
Z.ai udostępniło GLM-5.2 16 czerwca, obiecując najwyższe osiągi, pokonując swój już zaawansowany GLM 5.1.
Pekinowe laboratorium, które od stycznia 2025 roku znajduje się na amerykańskiej Liście Podmiotów, wydaje się czerpać korzyści z rosnących obaw dotyczących podejścia Ameryki do AI. W ciągu ostatniego tygodnia, zakaz stosowania Anthropic Fable i wydanie tego nowego modelu przyczyniły się do wzrostu akcji zAI o 90%, co doprowadziło je do nowego historycznego maksimum.
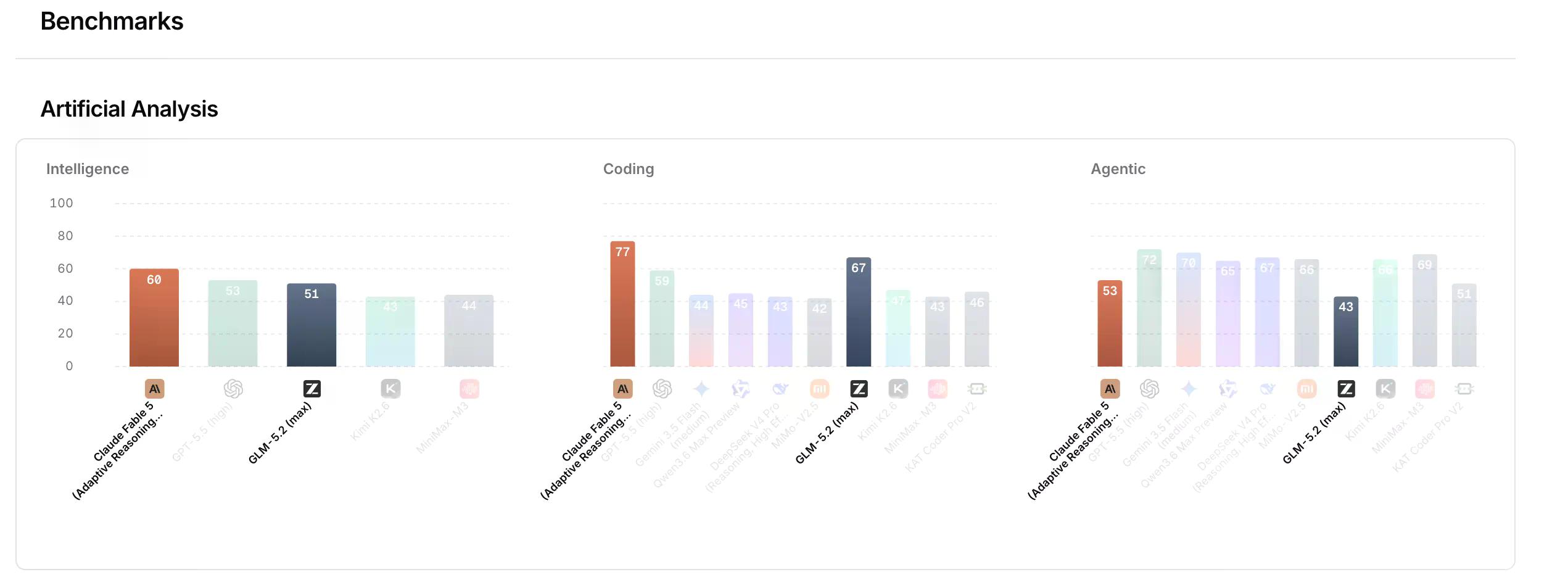
GLM 5.2 ma dane, które potwierdzają szum.
W teście FrontierSWE – benchmarku oceniającym, czy agent AI potrafi realizować otwarte projekty techniczne mierzone w godzinach, obejmujące optymalizację systemów, konstrukcję kodu na dużą skalę i badania w zakresie stosowanego ML, ocenianym wskaźnikiem dominacji – GLM-5.2 osiągnął 74.4 w porównaniu do 75.1 Claude Opus 4.8. Przewyższył GPT-5.5, które uzyskało 72.6. W SWE-bench Pro, który testuje autonomiczne rozwiązywanie rzeczywistych problemów GitHub ocenianych jako wskaźnik zaliczenia, GLM-5.2 uzyskał 62.1 wobec 58.6 GPT-5.5 – i znacznie przewyższył swojego poprzednika GLM-5.1 z wynikiem 58.4.
Ten skok jakości czyni go najlepszym dotychczasowym modelem open-source w Artificial Analysis Intelligence Index, który agreguje wyniki 9 różnych wskaźników do oceny ogólnej jakości modelu AI. Benchmarki OpenRouter umieszczają go w tej samej kategorii co obecnie zakazany Claude Fable 5.
Użyty sprzęt do osiągnięcia tego wyczynu to kolejna interesująca część historii. GLM-5.2 był trenowany na chipach Huawei Ascend – bez użycia sprzętu Nvidia w całym procesie. Emad Mostaque, założyciel Stability AI, oszacował całkowite koszty treningu na około 25 milionów dolarów, z czego 80% to koszty po treningu, co czyniłoby go niezwykle tanim w porównaniu do konkurencji.
Jak Decrypt donosiło wcześniej w tym roku, Z.ai już trenowało modele obrazów na serwerach Huawei Ascend Atlas bez ani jednego amerykańskiego chipa. GLM-5.2 rozwija tę infrastrukturę – to model typu mixture-of-experts z 744 miliardami parametrów i prawdziwym oknem kontekstowym na 1 milion tokenów, pięciokrotnie większym niż limit 200K w GLM-5.1, oraz licencją MIT, co oznacza, że żadne rządowe dyrektywy nie mogą zablokować dostępu.
Tokeny to fragmenty tekstu, które model może odczytywać i generować, natomiast Parametry to liczba wewnętrznych ustawień i wartości, które określają, jak model przetwarza informacje i generuje odpowiedzi.
Dla deweloperów, okno kontekstowe to zmiana operacyjna. Nawigacja po całym repozytorium, refaktoryzacja wielu plików i długie potoki agentowe, które wcześniej wymagały dzielenia na fragmenty, stają się przepływami pracy z pojedynczym wywołaniem. Ceny API wynoszą 1.40 USD za milion tokenów wejściowych i 4.40 USD za milion tokenów wyjściowych – w porównaniu do 5 USD za wejście i 25 USD za wyjście w Claude Opus 4.8. Plan kodowania zaczyna się od około 18 USD miesięcznie i działa bezpośrednio w Claude Code, Cline, Kilo Code oraz w większości popularnych środowisk agentowych.
Możliwe jest również lokalne wdrożenie. Unsloth AI wprowadziło 2-bitowe kwantyzacje GGUF, które kompresują model z 1.51 TB do 238 GB, zachowując jednocześnie około 82% dokładności.
Nie ekscytujcie się jednak zbytnio. Nadal oznacza to, że wymaga 256 GB zunifikowanej pamięci lub pasującej kombinacji RAM/VRAM – czyli maksymalnie wyposażonego Mac Studio M4 Ultra lub stacji roboczej ze średniej klasy GPU i 256 GB pamięci systemowej z odciążaniem mixture-of-experts. To nadal sporo pieniędzy, ale przynajmniej coś, co można kupić i uruchomić w domu, jeśli naprawdę się chce.
Przeprowadziliśmy szybki test, prosząc GLM-5.2 o zbudowanie naszej standardowej gry łączącej mechanikę pisania z elementami strzelanki. Interfejs użytkownika nie był najładniejszy – inne modele generowały bardziej dopracowane interfejsy, ale doświadczenie było najbardziej zróżnicowane: różne scenariusze w kolejnych falach, zmieniające się typy wrogów, bossowie pojawiający się później w grze.
Generowało to bardziej zróżnicowane stany gry niż cokolwiek innego, co testowaliśmy dla tego samego zadania w konfiguracji zero-shot.
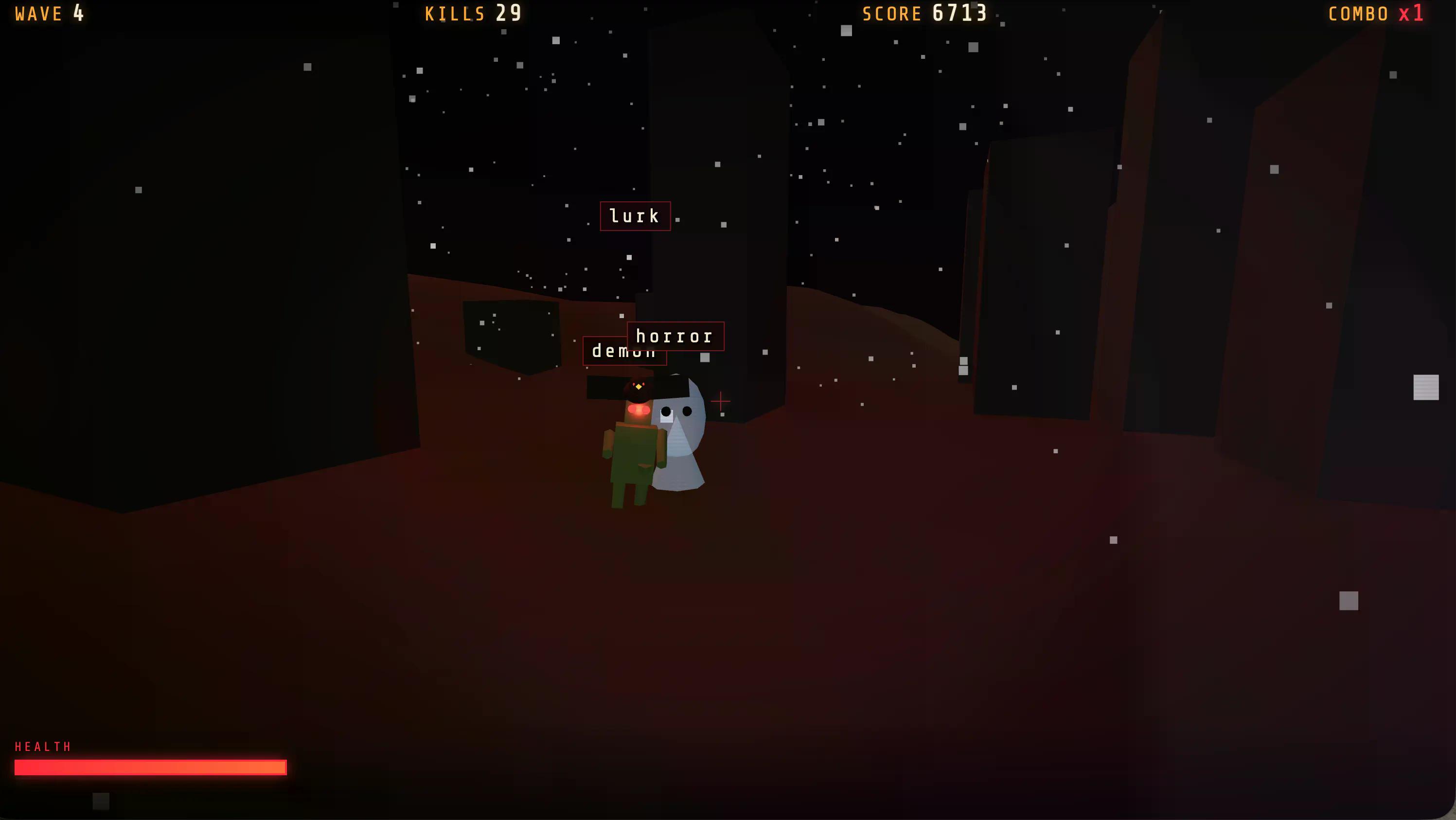
Jeśli chcesz w nią zagrać, jest dostępna na naszym profilu Itch.io.
Ta zmienność wskazuje, gdzie GLM-5.2 ma największy sens ekonomiczny. W przypadku przepływów pracy generowania wielokrotnych ujęć i potoków agentowych, gdzie różnorodność wyników ma większe znaczenie niż dopracowanie, argumentacja cenowa open-source jest trudna do podważenia. W przypadku najtrudniejszych długotrwałych zadań – SWE-Marathon, gdzie uzyskuje 13.0 punktów w porównaniu do 26.0 Opus 4.8 – luka do zamkniętej granicy jest nadal realna i wynosi 13 punktów.
Wagi open-source są dostępne na HuggingFace na licencji MIT. Kwantowane wagi są również dostępne na HuggingFace. Abonenci GLM Coding Plan mogą teraz przełączyć się na model o nazwie GLM-5.2, a także jest on dostępny do bezpłatnego testowania na z.AI z pewnymi ograniczeniami użytkowania.
