
Anthropic oddelegował około sześciu inżynierów do Agencji Bezpieczeństwa Narodowego (NSA), aby pomogli we wdrożeniu Mythos — swojego najbardziej zaawansowanego modelu sztucznej inteligencji — do ofensywnych operacji cybernetycznych, jak poinformował w czwartek Financial Times.
Inżynierowie ci to personel rozmieszczony na miejscu, dostosowujący model do konkretnych zastosowań. Jedno ze źródeł podało FT, że może on być użyteczny do infiltracji sieci w krajach takich jak Chiny i Iran.
Nie jest potwierdzone, czy ci inżynierowie są zaangażowani w aktywne operacje. Potwierdzony jest natomiast fakt, że Mythos to ten sam model, którego Anthropic odmówił publicznego udostępnienia, powołując się na ryzyko niewłaściwego użycia. Firma ograniczyła jego dostęp do zweryfikowanych partnerów w ramach Project Glasswing – ograniczonej koalicji, w skład której wchodzą Microsoft, Apple i Amazon.
Anthropic pozywa również Pentagon. Pod koniec lutego sekretarz obrony Pete Hegseth określił firmę jako zagrożenie dla łańcucha dostaw — etykietę historycznie zarezerwowaną dla zagranicznych przeciwników, takich jak Huawei — po tym, jak umowa o wartości 200 milionów dolarów upadła. Punktem spornym było to, że Anthropic odmówił zezwolenia Departamentowi Obrony na użycie Claude do w pełni autonomicznych broni lub masowej inwigilacji na terenie kraju. Umowa z NSA była wyłączona z tego zakazu.
Sąd w Kalifornii zablokował umieszczenie na czarnej liście jako widoczną retorsję naruszającą Pierwszą Poprawkę. Sąd apelacyjny Dystryktu Kolumbii odrzucił wniosek Anthropic o wstrzymanie tego działania w trakcie trwania procesu sądowego. Według doniesień FT, NSA przez cały czas kontynuowała korzystanie z Mythos.
Jak powstrzymać AI, która buduje AI
Tego samego dnia, w którym wybuchła historia z NSA, wewnętrzny instytut badawczy Anthropic opublikował "When AI Builds Itself" (Kiedy AI buduje siebie), analizę postępów Claude'a w automatyzacji własnego rozwoju. W niej firma opowiada się zasadniczo za globalnym moratorium w wyścigu zbrojeń AI — i nawet porównuje to do traktatów nuklearnych z czasów zimnej wojny zawartych między Stanami Zjednoczonymi a Rosją.
Aby zrozumieć dlaczego, firma podała następujący kontekst:
Claude pisze obecnie ponad 80% kodu włączanego do produkcyjnej bazy kodu Anthropic — w porównaniu do kilku procent przed uruchomieniem Claude Code na początku 2025 roku. Inżynierowie dostarczają około ośmiokrotnie więcej kodu dziennie niż w 2024 roku.
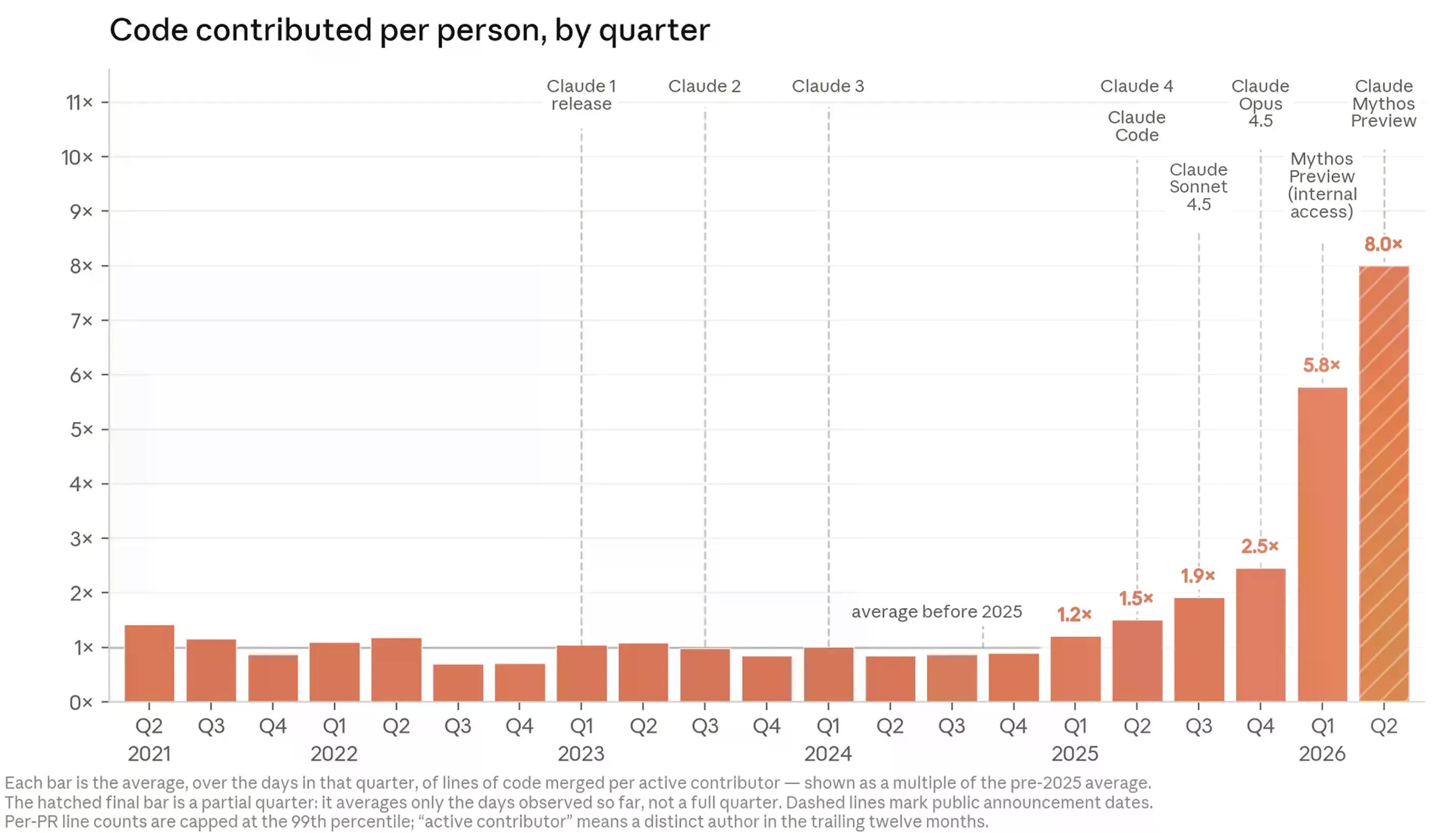
Autorzy raportu – Marina Favaro, liderka Anthropic Institute, i Jack Clark, współzałożyciel – argumentują, że ta trajektoria zmierza w kierunku tego, co nazywają rekurencyjnym samodoskonaleniem: systemów AI, które autonomicznie projektują, budują i trenują swoich własnych następców, przy zmniejszającej się roli ludzi na każdym etapie.
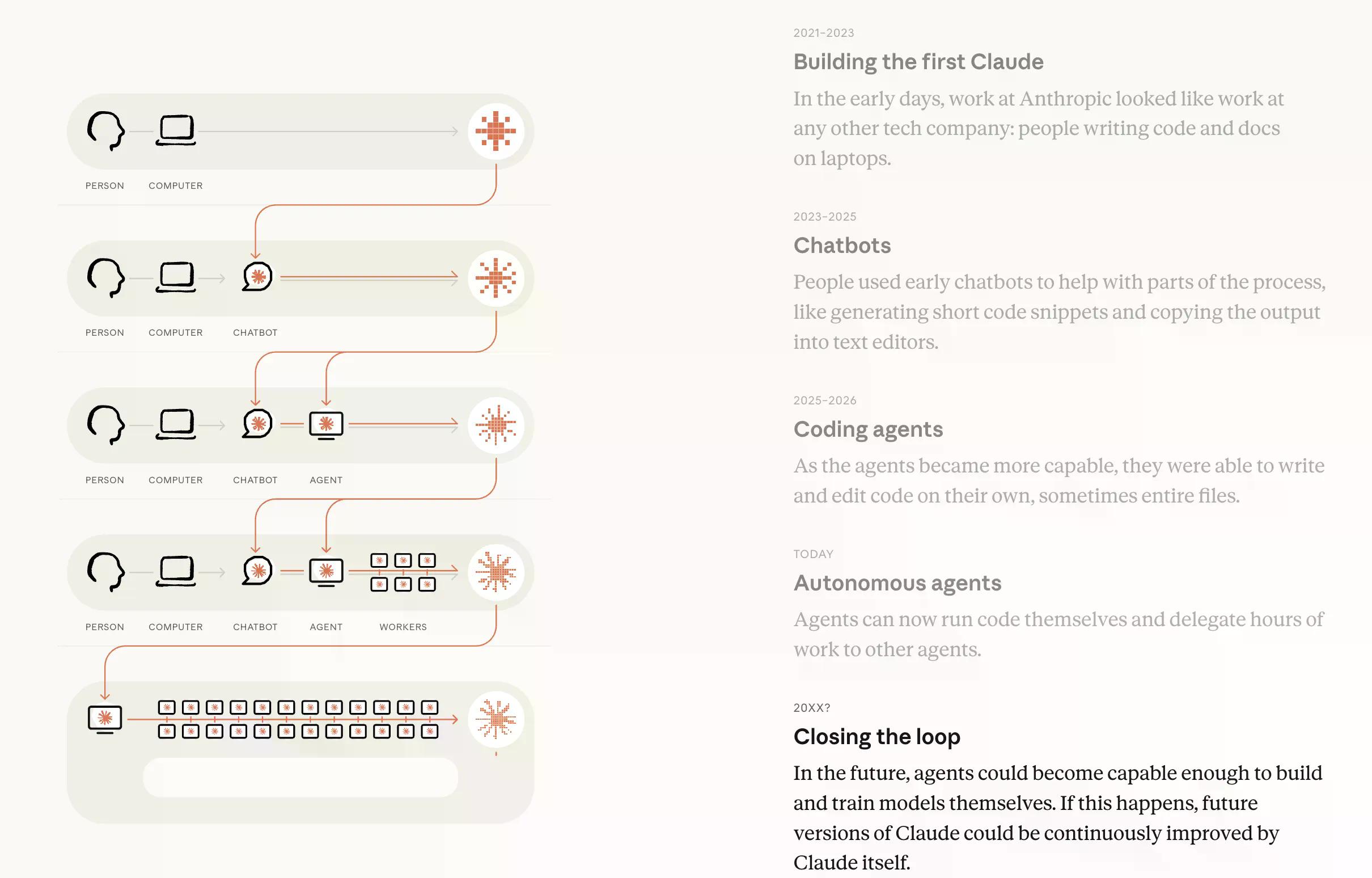
W wizualnej reprezentacji badacze przedstawiają oś czasu, na której pierwszą metodą wykorzystania AI w pracy jest zadawanie pytań komputerowi przez ludzi w celu uzyskania wyniku, z rosnącymi automatyzacjami kończącymi się na tym, że Agenci AI zadają pytania podagentom, aż do osiągnięcia wyniku, bez udziału ludzi.
Najostrzejszy punkt danych, na który się powołują: W kwietniu agentom Claude'a powierzono otwarty problem bezpieczeństwa AI — czy słabszy model może niezawodnie nadzorować silniejszy — i pozwolono mu działać. Dwóch ludzkich badaczy w ciągu około tygodnia odzyskało 23% luki w wydajności między modelami. Agenci odzyskali 97% w ciągu ponad 800 godzin kumulatywnej pracy obliczeniowej. Ludzie zadali pytanie. Agenci zaprojektowali każdy eksperyment. To pierwszy opublikowany przypadek, w którym Claude wykazał się zdolnością oceny badawczej, a nie tylko wykonywał zadania określone przez kogoś innego.
To jest granica, której Anthropic obawia się przekroczyć. Gdy AI zacznie wybierać, które eksperymenty są warte przeprowadzenia — a nie tylko je wykonywać — ludzie stracą ostatnią znaczącą rolę w pętli rozwojowej. Drobne niezgodności widoczne w dzisiejszych modelach mogą kumulować się w kolejnych, samodoskonalących się generacjach, aż nikt nie będzie w stanie ich skorygować.
Ich proponowanym rozwiązaniem jest weryfikowalna globalna pauza — wiele wiodących laboratoriów zatrzymujących się jednocześnie, z niezależną weryfikacją, że wszyscy faktycznie się zatrzymali. Anthropic oświadczył, że dołączy do takiej inicjatywy. Jednostronne spowolnienie, jak przyznają, tylko odda przewagę temu, kto będzie kontynuował prace.
Widzieliśmy już ten film. Laboratoria tworzące AI to te same, które ostrzegają przed jej niebezpieczeństwem. Jednak AI to najbardziej dochodowy biznes dekady, więc nikt nie chce się zatrzymać — nawet ci, którzy ostrzegają przed AI.
W 2023 roku ponad stu znanych przedstawicieli społeczności badającej AI podpisało list otwarty wzywający do globalnych wysiłków w celu złagodzenia ryzyka wyginięcia, które z natury niesie ze sobą rozwój AI. Kilka miesięcy wcześniej inny list otwarty domagał się od OpenAI wstrzymania prac nad ChatGPT ze względu na jego niebezpieczny charakter.
Nikt się nie zatrzymał po liście otwartym z 2023 roku. OpenAI tego nie zrobiło. Anthropic również nie. Termin Pentagonu na usunięcie Claude’a z jego systemów przypada na sierpień, w mniej więcej tym samym czasie, gdy oczekuje się, że IPO Anthropic ujawni jego finanse opinii publicznej.
