
جنسن هوانگ، مدیرعامل انویدیا، هفته گذشته در پادکست لکس فریدمن گفت: "فکر میکنم ما به AGI (هوش عمومی مصنوعی) دست یافتهایم." دو روز بعد، سختگیرانهترین آزمایش در تحقیقات هوش مصنوعی، جدیدترین معیار هوش عمومی مصنوعی خود را منتشر کرد—و هر مدل پیشرو کمتر از 1% امتیاز کسب کرد.
بنیاد ARC Prize این هفته ARC-AGI-3 را منتشر کرد و نتایج بیرحمانه بود. Gemini 3.1 Pro گوگل با 0.37% پیشتاز بود. GPT-5.4 اوپنایآی با 0.26% و Claude Opus 4.6 انتروپیک با 0.25% در ردههای بعدی قرار گرفتند، در حالی که Grok-4.20 متعلق به xAI دقیقاً صفر امتیاز آورد. در همین حال، انسانها 100% محیطها را حل کردند.
این یک آزمون اطلاعات عمومی یا امتحان کدنویسی نیست، حتی سوالات فوقالعاده دشوار در سطح دکترا هم نیست. ARC-AGI-3 چیزی کاملاً متفاوت از هر آن چیزی است که صنعت هوش مصنوعی تاکنون با آن روبرو بوده است.
این معیار توسط بنیاد فرانسوا شوله و مایک نوپ ساخته شده است که یک استودیوی بازی داخلی راهاندازی کرده و 135 محیط تعاملی اصلی را از پایه ایجاد کردند. ایده این است که یک عامل هوش مصنوعی را در یک دنیای بازیمانند ناآشنا، بدون هیچ دستورالعملی، بدون اهداف مشخص و بدون توصیف قوانین، رها کنیم. این عامل باید کاوش کند، بفهمد چه کاری باید انجام دهد، یک برنامه ریزی کند و آن را اجرا نماید.
اگر این کار به نظر کاری میآید که یک کودک پنج ساله نیز میتواند انجام دهد، پس تازه دارید مشکل را درک میکنید. اگر میخواهید ببینید آیا از هوش مصنوعی بهتر هستید، میتوانید با کلیک روی این لینک، همان بازیهای موجود در این تست را انجام دهید. ما یکی را امتحان کردیم؛ در ابتدا عجیب بود، اما پس از چند ثانیه، به راحتی میتوانید با آن آشنا شوید.
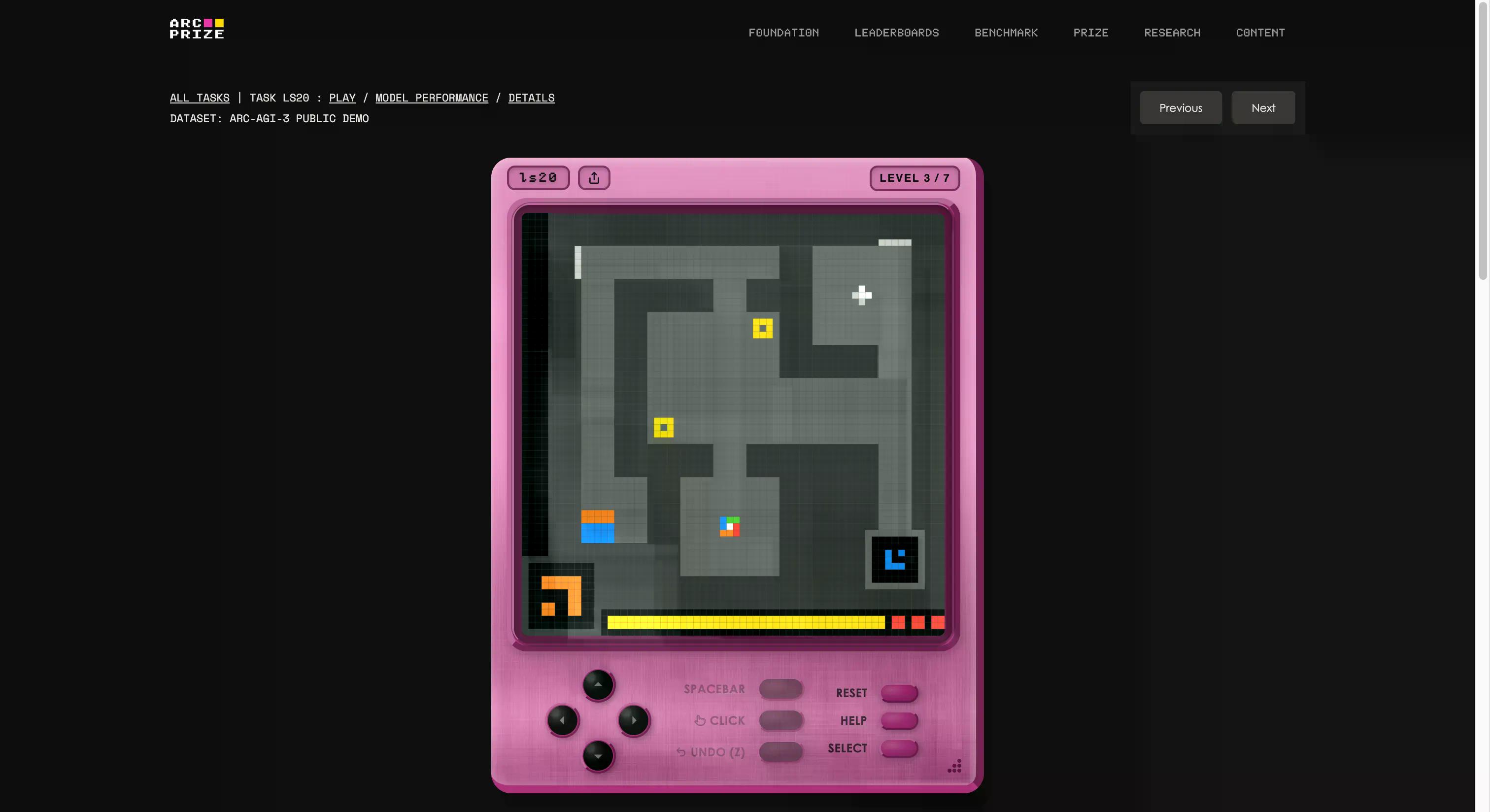
این همچنین روشنترین نمونه از معنای "G" در AGI است. وقتی شما تعمیم میدهید، میتوانید دانش جدیدی (نحوه کار یک بازی عجیب) را بدون اینکه از قبل روی آن آموزش دیده باشید، ایجاد کنید.
نسخههای قبلی ARC پازلهای بصری ایستا را آزمایش میکردند—یک الگو را نشان بدهید، الگوی بعدی را پیشبینی کنید. در ابتدا دشوار بودند. سپس آزمایشگاهها قدرت محاسباتی و آموزش را به آنها تزریق کردند تا اینکه این معیارها عملاً از بین رفتند. ARC-AGI-1، که در سال 2019 معرفی شد، تسلیم آموزش در زمان آزمایش و مدلهای استدلال شد. ARC-AGI-2 حدود یک سال دوام آورد تا اینکه Gemini 3.1 Pro به 77.1% رسید. آزمایشگاهها در اشباع معیارهایی که میتوانند بر اساس آنها آموزش ببینند، بسیار خوب عمل میکنند.
نسخه 3 به طور خاص برای جلوگیری از این امر طراحی شده بود. با 110 محیط از 135 محیط که خصوصی نگه داشته شدهاند—55 مورد نیمهخصوصی برای آزمایش API، 55 مورد کاملاً قفلشده برای رقابت—هیچ مجموعه دادهای برای حفظ کردن وجود ندارد. شما نمیتوانید با زور منطق بازیهای جدیدی که هرگز ندیدهاید را حل کنید.
امتیازدهی نیز بر مبنای قبول/رد نیست. ARC-AGI-3 از چیزی استفاده میکند که بنیاد آن را RHAE — کارایی نسبی عملکرد انسانی — مینامد. معیار پایه، دومین عملکرد برتر انسانی در اولین تلاش است. یک هوش مصنوعی که ده برابر یک انسان عمل انجام میدهد، برای آن سطح 1% امتیاز میگیرد، نه 10%. این فرمول مجازات ناکارآمدی را به توان 2 میرساند. سرگردانی، بازگشت به عقب و حدس زدن برای رسیدن به پاسخ به شدت جریمه میشود.
بهترین عامل هوش مصنوعی در پیشنمایش یک ماهه توسعهدهندگان 12.58% امتیاز کسب کرد. مدلهای زبان بزرگ پیشرو که از طریق API رسمی و بدون ابزار سفارشی آزمایش شدند، نتوانستند به 1% برسند. انسانهای عادی هر 135 محیط را بدون آموزش قبلی و بدون دستورالعمل حل کردند. اگر این معیار باشد، پس نسل فعلی مدلها از پس آن بر نمیآیند.
یک بحث متدولوژیک واقعی در اینجا وجود دارد. گزارش ARC میگوید یک ابزار سفارشی ساخته شده توسط Duke، امتیاز Claude Opus 4.6 را از 0.25% به 97.1% در یک واریانت محیطی به نام TR87 رسانده است. این بدان معنا نیست که Claude در کل ARC-AGI-3 امتیاز 97.1% را کسب کرده است؛ امتیاز رسمی آن همچنان 0.25% باقی مانده، اما این تغییر هنوز قابل توجه است.
معیار رسمی، به عاملها کد JSON میدهد، نه تصاویر. این یا یک نقص روششناختی است یا نشان میدهد که مدلهای امروزی در پردازش اطلاعات دوستانه انسانی بهتر از دادههای ساختاریافته خام هستند. بنیاد شوله این بحث را تأیید کرده است، اما فرمت را تغییر نمیدهد.
در این مقاله آمده است: "ادراک محتوای فریم و فرمت API عوامل محدودکنندهای برای عملکرد مدلهای پیشرو در ARC-AGI-3 نیستند." به عبارت دیگر، آنها به نظر میرسد این ایده را رد میکنند که مدلها به این دلیل شکست میخورند که "نمیتوانند" وظایف را به درستی "ببینند"، بلکه استدلال میکنند که ادراک از قبل کافی است—و شکاف واقعی در استدلال و تعمیم نهفته است.
بررسی واقعیت AGI در هفتهای رخ داد که موتور تبلیغات با سرعت تمام کار میکرد. علاوه بر اظهارنظر هوانگ، آرم نام تراشه جدید مرکز داده خود را "AGI CPU" گذاشت. سم آلتمن از OpenAI گفته است که آنها "اساساً AGI ساختهاند" و مایکروسافت نیز از قبل یک آزمایشگاه متمرکز بر ساخت ASI (تکامل آنچه پس از دستیابی به AGI میآید) را بازاریابی میکند. به نظر میرسد این اصطلاح تا جایی کشیده میشود که هر آنچه از نظر تجاری راحت باشد را شامل شود.
موضع شوله سادهتر است. اگر یک انسان عادی بدون هیچ دستورالعملی بتواند کاری را انجام دهد، و سیستم شما نتواند، پس شما AGI ندارید—شما یک تکمیلکننده خودکار (autocomplete) بسیار گرانقیمت دارید که به کمک زیادی نیاز دارد.
ARC Prize 2026 مبلغ 2 میلیون دلار را در سه مسیر رقابتی ارائه میدهد که همگی در Kaggle میزبانی میشوند. هر راهحل برنده باید متنباز باشد. زمان در حال گذر است، و در حال حاضر، ماشینها حتی نزدیک هم نیستند.
