń standardowych, taką samą mieszanką 0.6/0.4 Nex i Qwen – we wszystkich 60 warstwach i każdym komponencie sieci" – napisał Nex. "Nie ma niewinnego wyjaśnienia."

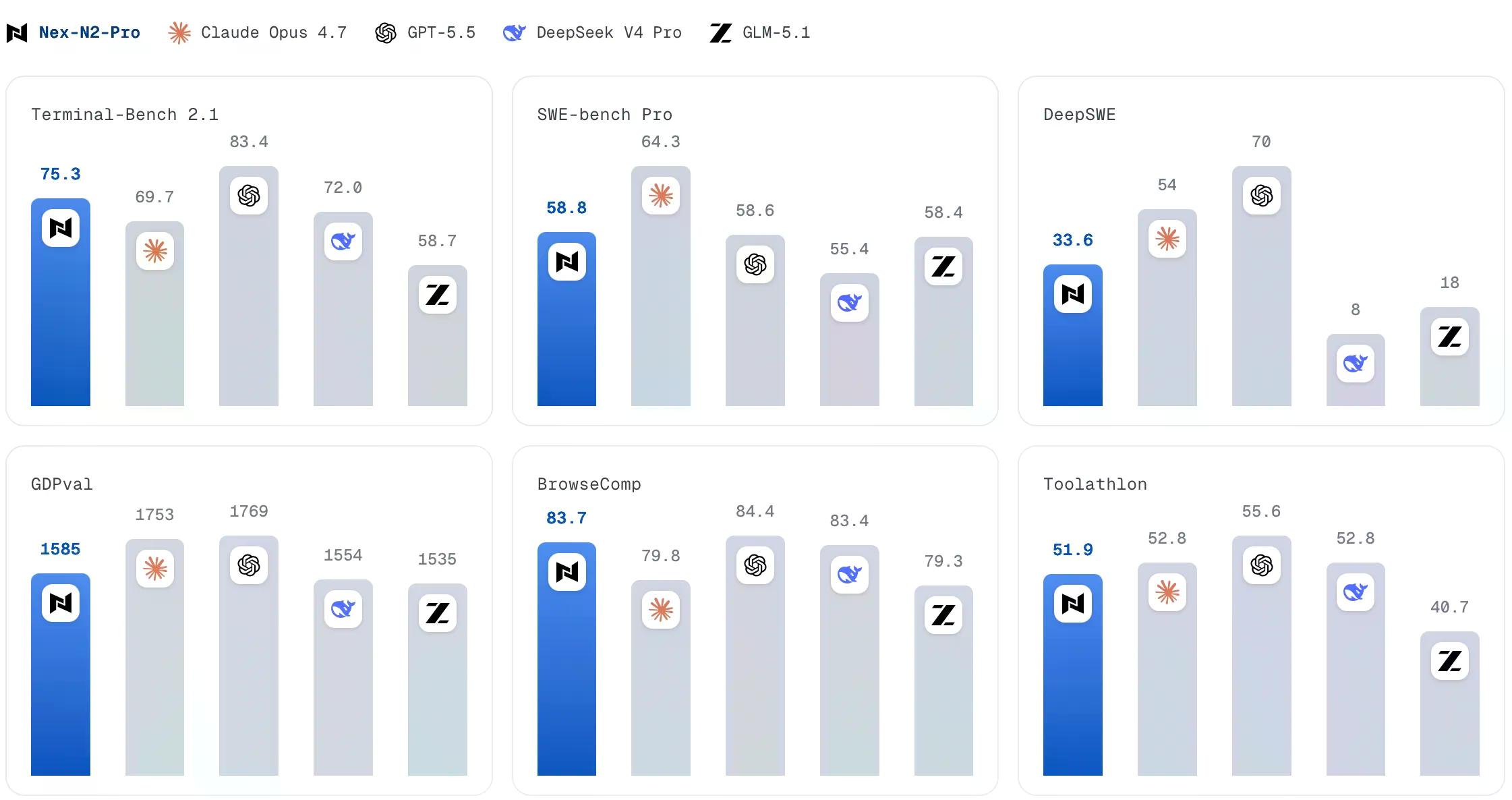
Liczby opowiadały również cichszą historię. Nex N2 Pro, wydany zaledwie kilka dni przed Rio 3.5, osiąga 75.3% w Terminal-Bench 2.1 – więcej niż 70.8% Rio. W GDPval, benchmarku prognoz ekonomicznych ocenianym w stylu Elo, Nex osiąga 1,585 wobec 1,533 Rio. Jeśli Rio to 60% Nex, to można by oczekiwać, że będzie punktował niżej niż Nex w własnych benchmarkach Nexa. I tak jest.
IplanRIO zaktualizowało kartę modelu na Hugging Face – tabela benchmarków zniknęła, a atrybucja została zmieniona.
„Model jest zbudowany poprzez połączenie nex-agi/Nex-N2-Pro i Qwen/Qwen3.5-397B-A17B, poprzedzone destylacją na podstawie polityki (On-Policy Distillation) z silniejszego modelu” – czytamy w zaktualizowanym pliku Readme. „Wykryliśmy nieprawidłowe przesłanie w poprzedniej wersji, gdzie zamiast ostatecznego modelu destylowanego przesłano podstawową wersję połączoną. Przepraszamy za zamieszanie i serdecznie przepraszamy.”
Żadne inne publiczne oświadczenie IplanRIO nie zostało wydane. Nex jest teraz wymieniony jako źródło.
Wyjaśnienie dotyczące „błędnego wgrania” jest kluczowym twierdzeniem. IplanRIO twierdzi, że zamierzonym wydaniem była destylowana wersja połączonej bazy – a nie samo surowe połączenie. Destylowanie oparte na polityce oznacza, że silniejszy model-nauczyciel generuje wyjścia, a model-uczeń trenuje na nich, jednocześnie generując własne. Jest to droższe niż surowe połączenie, ale nadal tańsze niż trenowanie od podstaw. Gdyby ten krok był rzeczywisty, stanowiłoby to przynajmniej pewien oryginalny wkład w oparciu o połączenie.
To, co faktycznie wysłano, według IplanRIO, to połączona baza bez żadnych dodatków.
Obserwatorzy społeczności podzielili się opiniami na temat tego, co to oznacza. Komentator technologiczny Rafael Quintanilha przedstawił łagodne wytłumaczenie: ponieważ Nex N2 Pro sam jest zbudowany na Qwen, zespół mógł przypisać architekturę bazową i na tym poprzestać. Zauważył również, że model stał się wirusowy podczas meczu Mistrzostw Świata, „niekoniecznie będąc ‘gotowym do publicznego użytku’”.
about the Rio 3.5 situation
merging two ~400B-class models and then applying policy distillation isn’t trivial
that said, they made two mistakes:
- a technical error (probably caused by a lack of attention to detail)
- and a communication one (we can debate the integrity of…
— montano (@lucas_montano) June 15, 2026
Deweloper i YouTuber AI Lucas Montano zauważył, że „łączenie dwóch modeli klasy ~400B, a następnie stosowanie destylacji opartej na polityce nie jest trywialne” – jednocześnie uznając błąd techniczny i komunikacyjny.
Badacz AI, Diego Ambrosio, był mniej hojny. Oryginalna premiera opisywała Rio 3.5 jako wynik „autonomicznego post-treningu i własnościowego dostrajania” – sformułowanie to sugerowało oryginalne badania, a nie połączenie.
Łączenie modeli jest całkowicie legalne. Nex N2 Pro jest na licencji Apache 2.0 – można go używać, modyfikować i rozpowszechniać, o ile się go przypisuje. Qwen 3.5 również ma otwartą licencję. Nikt nie idzie do sądu. tutaj.
Problemem było przedstawienie wyniku jako niezależnie opracowanej pracy bez podania nazw *wszystkich* modeli źródłowych. Społeczność open-source widziała to już wcześniej. Wcześniej w tym roku okazało się, że Composer 2 firmy Cursor został zbudowany na bazie Kimi K2.5 firmy Moonshot bez ujawnienia. Reakcja była szybka i reputacyjna – bez prawników, tylko zrzuty ekranu.
was messing with the OpenAI base URL in Cursor and caught this
accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast
so composer 2 is just Kimi K2.5 with RL
at least rename the model ID https://t.co/MQOuEuF3Pd pic.twitter.com/fyUWbo1InF— fynn (@fynnso) March 19, 2026
Budowanie na istniejących otwartych modelach jest normą. Jak donosi Decrypt, łączenie i nakładanie otwartych wag jest praktycznie własną subkulturą. Normą nie jest „nie buduj na pracy innych”. Normą jest: Powiedz, czego użyłeś.
To, co sprawiło, że sprawa była głośniejsza niż typowe pominięcie atrybucji, to instytucjonalne tło. Pseudonimowy deweloper, wypuszczający hybrydę pod własną nazwą, to jedno. Samorząd miejski, wykorzystujący to do twierdzenia o suwerenności AI w sektorze publicznym – podczas Mistrzostw Świata – to coś zupełnie innego. „To było marnowanie zasobów” – napisał jeden z brazylijskich komentatorów.
Nex nie rozpętał wojny. "Jesteśmy zaszczyceni, że Miasto Rio wykorzystało naszą pracę do osiągnięcia wydajności SOTA" – napisała firma na X. "Ale w świecie open-source, atrybucja ma znaczenie."
IplanRIO pracuje nad przesłaniem poprawionego, destylowanego modelu z pełną atrybucją. Gdy to nastąpi, te same kontrole zostaną przeprowadzone ponownie – a społeczność dowie się, czy destylacja faktycznie coś zmieniła, czy też nadal jest to w większości Nex z innym promptem systemowym.
