
Wizja osobistych asystentów AI zawsze była taka sama: Daj agentowi dostęp do swojego cyfrowego życia, a on zajmie się resztą. Twoje e-maile, kalendarz, notatki, urządzenia – wszystko. Twoja AI wie. Twoja AI działa. Ty śpisz.
Badacze z Huawei Technologies, Beijing Institute of Technology, Uniwersytetu Pekińskiego i Chińskiej Akademii Nauk właśnie stworzyli benchmark, aby sprawdzić, czy to rzeczywiście prawda. Spoiler: Nie jest.
Claw-Anything ocenia agenty AI jednocześnie w trzech wymiarach: długoterminowych strumieniach zdarzeń obejmujących ponad trzy miesiące symulowanej aktywności użytkownika, współzależnych usługach backendowych ze średnią 10,1 na zadanie oraz interakcji wielo-urządzeniowej w środowiskach CLI Linux i GUI Android.
Średnie okno kontekstowe na zadanie wynosi 191 700 słów. Większość istniejących benchmarków oscyluje między 1 700 a 12 000. To nie jest mała różnica, lecz zupełnie inny problem. Tak właśnie wygląda prawdziwe życie, w przeciwieństwie do zestandaryzowanych, ultrarazowych benchmarków.
Twoja AI nie ma pojęcia, co się dzieje
Benchmark jest oceniany na podstawie pass@1 — prawdopodobieństwa, że agent poprawnie wykona zadanie za pierwszym razem, bez poprawek. Zadanie może prosić agenta o sprawdzenie alertu cenowego dotyczącego produktu znalezionego tygodnie temu, sprawdzenie kalendarza użytkownika pod kątem odpowiedniego spotkania i działanie na obu tych danych z telefonu. Inne może wymagać pobrania ostatniej pracy z notatek, wątków e-mail i Slacka, a następnie stworzenia prezentacji od zera.
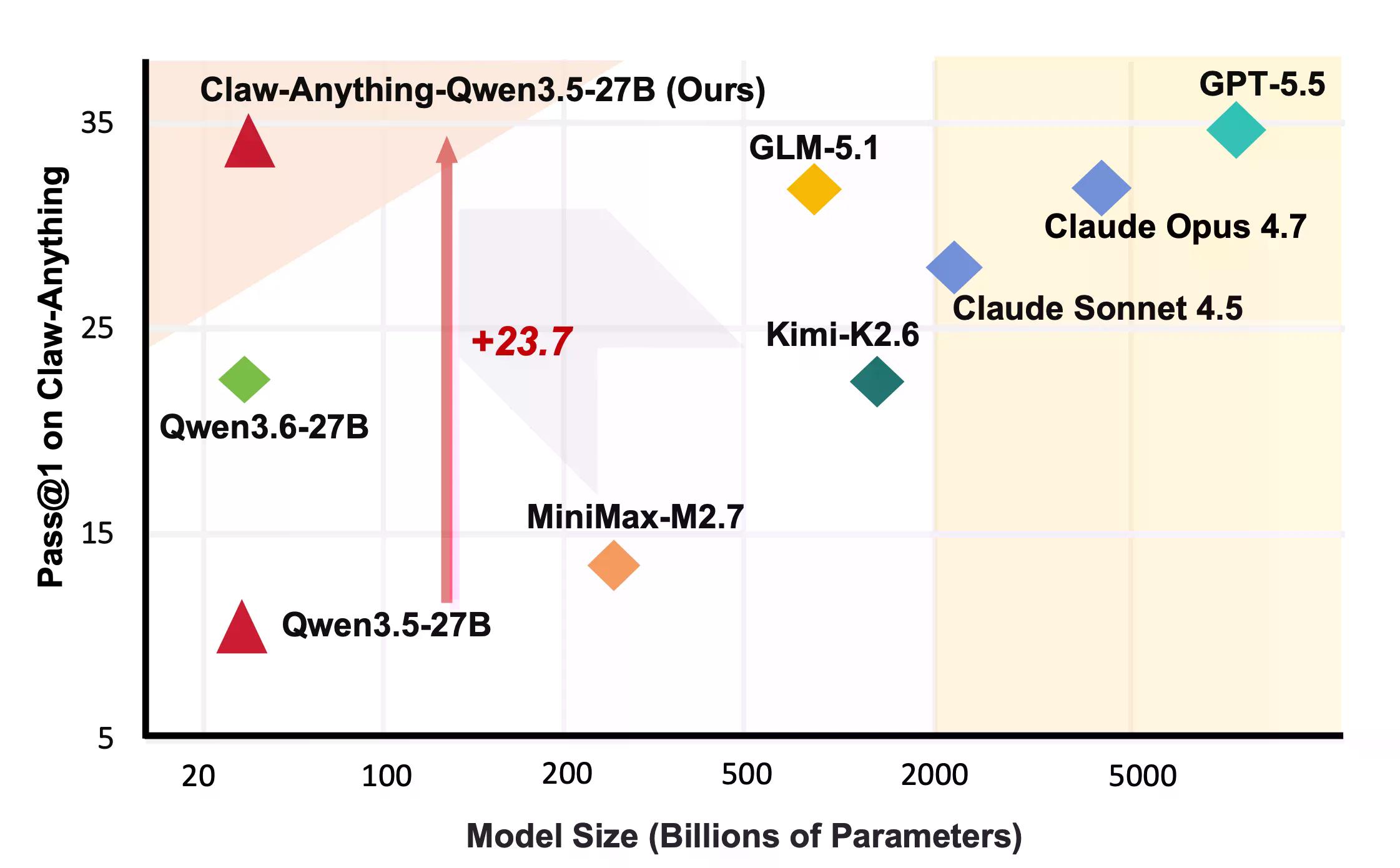
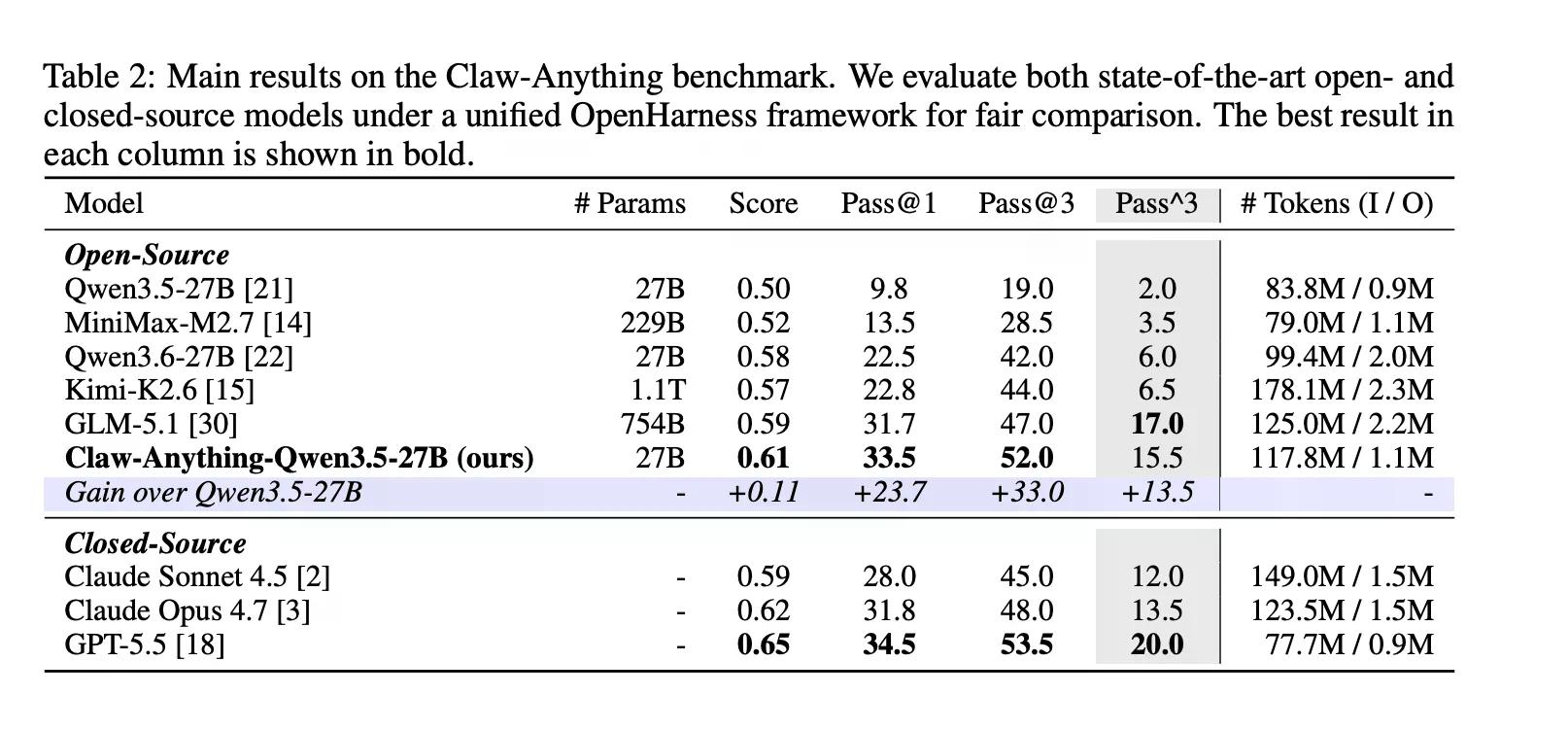
To są rzeczy, o które ludzie faktycznie proszą asystentów. Okazuje się, że AI nie jest w tym zbyt dobra. GPT-5.5, zgodnie z wcześniejszymi relacjami Decrypt, to najlepszy model OpenAI, stworzony z myślą o agentowych, długoterminowych zadaniach. Uzyskał wynik 34,5%.
"Obecne modele pozostają zawodne, nawet gdy otrzymają szerszy dostęp do cyfrowego świata użytkownika", czytamy w dokumencie Claw-Anything. Kilka modeli, które wyglądały imponująco w innych benchmarkach, odnotowało dalszy spadek.
Benchmark ocenia również oddzielnie asystę proaktywną, czyli przypadki, w których agent dostrzega potrzebę i działa bez zapytania. Większość benchmarków tego nie testuje. Claw-Anything to robi, a różnica jest wyraźna: Agenci uzyskali 25,9% w zadaniach reaktywnych i zaledwie 6,7% w proaktywnych.
Dlaczego większość benchmarków ci o tym nie mówi
Badacze przedstawiają trafny argument: Istniejące benchmarki traktują agenty AI jak rozwiązujących zadania przy czystym biurku. Claw-Anything traktuje je jak osobistych asystentów wrzuconych w prawdziwe, zagracone życie — nieistotne zdarzenia, sprzeczne sygnały, miesiące nagromadzonego szumu. Agent musi najpierw ustalić, co jest istotne, zanim będzie mógł zrobić cokolwiek użytecznego.
Wyniki ablacjacji jasno pokazują zależność od wielu usług. Kiedy narzędzia wymagane do zadań międzyusługowych zostały usunięte, wskaźniki sukcesu spadły niemal do zera, ponieważ większość zadań wymaga od agentów pobierania informacji i działania w wielu systemach backendowych, a nie tylko w jednym.
To nie jest nowy rodzaj problemu w ocenie AI. OpenAI uznało SWE-bench za skażony na początku tego roku, po tym jak wyniki spadły z około 70% do 23% w wersji mniej podatnej na przecieki. Tam chodziło o higienę danych. Tutaj chodzi o coś bardziej fundamentalnego – czy benchmarki w ogóle zadają właściwe pytanie.
Konstruktywną stroną jest to, że zespół udostępnił potok, który wygenerował benchmark, wraz z 2000 środowiskami szkoleniowymi. Dostrojenie Qwen3.5-27B na 1500 udanych trajektoriach agentów poprawiło pass@1 o 23,7% — wystarczająco, by pokonać kilka zamkniętych modeli w rankingu, w tym Claude Sonnet.
Badacze wskazują koordynację między usługami jako główne wyzwanie benchmarku dla branży. Zbiór danych znajduje się na Hugging Face, a kod na GitHubie.
