
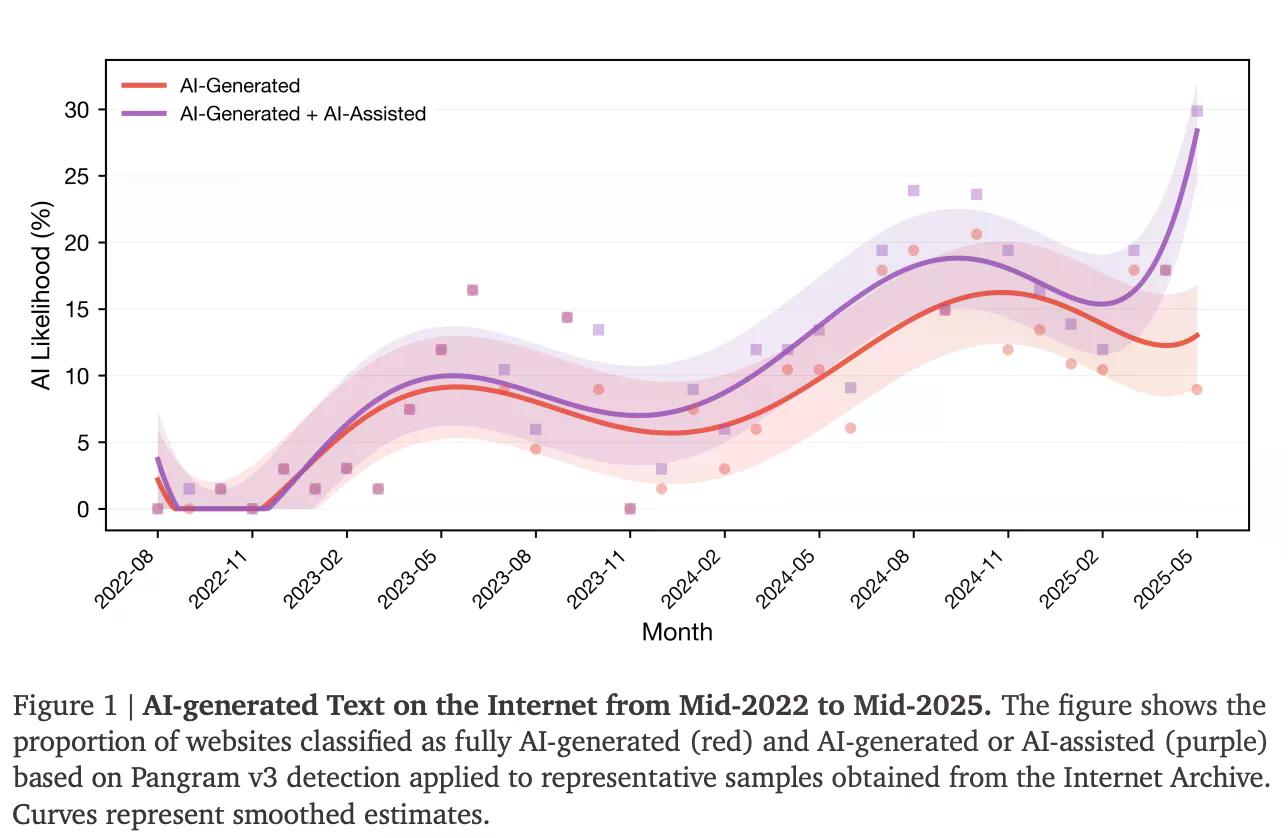
Eine neue Studie beziffert, wie viel des Internets mittlerweile KI-generiert ist: 35 %. Das ist der Anteil der neu veröffentlichten Websites, die laut einer Studie der Stanford University, des Imperial College London und des Internet Archive bis Mitte 2025 als KI-generiert oder KI-unterstützt eingestuft wurden. Diese Zahl lag vor dem Start von ChatGPT im November 2022 praktisch bei null.
"Die schiere Geschwindigkeit der KI-Übernahme des Webs finde ich ziemlich verblüffend", sagte Jonáš Doležal, Forscher am Imperial College London und Mitautor des Papiers, gegenüber 404 Media. "Nach Jahrzehnten, in denen Menschen es gestaltet haben, wird ein erheblicher Teil des Internets in nur drei Jahren von KI definiert."
Die Studie mit dem Titel „The Impact of AI-Generated Text on the Internet“ stützte sich auf 33 Monate Website-Snapshots aus der Wayback Machine des Internet Archive und nutzte einen KI-Texterkenner namens Pangram v3, um jede Seite zu klassifizieren.
Die bestätigten Schäden: Stimmungen, nicht Fakten
Die Forscher testeten sechs Hypothesen darüber, was KI-Inhalte mit dem Web anstellen. Nur zwei davon hielten der Datenprüfung stand.
Die erste: Wir werden zu einer Horde dummer NPCs, die sich auf dieselbe Weise verhalten… Oder wissenschaftlicher ausgedrückt, das Web wird semantisch weniger divers.
KI-generierte Websites zeigten paarweise semantische Ähnlichkeitswerte, die 33 % höher waren als die von Menschen verfassten. Dieselben Ideen werden immer wieder auf nahezu die gleiche Weise ausgedrückt.
Das Papier deutet darauf hin, dass sich das Online-Overton-Fenster verengen könnte, nicht durch Zensur oder koordinierte Kampagnen, sondern weil Sprachmodelle ihre Ausgaben an die Nähe ihrer Trainingsverteilung optimieren.
Die zweite: Das Web wird aggressiv fröhlich.
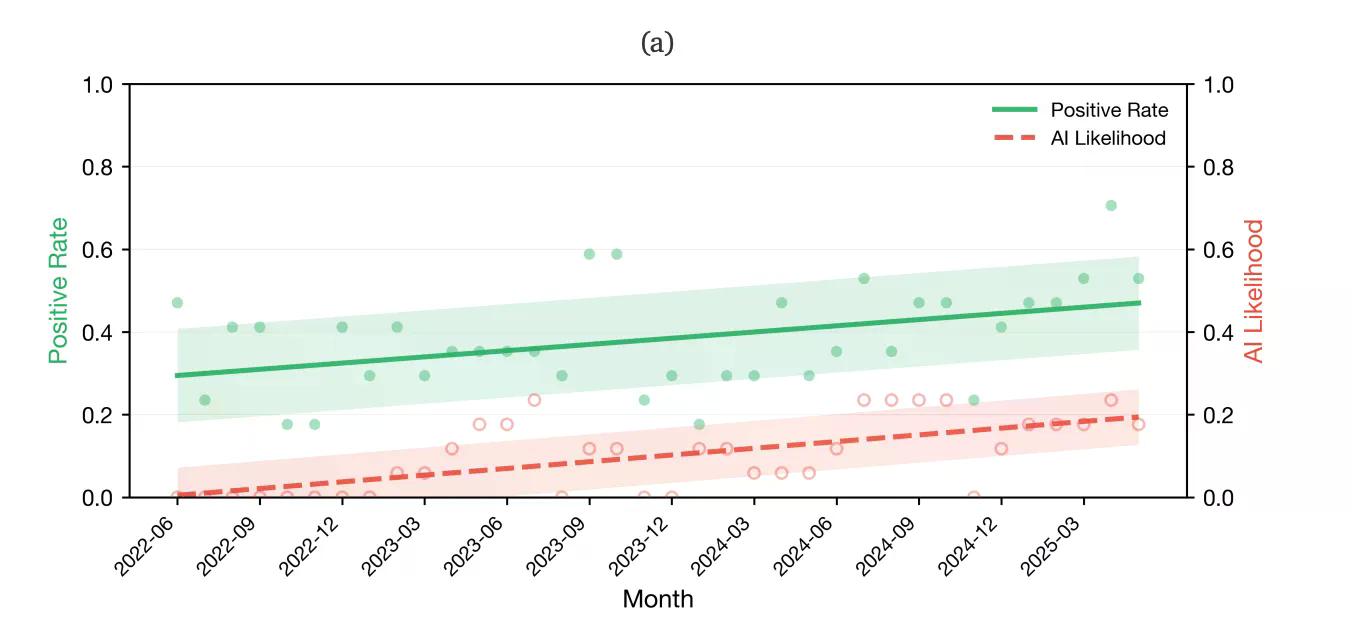
KI-Inhalte zeigten positive Stimmungsbewertungen, die über 107 % höher waren als menschliche Inhalte. Forscher führen dies auf die gut dokumentierten sycophantischen Tendenzen von LLMs zurück – trainiert auf menschliche Zustimmungssignale, produzieren sie Texte, die sich bereinigt, reibungslos und unerbittlich optimistisch anfühlen.
Ein Internet, das mit fröhlichen, homogenisierten Inhalten überflutet ist, könnte menschliche Meinungsverschiedenheiten in großem Maßstab marginalisieren, ohne dass jemand einen Hebel betätigt.
Entgegen der weit verbreiteten öffentlichen Meinung fand die Studie keine statistisch signifikanten Beweise dafür, dass KI-Inhalte das Internet weniger sachlich korrekt machen. Die Forscher fanden keine aussagekräftige Korrelation zwischen der KI-Verbreitung und der Rate sachlicher Fehler.
Die Hypothese der stilistischen Monokultur – dass KI individuelle Stimmen in ein generisches, einheitliches Register presst – war die Überzeugung, die die Befragten am stärksten vertraten (83 % stimmten zu). Die Daten bestätigten dies jedoch nicht. Eine zeichenbasierte Analyse ergab keinen statistisch signifikanten Anstieg der stilistischen Homogenität, der mit der KI-Verbreitung zusammenhängt.
Die größeren Einsätze gehen über die Qualität des Diskurses hinaus. Bei einer KI-Verbreitung von 35 % verschiebt sich das theoretische Risiko des Modellkollapses – bei dem zukünftige Modelle nach dem Training mit KI-generierten Daten degenerieren – von einer akademischen Sorge zu einer empirischen Realität. Zukünftige Grundmodelle, die auf zeitgenössischen Web-Crawls trainiert werden, werden unweigerlich Daten aufnehmen, die substanziell KI-generiert und messbar weniger semantisch divers sind.
Das Team arbeitet nun mit dem Internet Archive zusammen, um die Studie in ein kontinuierliches, Live-Überwachungstool umzuwandeln, das den Anteil der KI am Web in Echtzeit verfolgt, anstatt nur eine einmalige Momentaufnahme zu liefern.
Eine gleichzeitig mit der Studie durchgeführte US-Umfrage ergab, dass die meisten Amerikaner bereits alle sechs negativen Hypothesen glauben, einschließlich derer, die die Daten nicht stützen. Personen, die KI selten nutzen, glaubten mit 12 % höherer Wahrscheinlichkeit an die Schäden als häufige Nutzer. Anhänger der Dead Internet Theory, hier sind die Daten: Das Internet ist nicht tot, aber 35 % des Neuen ist wahrscheinlich in gewisser Weise Zombie-Inhalt.